


HPN:面向大语言模型训练的数据中心网络架构深度解析与社区启示
一、论文概览与背景
近年来,大语言模型(LLM)的参数规模从千亿迈向万亿,其训练对计算集群的规模与网络性能提出了前所未有的挑战。传统数据中心网络(DCN)因流量模式不匹配、哈希极化(Hash Polarization)和单点故障敏感等问题,难以支撑高效的大规模LLM训练。为此,国内某云团队提出了 HPN(High-Performance Network) —— 一种专为LLM训练优化的数据中心网络架构。该架构通过创新的拓扑设计、硬件优化与智能路由策略,显著提升了训练效率与可靠性,并已在生产环境中稳定运行8个月以上。
二、核心问题与HPN的创新贡献
1. 传统DCN的局限性
-
流量模式不匹配:LLM训练产生周期性突发流量(如梯度同步时的400Gbps全减操作),而传统DCN依赖的ECMP(等价多路径)算法在低熵、高利用率流量下易引发哈希极化,导致负载不均。
-
单点故障敏感:LLM训练为同步迭代过程,任一GPU或ToR(机架顶部交换机)故障可能导致训练中断,而传统单ToR设计故障恢复成本高昂。
-
扩展性瓶颈:传统3层Clos架构难以高效支持超大规模(如15K GPU)集群。
2. HPN的核心创新
-
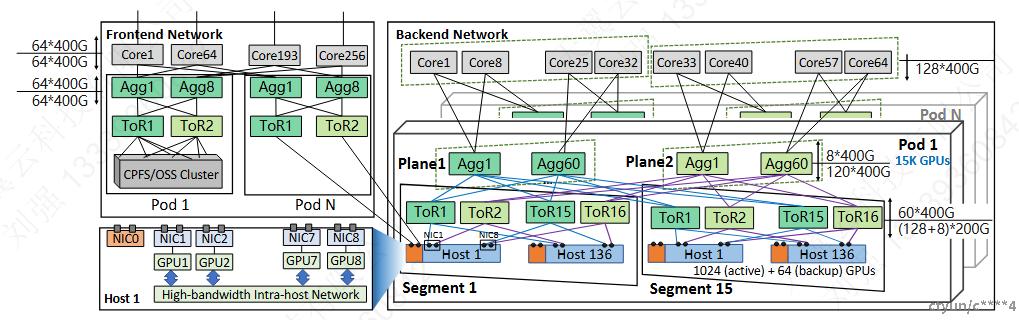
双平面架构(Dual-Plane)
将网络划分为两个独立平面,消除聚合层(Aggregation Layer)的哈希极化。每个平面独立处理流量,路径选择空间缩小1-2个数量级,同时支持15K GPU单Pod互联。 -
非堆叠双ToR设计(Non-Stacked Dual-ToR)
移除ToR间的直连链路,避免堆叠设计中的同步故障风险。通过定制LACP协议与BGP路由收敛,实现故障透明切换,彻底解决单ToR失效问题。 -
分层优化与硬件创新
-
Tier1(接入层):采用51.2Tbps单芯片交换机,结合轨道优化网络(Rail-Optimized Network),单层网络可容纳1K GPU,96.3%的训练任务无需跨层通信。
-
Tier2(聚合层):双平面设计减少50%链路需求,支持跨层流量均衡。
-
Tier3(核心层):按15:1过载比设计,专用于跨Pod流水线并行(PP)流量,最小化对训练性能的影响。
-
-
与ML框架深度协同
优化NCCL等集合通信库,动态选择低拥塞路径,结合应用层负载均衡(基于WQE计数器),提升AllReduce等操作性能达34.7%。
三、关键技术与实现细节
1. 非堆叠双ToR的工程实践
-
挑战:传统堆叠双ToR依赖同步链路,易因版本升级或硬件故障引发级联失效。
-
解决方案:
-
预配置虚拟MAC地址(
00:00:5E:00:01:01)并动态分配端口ID,避免LACP协商冲突。 -
通过BGP发布/32主机路由,实现链路故障的快速收敛(秒级切换)。
-
禁用二层广播,强制流量通过三层路由,避免MAC表老化导致的“黑洞”。
-
2. 双平面架构的负载均衡
-
问题:传统Clos架构中,跨段流量需多次哈希,加剧负载不均。
-
HPN策略:
-
流量进入平面后路径唯一,避免哈希级联效应。
-
结合RePaC算法预计算不相交路径,优化集合通信的路径选择效率。
-
3. 硬件与散热优化
-
51.2Tbps单芯片交换机:采用定制化均热板(Vapor Chamber),优化芯粒布局与散热结构,解决高吞吐下的过热问题(冷却效率提升15%)。
-
轨道优化网络:利用GPU间高速NVLink,将跨节点流量转为节点内转发,降低对聚合层带宽的依赖。
四、实验与生产验证
1. 性能提升
-
端到端训练:GPT-3 175B模型在2300+ GPU集群中,HPN相比传统DCN+吞吐提升14.9%。
-
集合通信:AllReduce性能提升59.3%,多AllReduce(Megatron框架)提升158.2%。
-
可靠性:双ToR设计使单链路故障仅造成6.25%性能下降,修复后即时恢复,无训练中断。
2. 扩展性与成本
-
单Pod容量:15K GPU(传统架构需多Pod互联),减少30%网络建设成本。
-
长期规划:支持未来100K GPU集群,通过核心层双平面与优先级哈希策略平衡扩展性与性能。
五、社区启示与未来方向
1. 对AI基础设施的启示
-
专用化设计:HPN证明通用DCN无法满足LLM训练需求,需针对通信模式(如小消息AllReduce、大张量传输)定制网络。
-
软硬协同:从交换机芯片到ML框架的全栈优化是突破性能瓶颈的关键。
2. 行业应用与挑战
-
混合负载支持:HPN的前后端网络分离设计为训练与推理混合部署提供可能,但需解决资源调度与隔离问题。
-
开放生态:HPN基于以太网而非InfiniBand,避免厂商锁定,但依赖更复杂的协议定制(如BGP扩展)。
3. 未来研究方向
-
动态拓扑适应:面向MoE(混合专家)模型等新兴架构,需支持灵活的全连接通信。
-
绿色计算:高吞吐芯片的散热与能效优化仍是长期挑战。
六、结语
HPN通过架构创新与工程实践,为超大规模LLM训练提供了高性能、高可靠的网络基础设施。其设计理念(如双平面、非堆叠双ToR)不仅解决了现有问题,更为未来AI集群的扩展与异构负载兼容性树立了标杆。随着模型规模的持续增长,HPN的开放性与模块化设计有望推动AI基础设施向更高效、更弹性的方向演进。
