STREAM 是一个专门用于测量系统内存带宽性能的基准测试工具,它主要关注于评估在大规模数据移动(主要是向量操作)时,系统内存的实际数据传输速率。下面从三个方面对 STREAM 进行详细介绍:
1. 简介
STREAM 的主要目的是衡量内存系统的可持续带宽,即在执行简单向量运算时,内存子系统能达到的最高数据传输速率。它特别适合评估内存密集型应用在不同硬件platform下的表现。
- 轻量级且高效:STREAM 采用简单的向量操作,易于理解并且执行效率极高。
- 标准化测试:它为不同系统提供了一个标准化的比较基准,可以用来比较不同硬件platform间的内存性能。
- 易于移植:由于其简单性,STREAM 可以很容易地在多种编译器和操作系统上编译运行。
2. 测试内容
STREAM 主要包含四个基本的向量操作,每个操作都代表了一类常见的内存访问模式:
- Copy
复制操作:将一个向量中的数据复制到另一个向量。例如:a[i]=b[i]
该操作主要测试内存读写的连续性和带宽。
- Scale
标量乘法:对向量中的每个元素乘以一个标量。例如:a[i]=scalar×b[i]
此测试既涉及内存读操作,也涉及写操作,同时增加了乘法运算的计算量。
- Add
向量加法:对两个向量的对应元素进行加法运算。例如:a[i]=b[i]+c[i]
此操作测试的是内存同时从两个不同位置读数据,然后写入结果的能力。
- Triad
三元操作(加乘操作):结合了标量乘法和向量加法。例如:a[i]=b[i]+scalar×c[i]
这是一个更复杂的内存操作测试,既考察内存访问效率,又考察基本的算术运算效率。
这些测试操作的共同特点是,它们在大数据量下执行,能够充分体现内存带宽的瓶颈。
3. 测试方法
编译参数详解
gcc -mtune=native -g -march=native -O3 -fno-tree-loop-vectorize -DNTIMES=100 -ffp-contract=fast -mcmodel=large -fopenmp -DSTREAM\_ARRAY\_SIZE=80000000 stream.c --static -o stream
- -mtune=native
告诉编译器针对当前 CPU 进行调优,从而使生成的代码能充分利用本机处理器的特性,达到更好的运行性能。
- -g
在编译时包含调试信息。这有助于在程序出现问题时使用调试工具(如 gdb)进行排查和定位错误。
- -march=native
指定编译器生成适用于当前主机 CPU 指令集的代码。这样可以启用所有本机支持的指令扩展,进一步提升性能。
- -O3
使用最高级别的优化,编译器会进行各种高级优化手段,以期生成运行速度更快的代码。对于性能测试类程序(如 STREAM),此选项有助于发挥硬件的最大潜能。
- -fno-tree-loop-vectorize
禁用编译器的自动向量化优化。虽然向量化通常能加速数据并行计算,但在一些场景下(例如为了评估纯内存带宽而不受 SIMD 优化影响时)禁用向量化可能更符合测试需求。
- -DNTIMES=100
使用预处理器宏定义 NTIMES 为 100,意味着每个测试(如 Copy、Scale、Add、Triad)将执行 100 次迭代。足够多的迭代次数有助于降低偶然因素对测试结果的影响,从而获得更稳定和准确的带宽测量数据。
- -ffp-contract=fast
允许编译器进行快速浮点数运算合并(如 FMA 合并),从而在保证精度要求允许的前提下,提高计算效率。
- -mcmodel=large
指定使用大内存模型。这对于测试过程中使用大数组(例如 8 亿个元素)是必要的,因为它确保编译器能够正确处理超过默认地址空间限制的大内存分配。
- -fopenmp
启用 OpenMP 支持,以便利用多线程并行处理。STREAM 测试常常在多核platform上进行并行计算,使用该选项能够更真实地反映系统的内存带宽性能。
- -DSTREAM_ARRAY_SIZE=80000000
定义了 STREAM 测试中的数组大小为 80,000,000。通过增加数组的规模,可以使测试数据量充足,从而减小缓存效应的影响,更准确地衡量内存系统的实际带宽能力。
- --static
静态链接所有库,生成一个可执行文件。这种方式减少了运行时对动态库的依赖,有助于测试在不同系统环境中的一致性。
运行测试
设置OpenMP的环境变量
export OMP_PLACES=cores OMP_NUM_THREADS=$n_core OMP_PROC_BIND=true
- OMP_PLACES=cores
- 作用:指定 OpenMP 运行时将线程分配到物理核心(而非超线程中的虚拟核心)。
- 意义:减少线程对同一物理核心资源的竞争,提升并行程序的性能和稳定性。
- OMP_NUM_THREADS=$n_core
- 作用:设置 OpenMP 使用的线程总数,通常等于物理核心数($n_core 为核心数变量)。
- 意义:确保线程与物理核心一一对应,最大化资源利用率,防止线程过多导致的上下文切换开销。
- OMP_PROC_BIND=true
- 作用:将线程绑定到指定物理核心,禁止运行过程中迁移。
- 意义:减少线程切换核心的开销,提高数据局部性和缓存命中率,从而优化程序性能。
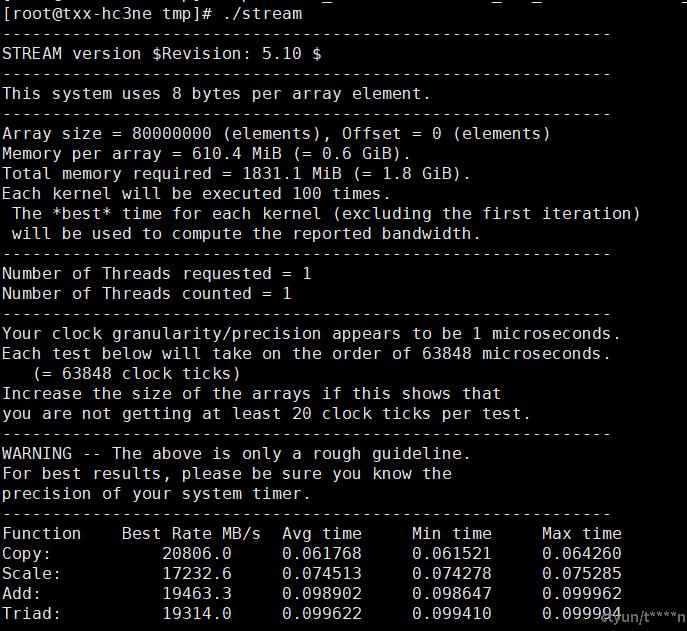
执行程序
./stream