


这就引出了一个问题:“RCU究竟是什么?”,这个问题将从使用者的角度在这个文档中得到解答。由于RCU最常用于替换某些现有的机制,我们主要从它与这些机制的关系方面来看待它,如下所示:
● RCU是读-写锁的替代品。
● RCU是一种受限的引用计数机制。
● RCU是一种批量引用计数机制。
● RCU是一个简陋的垃圾收集器。
● RCU是一种提供存在保证的方法。
● RCU是一种等待事情完成的方式。
这些部分之后是结论以及对快速问答的答案。
RCU是读-写锁的替代品
在Linux内核中,RCU最常见的用途之一是在读操作密集的情况下作为读-写锁的替代品。然而,一开始我并没有立刻意识到RCU的这种用途。实际上,在20世纪90年代初期,在实现通用目的的RCU实现之前,我选择了实现类似于brlock的东西。我为proto-brlock原语设想的每一个用途最终都是通过RCU来实现的。事实上,超过三年proto-brlock原语才被首次使用。那时,我真的觉得自己很愚蠢!
RCU与读-写锁之间的关键相似之处在于两者都有可以并行执行的读侧临界区。实际上,在某些情况下,可以用RCU API成员机械地替换对应的读-写锁API成员。但是首先,为什么要这样做呢?
RCU的优势包括性能、死锁抵抗以及实时延迟。当然,RCU也有其局限性,包括读者和写者可以并发运行的事实,低优先级的RCU读者可能会阻塞等待宽限期结束的高优先级线程,以及宽限期延迟可能延伸至许多毫秒。这些优势和限制将在以下部分中讨论。
性能
以下图表展示了在一台16核3GHz Intel x86系统上,RCU相比读-写锁在读侧性能上的优势。

注意,在单个CPU上,读-写锁比RCU慢几个数量级,在16个CPU上,其性能差距更是几乎多了两个数量级。相比之下,RCU的扩展性非常好。在这两种情况下,误差线在任一方向上延申一个标准差。
快速问答1:什么?怎么能让我不怀疑在3GHz时钟周期超过300皮秒的情况下,RCU的开销只有100飞秒?
一个更为中立的观点可以从配置了CONFIG_PREEMPT的内核中获得,尽管RCU在性能上仍然比读-写锁高出一到三个数量级。注意,在CPU数量较多时读-写锁的高变异性。误差线在任一方向上跨越一个标准差。
图表显示,RCU的读侧原语运行速度比读写锁的原语快多个数量级。
当然,随着临界区开销的增加,读-写锁的低性能问题将变得不那么显著,如下图所示为16核系统的示例。
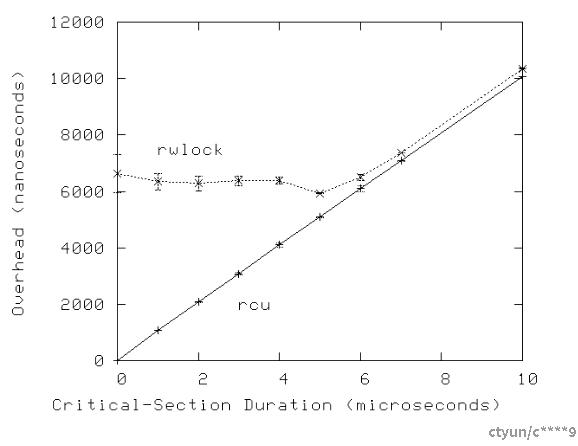
然而,这一观察结果必须考虑到一个事实,即许多系统调用(以及它们所包含的任何RCU读侧临界区)可以在几微秒内完成。此外,正如下一节将要讨论的,RCU读侧原语几乎完全抵抗死锁。
快速问答2:为什么随着临界区开销的增加,读-写锁(rwlock)的变异性及开销会减少?
死锁抵抗
尽管RCU为读多写少的工作场景提供了显著的性能优势,但最初创建RCU的一个主要原因实际上是它的读侧死锁抵抗性。这种抵抗性源于RCU读侧原语不会阻塞、自旋,甚至不做反向分支的事实,因此它们的执行时间是确定的。因此,它们不可能参与到一个死锁循环中。
RCU读侧死锁抵抗的一个有趣结果是,可以无条件地将RCU读者升级为RCU写者。如果尝试使用读-写锁进行类似的升级,则会导致死锁。以下是一个执行从RCU读取到更新升级的示例代码片段:
1 rcu_read_lock();
2 list_for_each_entry_rcu(p, head, list_field) {
3 do_something_with(p);
4 if (need_update(p)) {
5 spin_lock(&my_lock);
6 do_update(p);
7 spin_unlock(&my_lock);
8 }
9 }
10 rcu_read_unlock();需要注意的是,do_update()函数是在锁的保护下以及RCU读侧保护下执行的。
另一个有趣的结果是RCU对死锁抵抗的同时,也对一大类优先级反转问题具有抵抗力。例如,低优先级的RCU读者不能阻止高优先级的RCU写者获取更新侧锁。同样地,低优先级的RCU写者也不能阻止高优先级的RCU读者进入RCU读侧临界区。
快速问答3:是否存在对这种死锁抵抗的例外情况,如果存在,什么样的事件序列可能导致死锁?
实时延迟
由于RCU读侧原语既不自旋也不阻塞,它们提供了极佳的实时延迟。此外,如前所述,这意味着它们对涉及RCU读侧原语和锁的优先级反转抵抗。
然而,RCU仍然可能遇到更微妙的优先级反转场景。例如,在实时(-rt)内核中,一个高优先级进程如果等待RCU宽限期结束而被阻塞,可能会被低优先级的RCU读者阻塞。这种情况可以通过使用RCU优先级提升来解决。
RCU读者和写者并发运行
由于RCU读者从不自旋或阻塞,且写者不受任何回滚或中止语义的影响,因此RCU读者和写者必须能够并发运行。这意味着RCU读者可能会访问陈旧的数据,甚至可能看到数据不一致的情况,这使得从读-写锁转换到RCU变得不那么简单。
然而,在相当多的情况下,不一致性和陈旧数据并不是问题。一个经典的例子是网络路由表。因为路由更新到达特定系统可能需要相当长的时间(几秒甚至几分钟),当更新到达时,系统已经有一段时间在错误的方向上发送数据包了。继续以错误的方式发送数据包额外的几毫秒通常不是问题。此外,由于RCU写者可以在不等待RCU读者完成的情况下进行更改,RCU读者实际上可能比batch-fair (reader-writer-locking)的读者更快地看到这些变化,如下图所示。
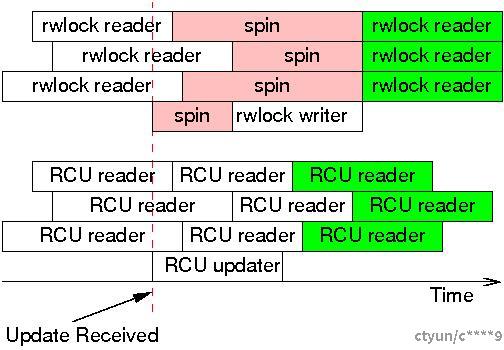
一旦更新被接收,读-写锁的写者不能继续进行,直到最后一个读者完成操作,并且后续的读者也不能继续,直到写者完成。然而,这些后续的读者被保证能看到新值,如绿背景所示。相比之下,RCU读者和写者不会互相阻塞,这允许RCU读者更快地看到更新后的值。当然,由于他们的执行与RCU写者的执行有重叠,所有的RCU读者很可能都会看到更新后的值,包括在更新开始前启动的三个读者。不过,只有那些具有绿背景的RCU读者被保证能看到更新后的值,再次以绿背景表示。
读-写锁和RCU提供了不同的保证。使用读-写锁,任何在写者开始执行后开始的读者都保证能看到新的值,而在写者自旋期间尝试开始的读者是否能看到新值取决于具体的读写锁实现的读者/写者偏好。相反,使用RCU,任何在更新完成后开始的读者都保证能看到新的值,而那些在更新开始之后结束的读者可能会也可能不会看到新的值,这取决于时机。
这里的关键点是,尽管读-写锁确实在计算机系统的范围内保证了一致性,但在某些情况下,这种一致性是以增加与外部世界不一致为代价的。换句话说,读-写锁通过牺牲对外部世界而言可能陈旧的数据的一致性来获得内部一致性。
然而,在某些情况下,系统内的不一致性和陈旧数据是不可容忍的。幸运的是,有一些方法可以规避这种不一致性和陈旧数据,正如在关于将RCU应用于FREENIX paper on applying RCU to System V IPC 和我的论文中讨论的那样。然而,深入讨论这些方法超出了本文的范围。
低优先级的RCU读者可能阻塞高优先级的回收者
在实时RCU、SRCU或QRCU中(每种 类型都在本系列的最后一部分中有描述),一个被抢占的读者会阻止宽限期完成,即使有高优先级的任务被阻塞等待该宽限期结束。实时RCU可以通过用call_rcu()替换synchronize_rcu()或者使用RCU优先级提升来规避这个问题,不过截至2007年末,RCU优先级提升仍处于实验性状态。对于SRCU和QRCU而言,可能也需要增加优先级提升功能,但这要等到明确的实际需求出现之后。
RCU宽限期可能会持续许多毫秒
除了QRCU之外,RCU宽限期通常会持续多个毫秒。虽然存在多种技术可以减轻这种长时间延迟带来的影响,包括在可用时使用异步接口(如call_rcu()和call_rcu_bh()),但这种情况是建议RCU主要用于读多写少场景的经验法则的一个重要原因。
读-写锁与RCU代码的比较
在最佳情况下,从读-写锁转换为RCU是非常简单的,如下例所示(该示例取自Wikipedia)。
1 struct el {
2 struct list_head list;
3 long key;
4 spinlock_t mutex;
5 int data;
6 /* Other data fields */
7 };
8 rwlock_t listmutex;
9 struct el head;
1 int search(long key, int *result)
2 {
3 struct list_head *lp;
4 struct el *p;
5
6 read_lock(&listmutex);
7 list_for_each_entry(p, head, lp)
8 if (p->key == key) {
9 *result = p->data;
10 read_unlock(&listmutex);
11 return 1;
12 }
13 }
14 read_unlock(&listmutex);
15 return 0;
16 }
1 int delete(long key)
2 {
3 struct el *p;
4
5 write_lock(&listmutex);
6 list_for_each_entry(p, head, lp)
7 if (p->key == key) {
8 list_del(&p->list);
9 write_unlock(&listmutex);
10 kfree(p);
11 return 1;
12 }
13 }
14 write_unlock(&listmutex);
15 return 0;
16 } 1 struct el {
2 struct list_head list;
3 long key;
4 spinlock_t mutex;
5 int data;
6 /* Other data fields */
7 };
8 spinlock_t listmutex;
9 struct el head;
1 int search(long key, int *result)
2 {
3 struct list_head *lp;
4 struct el *p;
5
6 rcu_read_lock();
7 list_for_each_entry_rcu(p, head, lp) {
8 if (p->key == key) {
9 *result = p->data;
10 rcu_read_unlock();
11 return 1;
12 }
13 }
14 rcu_read_unlock();
15 return 0;
16 }
1 int delete(long key)
2 {
3 struct el *p;
4
5 spin_lock(&listmutex);
6 list_for_each_entry(p, head, lp) {
7 if (p->key == key) {
8 list_del_rcu(&p->list);
9 spin_unlock(&listmutex);
10 synchronize_rcu();
11 kfree(p);
12 return 1;
13 }
14 }
15 spin_unlock(&listmutex);
16 return 0;
17 }更复杂的替换场景超出了本文档的讨论范围。
RCU是一种受限的引用计数机制
由于在有RCU读侧临界区正在进行时不允许宽限期完成,因此可以将RCU读侧原语用作一种受限的引用计数机制。例如,考虑以下代码片段:
1 rcu_read_lock(); /* acquire reference. */
2 p = rcu_dereference(head);
3 /* do something with p. */
4 rcu_read_unlock(); /* release reference. */ rcu_read_lock()原语可以被视为获取对p的引用,因为在rcu_dereference()赋值给p之后开始的任何宽限期都不可能结束,直到我们到达匹配的rcu_read_unlock()。这种引用计数方案是受限的,因为我们不允许在RCU读侧临界区内阻塞,也不允许将一个RCU读侧临界区从一个任务传递给另一个任务。
无论这些限制如何,下面的代码可以安全地删除p:
1 spin_lock(&mylock);
2 p = head;
3 head = NULL;
4 spin_unlock(&mylock);
5 synchronize_rcu(); /* Wait for all references to be released. */
6 kfree(p);对head的赋值操作阻止了未来对p的任何引用获取,并且synchronize_rcu()会等待之前已获取的所有引用被释放。
当然,RCU也可以与传统的引用计数结合使用,这已经在Linux内核邮件列表(LKML)中讨论过,并在《Overview of Linux-Kernel Reference Counting》一文中有总结。
快速问答4:但是等一下!这段代码与我们考虑将RCU作为读-写锁的替代品时使用的代码完全相同!这是怎么回事?
但是为什么要这样做呢?再次重申,部分答案在于性能的提升,如下图所示,该数据同样是在一个16核3GHz Intel x86系统上获取的。
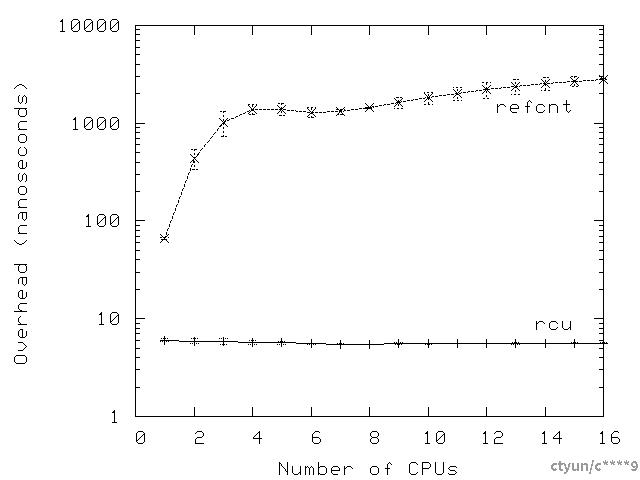
如同读-写锁一样,RCU的性能优势在短时间的临界区中最为显著,如下图所示为一个16核系统的示例。此外,与读-写锁类似,许多系统调用(以及它们所包含的任何RCU读侧临界区)可以在几微秒内完成。
快速问答5:为什么在接近6个CPU时,引用计数的开销会有一个下降?
然而,使用RCU时所附带的限制可能相当繁重。例如,在许多情况下,禁止在RCU读侧临界区内休眠会破坏整个目的。下一节将探讨解决这一问题的方法,同时在某些情况下也减少传统引用计数的复杂性。
RCU是一种批量引用计数机制
正如前一节所述,传统的引用计数器通常与特定的数据结构或一组数据结构相关联。然而,为大量不同的数据结构维护一个单一的全局引用计数器通常会导致包含引用计数的缓存行频繁跳跃,这种缓存行跳跃可能会严重降低性能。
相比之下,RCU的轻量级读侧原语允许极其频繁的读侧使用,且性能下降微乎其微,使得RCU可以用作“批量引用计数”机制,几乎没有性能损失。对于需要在一段可能阻塞的代码段中由单个任务持有引用的情况,可以通过可睡眠的RCU(Sleepable RCU, SRCU)来处理这种情况。但这未能涵盖一种不算少见的情况,即引用从一个任务传递给另一个任务,例如,当启动I/O操作时获取引用并在相应的完成中断处理程序中释放引用。(原则上,这可以通过SRCU实现来处理,但在实践中,是否这是一个好的权衡尚不清楚。)
当然,SRCU带来了它自己的限制,即srcu_read_lock()的返回值必须传递给对应的srcu_read_unlock()。关于这一限制带来的问题有多大以及如何最好地处理这个问题,目前还没有定论。
RCU是一种穷人的垃圾收集器
初次了解RCU的人常会感叹:“RCU有点像一个垃圾收集器!”这种感叹有一定的道理,但也有误导性。
理解RCU与自动垃圾收集器(GC)之间关系的最佳方式可能是:RCU类似于GC之处在于收集的时机是自动确定的,但RCU与GC的不同点在于:(1) 程序员必须手动指示某个数据结构何时可以被回收,以及 (2) 程序员必须手动标记那些可能持有引用的RCU读侧临界区。
尽管存在这些差异,两者之间的相似性确实相当深入,并且至少在一个理论分析中有所体现。此外,我所知的第一个类似RCU的机制实际上使用了垃圾收集器来处理宽限期。然而,更恰当的理解RCU的方式将在下文介绍。
RCU是提供存在保证的一种方式
Gamsa等人在其论文 gamsa中讨论了存在保证,并描述了一个类似于RCU的机制如何用于提供这些存在保证(参见第7页的第5节)。其效果是,如果在RCU读侧临界区内访问了任何受RCU保护的数据元素,则该数据元素在整个RCU读侧临界区期间都保证存在。
警觉的读者会认识到,这只是对最初的“RCU是一种等待事物完成的方式”主题的一个小变化,这将在下一节中详细讨论。
RCU是一种等待事物完成的方式
正如本系列第一篇文章中提到的,RCU的一个重要组成部分是等待RCU读操作完成的方法。RCU的一大优势在于它允许你等待成千上万的不同事物完成,而不需要显式地跟踪每一个事物,也不需要担心性能下降、可扩展性限制、复杂的死锁场景以及使用显式跟踪方案固有的内存泄漏风险。
在这一节中,我们将展示synchronize_sched()的读侧对应部分(包括任何禁用抢占的操作,以及禁用中断的硬件操作和原语)如何让你实现与NMI中断处理器的交互,如果使用锁定机制则会相当困难。在我的论文RCU dissertation 中,我将这种方法称为“纯粹RCU”,并且它在Linux内核的许多地方都有应用。
这种“纯粹RCU”设计的基本形式如下:
1. 做一些改变:例如,改变操作系统对NMI的响应方式。
2. 等待所有现有的读侧临界区完全结束:例如,通过使用synchronize_sched()原语。这里的关键观察点是,随后的RCU读侧临界区保证能看到所做的任何更改。
3. 清理:例如,返回状态以指示更改已成功完成。
接下来展示从Linux内核改编的例子代码。在这个例子中,timer_stop函数使用synchronize_sched()确保所有正在处理的NMI通知完成后,才释放相关的资源。以下是简化版的代码示例:
1 struct profile_buffer {
2 long size;
3 atomic_t entry[0];
4 };
5 static struct profile_buffer *buf = NULL;
6
7 void nmi_profile(unsigned long pcvalue)
8 {
9 atomic_t *p = rcu_dereference(buf);
10
11 if (p == NULL)
12 return;
13 if (pcvalue >= p->size)
14 return;
15 atomic_inc(&p->entry[pcvalue]);
16 }
17
18 void nmi_stop(void)
19 {
20 atomic_t *p = buf;
21
22 if (p == NULL)
23 return;
24 rcu_assign_pointer(buf, NULL);
25 synchronize_sched();
26 kfree(p);
27 }
第1到4行定义了一个名为profile_buffer的结构体,它包含一个大小(size)和一个不定长度的条目数组(entries)。第5行定义了一个指向profile_buffer的指针,假设在其他地方初始化为指向动态分配的内存区域。
第7到16行定义了nmi_profile()函数,该函数从NMI处理器内部调用。因此,它不能被抢占,也不能被普通的中断处理程序打断,但它仍然可能由于缓存未命中、ECC错误或同一核心内其他硬件线程的周期窃取而延迟。第9行使用rcu_dereference()原语获取本地指向配置文件缓冲区的指针,以确保DEC Alpha上的内存顺序。第11和12行如果当前没有分配配置文件缓冲区,则退出该函数;第13和14行如果pcvalue参数超出范围,则退出该函数。否则,第15行根据pcvalue参数索引增加配置文件缓冲区条目的计数。注意,将大小与缓冲区一起存储保证了即使突然替换为较小的缓冲区,范围检查也与缓冲区匹配。
第18到27行定义了nmi_stop()函数,其中调用者负责互斥(例如,持有正确的锁)。第20行获取指向配置文件缓冲区的指针,第22和23行如果没有缓冲区则退出函数。否则,第24行将配置文件缓冲区指针置为NULL(使用rcu_assign_pointer()原语以在弱有序机器上保持内存顺序),第25行等待一个RCU Sched宽限期结束,特别是等待所有不可抢占的代码区域,包括NMI处理器完成。一旦执行继续到第26行,我们就可以确定任何获取旧缓冲区指针的nmi_profile()实例已经返回。因此,在这种情况下,可以安全地使用kfree()原语释放缓冲区。
简而言之,RCU使得在不同的配置文件缓冲区之间动态切换变得容易(你试试用原子操作高效地做到这一点,或者用锁定机制来实现!)。然而,正如前几节所示,RCU通常在更高的抽象级别上使用。
快速问答6:假设nmi_profile()函数是可以被抢占的,那么需要做出哪些改变才能使这个例子正确工作?
结论
从根本上说,RCU不仅仅是一个提供以下功能的API:
● 一种用于添加新数据的发布-订阅机制,
● 一种等待已有RCU读操作完成的方法,以及
● 一种维护多个版本的规范,以允许在不损害或不当延迟并发RCU读者的情况下进行更改。
尽管如此,可以在RCU的基础上构建更高层次的结构,包括前面章节中列出的读-写锁、引用计数和存在保证等构造。此外,我毫不怀疑Linux社区将继续为RCU以及任何其他同步原语找到有趣的新用途。
致谢
我们都要感谢Andy Whitcroft、Jon Walpole和Gautham Shenoy,他们对本文早期草稿的审阅极大地改进了文档的质量。我要感谢相对论编程项目成员及PNW TEC成员,与他们的许多宝贵讨论让我受益匪浅。我也感激Dan Frye对这项工作的支持。
这项工作仅代表作者的观点,并不一定代表IBM的观点。
Linux是Linus Torvalds的注册商标。
其他公司、产品和服务名称可能是其他公司的商标或服务标志。
快速问答的答案
问题1: WTF??? 你怎么能期望我相信RCU的开销只有100飞秒,而3GHz时钟周期的时间就超过300皮秒?
回答: 首先,请考虑用于进行此测量的内部循环如下:
1 for (i = 0; i < CSCOUNT_SCALE; i++) {
2 rcu_read_lock();
3 rcu_read_unlock();
4 }接下来,考虑rcu_read_lock()和rcu_read_unlock()的有效定义:
1 #define rcu_read_lock() do { } while (0)
2 #define rcu_read_unlock() do { } while (0)此外,编译器会执行简单的优化,允许它将循环替换为:
i = CSCOUNT_SCALE;
因此,“测量”的100飞秒仅仅是定时测量的固定开销除以包含对rcu_read_lock()和rcu_read_unlock()调用的内部循环的通过次数。因此,这个测量实际上是错误的,事实上,它的误差可能达到任意数量级。如上所示,根据rcu_read_lock()和rcu_read_unlock()的定义,实际开销恰好是零。
确实,并不是每天都会出现一个100飞秒的计时测量结果被证明是一个高估的情况!
问题2: 为什么随着临界区开销的增加,读写锁(rwlock)的可变性和开销都会减少?
回答: 因为随着临界区开销的增加,对底层rwlock_t的竞争(contention)会减少。然而,由于缓存颠簸(cache-thrashing)的开销,读写锁的开销不会完全降到单个CPU上的性能。
问题3: 是否存在这种死锁抵抗的例外情况,如果存在,什么样的事件序列可能导致死锁?
回答: 造成涉及RCU读侧原语的死锁循环的一种方法是通过以下(非法的)语句序列:
idx = srcu_read_lock(&srcucb);
synchronize_srcu(&srcucb);
srcu_read_unlock(&srcucb, idx);synchronize_srcu()不能返回直到所有现有的SRCU读侧临界区完成,但它被包含在一个SRCU读侧临界区内,而该临界区在synchronize_srcu()返回之前无法完成。结果是一个典型的自死锁——当你尝试在持有读锁时写获取一个读-写锁时也会得到相同的效果。
注意,这种自死锁场景不适用于经典的RCU(RCU Classic),因为由synchronize_rcu()执行的上下文切换会为此CPU充当静止状态(quiescent state),允许宽限期完成。然而,这可能更糟糕,因为RCU读侧临界区使用的数据可能会由于宽限期的完成而被释放。
简而言之,不要从RCU读侧临界区内部调用同步RCU更新侧原语。
问题4: 但是等一下!这段代码与我们考虑将RCU作为读-写锁的替代品时使用的代码完全相同!这是怎么回事?
回答: 这是“玩具示例法则”的一个效果:超过某个点,代码片段看起来是一样的。唯一的区别在于我们如何思考这段代码。然而,这种差异可能极其重要。举个例子来说明其重要性,如果我们把RCU看作是一种受限的引用计数方案,我们就不会误以为更新会排除RCU读侧临界区。
尽管如此,在某些情况下,把RCU视为读-写锁的替代品通常是有用的,例如,当你用RCU替换读-写锁时。
问题5: 为什么在接近6个CPU时,引用计数的开销会有一个下降?
回答: 最有可能是NUMA(非统一内存访问)效应导致的。然而,从显示的误差线可以看出,引用计数线上测量值存在较大的差异。实际上,在某些情况下,标准偏差超过了测量值的10%。因此,这种开销的下降很可能是一个统计异常。
题: 假设nmi_profile()函数是可以被抢占的,那么需要做出哪些改变才能使这个例子正确工作?
回答: 一种方法是在nmi_profile()中使用rcu_read_lock()和rcu_read_unlock(),并将synchronize_sched()替换为synchronize_rcu(),可能如下所示:
1 struct profile_buffer {
2 long size;
3 atomic_t entry[0];
4 };
5 static struct profile_buffer *buf = NULL;
6
7 void nmi_profile(unsigned long pcvalue)
8 {
9 atomic_t *p;
10
11 rcu_read_lock();
12 p = rcu_dereference(buf);
13 if (p == NULL) {
14 rcu_read_unlock();
15 return;
16 }
17 if (pcvalue >= p->size) {
18 rcu_read_unlock();
19 return;
20 }
21 atomic_inc(&p->entry[pcvalue]);
22 rcu_read_unlock();
23 }
24
25 void nmi_stop(void)
26 {
27 atomic_t *p = buf;
28
29 if (p == NULL)
30 return;
31 rcu_assign_pointer(buf, NULL);
32 synchronize_rcu();
33 kfree(p);
34 }
