区域和可用区
什么是区域、可用区?
我们用区域和可用区来描述数据中心的位置,您可以在特定的区域、可用区创建资源。
区域(Region)指物理的数据中心。每个区域完全独立,这样可以实现最大程度的容错能力和稳定性。资源创建成功后不能更换区域。
可用区(AZ,Availability Zone)是同一区域内,电力和网络互相隔离的物理区域,一个可用区不受其他可用区故障的影响。一个区域内可以有多个可用区,不同可用区之间物理隔离,但内网互通,既保障了可用区的独立性,又提供了低价、低时延的网络连接。
图阐明了区域和可用区之间的关系。
区域和可用区
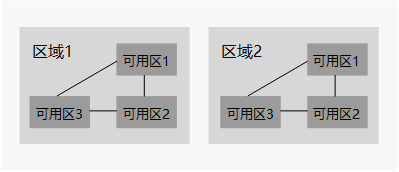
如何选择区域?
建议就近选择靠近您或者您的目标用户的区域,这样可以减少网络时延,提高访问速度。
如何选择可用区?
是否将资源放在同一可用区内,主要取决于您对容灾能力和网络时延的要求。
如果您的应用需要较高的容灾能力,建议您将资源部署在同一区域的不同可用区内。
如果您的应用要求实例之间的网络延时较低,则建议您将资源创建在同一可用区内。
什么是数据库复制
数据复制服务(Data Replication Service,简称DRS)是一种易用、稳定、高效、用于数据库实时迁移和数据库实时同步的云服务。
数据复制服务围绕云数据库,降低了数据库之间数据流通的复杂性,有效地帮助您减少数据传输的成本。
您可通过数据复制服务快速解决多场景下,数据库之间的数据流通问题,以满足数据传输业务需求。
实时迁移
实时迁移是指在数据复制服务器能够同时连通源数据库和目标数据库的情况下,只需要配置迁移的源、目标数据库实例及迁移对象即可完成整个数据迁移过程,再通过多项指标和数据的对比分析,帮助确定合适的业务割接时机,实现最小化业务中断的数据库迁移。
实时迁移支持多种网络迁移方式,如:公网网络、VPC网络、VPN网络和专线网络。通过多种网络链路,可快速实现跨云平台数据库迁移、云下数据库迁移上云或云上跨区域的数据库迁移等多种业务场景迁移。
特点:通过增量迁移技术,能够最大限度允许迁移过程中业务继续对外提供使用,有效的将业务系统中断时间和业务影响最小化,实现数据库平滑迁移上云,支持全部数据库对象的迁移。
备份迁移
由于安全原因,数据库的IP地址有时不能暴露在公网上,但是选择专线网络进行数据库迁移,成本又高。这种情况下,您可以选用数据复制服务提供的备份迁移,通过将源数据库的数据导出成备份文件,并上传至对象存储服务,然后恢复到目标数据库。备份迁移可以帮助您在云服务不触碰源数据库的情况下,实现数据迁移。
常用场景:云下数据库迁移上云。
特点:云服务无需碰触源数据库,实现数据迁移。
实时灾备
为了解决地区故障导致的业务不可用,数据复制服务推出灾备场景,为用户业务连续性提供数据库的同步保障。您可以轻松地实现云下数据库到云上的灾备、跨云平台的数据库灾备,无需预先投入巨额基础设施。
数据灾备支持两地三中心、两地四中心灾备架构。
数据库复制服务是否支持关系型数据库的HA实例迁移
数据复制服务的高可用性保障机制,可以支持关系型数据库的单实例和HA实例的迁移。针对HA实例的迁移,DRS的自动重连技术在连接短暂中断后连接可以得到修复,断点续传技术,根据数据库内部连续性标志可以确保实时同步的连续性和一致性。
源数据库的HA设计,满足浮动IP连接效果,且倒换时RPO=0,则DRS完全支持数据库的HA实例迁移,无需人工介入。
源数据库的HA设计,不能满足浮动IP连接且倒换时RPO=0时,存在以下几种情况:
使用浮动IP,但不能保证倒换时RPO=0时,可以连接,但DRS会识别出数据断层(如果有主备倒换出现数据丢失的话)并提示任务失败,此时只能根据新的数据情况,使用重置功能重新迁移。
使用固定IP,且倒换时RPO=0时,支持迁移(只有在实例正常运行的情况下支持迁移,否则不支持)。
使用固定IP,且不能保证切换时RPO=0时, 可以连接,但DRS会识别出数据断层并提示任务失败,此时只能根据新的数据情况,使用重置功能重新迁移。
出云迁移且目标端数据库为HA实例时,DRS可以保证源的数据完整的迁移到目标数据库,但由于目标数据库本身的倒换不能保证RPO=0,则目标数据库可能会出现数据断层的情况。
DRS支持断点续传吗?
针对数据库的迁移场景,在迁移过程中由于不可抗拒因素(例如网络波动)导致的任务失败,DRS通过记录当前解析和回放的位点(该位点同时也是数据库内部一致性的依据),下次从该位点开始回放的方式来实现断点续传,以确保数据的完整性。
增量阶段的迁移,DRS会自动进行多次断点续传的重试,全量阶段的MySQL迁移,系统默认进行三次自动续传,无需人工干预。当自动重试失败累计一定次数后,任务会显示异常,需要人为根据日志来分析无法继续的原因,并尝试解决阻塞点(例如数据库修改了密码),如果环境无法修复,如所需日志已经淘汰,则使用重置功能可以完全重新开始任务。
实时迁移和同步有什么区别
| 对比项 | 实时迁移 | 实时同步 |
|---|---|---|
| 适用场景 | 跨云平台数据库迁移、云下数据库迁移上云或云上跨区域的数据库迁移等多种业务场景迁移。 | 实时分析,报表系统,数仓环境等。 |
| 特点 | 以整体数据库搬迁为目的,通过增量迁移技术,最大限度允许迁移过程中业务继续对外提供使用,有效的将业务系统中断时间和业务影响最小化,实现数据库平滑迁移上云,支持全部数据库对象的迁移。 | 维持不同业务之间的数据持续性流动,聚焦于表和数据,并满足多种灵活性的需求,例如多对一、一对多,动态增减同步表,不同表名之间同步数据等。 |
| 功能特性 | 详情请参见 实时迁移。 | 详情请参见实时同步。 |
DRS出现数据膨胀怎么办
DRS在全量迁移阶段,为了保证迁移性能和传输的稳定性,采用了行级并行的迁移方式。当源端数据紧凑情况下,通过DRS迁移到云上RDS for MySQL后,可能会出现数据膨胀现象,使得磁盘空间使用远大于源端。针对这种情况,客户可选择在目标库中执行以下命令,进行优化整理从而缩小空间。
optimize table table_name
由于命令optimize会进行锁表操作,所以进行优化时要避开表数据操作时间,避免影响正常业务的进行。
DRS为什么不能选择RDS只读实例
DRS不支持在界面直接选择RDS只读实例,用户可通过选择自建后输入只读实例IP和端口的方式进行连接。
DRS对数据库和目标数据库有什么影响
DRS对源数据库的压力及影响
全量(初始化)阶段,DRS需要从源库将所有存量数据查询一次。DRS查询使用简单SQL语句,对源库影响主要体现在IO上,查询速度也受限于源数据库IO相关的性能以及网络带宽。一般在网络无瓶颈的情况下,会对源数据库增加约50MB/s的查询压力,以及占用2~4个CPU,在并发读取源数据库时,会占用大约6-10个session连接数,其中:
- 有小于8个连接查询源数据库的一些系统表(如information_schema库下的表信息tables,视图信息views、列信息columns等);
- 有小于4个连接查询源数据库数据分片的SQL,类似如下语句,其中select和where后的条件只会有主键或者唯一键。
select id from xxx where id>12345544 and limit 10000,1;
- 有小于4个连接查询数据的SQL,类似如下语句,其中select后为表所有的列名,where后的条件只会有主键或者唯一键。
select id,name,msg from xxx where id>12345544 and id<=12445544;
- 无主键表的锁表操作SQL,类似如下语句,锁表只是为了获取无主键表的一致性位点,锁表后获取一个连接就会解锁。
flush table xxx with read lock
lock table xxx read
增量阶段对源数据库基本无压力,只有一个dump连接实时监听binlog增量。
DRS对目标数据库的压力及影响
全量(初始化)阶段,DRS需要将源数据库结构、索引以及存量数据全部写入到目标数据库,顺序为先迁移结构,再迁移数据,最后加索引,一般总连接数小于16个session,其中:
- 有小于8个连接在批量创建结构。
- 有小于8个连接在批量写数据,类似如下语句:insert into xxx (id,name,msg) valus (xxx);
- 有小于8个连接在批量创建索引,类似如下语句:
alter table xxx add index xxx;
增量阶段,DRS会把源数据库binlog中的增量数据解析成SQL在目标数据库中执行,一般总连接数小于64个session,其中:
- DDL会串行执行,执行DDL时,不会有其他DML执行。
- DML最多会有64个连接(短连接,超时时间30秒),其中DML只是简单的insert、update、delete、replace语句。
如果需要评估对源数据库的影响,可选择创建测试任务,再通过限速功能或业务低峰期动等来调整迁移策略。

