


Key-Value Storage简介
1. 背景信息
1.1 结构化与非结构化数据
结构化数据是指具有明确定义的结构(类型/大小/组织形式)、遵循一致顺序的数据。有明确的模式,例如性别,年龄,电话号码,身份证号,邮箱地址,邮政编码等。
非结构化数据则是指没有预先定义好的数据模型或者没有以一个预先定义的方式来组织的信息。可以是文本或非文本类型,包括文件,邮件内容,图片,音频/视频,网站内容数据,地理信息等。
IDC 2017年白皮书《Data Age 2025》预测,2018年到2025年之间,全球产生的数据量将会从33ZB增长到175ZB,复合增长率达到27%,其中超过80%的数据都会是处理难度较大的非结构化数据。
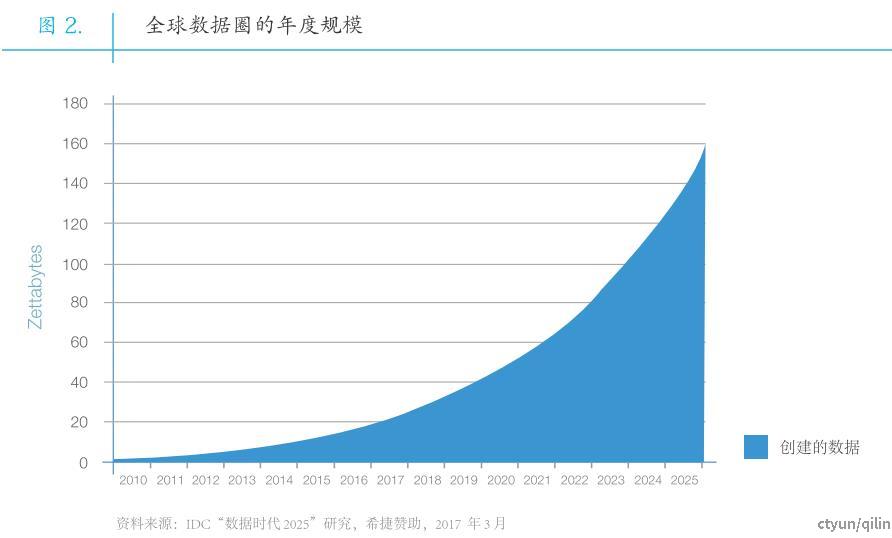
IDC报告《2021-2025年全球数据及存储领域结构化和非结构化数据预测(2021年7月)》,超过90%的现有数据是非结构化数据,并且在过去十年中大体保持不变。
1.2 非结构化数据的存储
非结构化数据通常以两种形式来存储和管理:
1. 以文件的形式存储在文件系统中,可以是本地文件系统或分布式文件系统等任何形式的文件系统。但数据管理不方便,并需要额外考虑事务处理的一致性和数据的安全性。
2. 存储在NoSQL数据库中。这种方式能够充分利用数据库的事务、管理和安全特性,但在数据查询和读写的性能会有瓶颈。
NoSQL数据库
NoSQL数据库泛指非关系型的数据库,它是为了解决大规模数据集合以及多种数据类型带来的问题,NoSQL数据库并没有一个统一的架构,包括:
• (Key-Value)键值对存储:以键值对的形式存储数据,每个键对应一个值,适用于缓存、日志等高性能场景
• (Column)列存储:以列族的形式存储数据,每个列族可以包含多个行,适用于搜索引擎、大数据存储等场景
• (Document)文档存储:以文档的形式存储数据,每个文档可包含多个字段,适用于Web应用、日志等场景
• (Graph)图存储:以图结构存储数据,适用于社交网络、推荐系统等场景
2. Key-Value存储
2.1 概念
Key-Value存储是一种以键值对(Key-Value Pair)形式存储数据的数据库。这种数据库以键值对的形式组织数据,每个Key键对应一个Value值。主要优点是:速度快,存储数据量大,支持高并发和方便扩展。Key-Value存储非常适合通过主键Key进行查询,但不能进行复杂的条件查询。应用场景非常广泛:
• Cache缓存:应用程序可以将数据存储在内存中以提高访问速度,并确保数据的唯一性
• 消息队列:RabbitMQ和Kafka等消息队列系统中,使用Key-Value存储来跟踪消息的路由和分发
• 分布式系统:在分布式系统中,Key-Value存储可以用于管理分布式数据和实现数据复制
• Web会话管理:Web应用通常使用Key-Value存储来管理用户会话状态
• 游戏应用:多人在线游戏中,游戏状态通常存储在Key-Value存储中
2.2 分类
Key-Value数据库有很多,当前主流的核心算法有三种:基于Hash哈希的,基于B+-tree的和基于LSM-tree的。
2.2.1 基于Hash算法
在基于哈希的Key-Value数据库中,哈希表是一个非常关键的数据结构。哈希表可以将任意键(Key)映射到一个索引(Index),并将值(Value)存储在该索引的位置上。这种映射关系使得我们可以非常快速地找到对应的键值对,通常只需要O(1)的时间复杂度。
在写操作时,Key-Value数据库会使用哈希函数将键(Key)映射成索引(Index),并将值(Value)存储在该索引位置上。在查询操作时,数据库会再次使用哈希函数将键(Key)映射成索引(Index),并在该索引位置上查找对应的值(Value)。
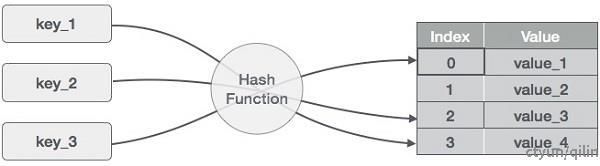
基于哈希的Key-Value数据库具有快速、可扩展和高可用性的特点,可以处理大量的数据,并保证高并发访问的速度。同时,基于哈希的Key-Value数据库也具有一些潜在的缺点:
• 可能会受到哈希冲突的影响而降低性能,尽管这种可能性很小,但在处理大量数据时可能会出现
• 数据的持久性没有很好的保证,如果发生硬件故障或数据库崩溃,数据可能会丢失(一致性Hash& 多副本)一些典型的基于哈希的Key-Value数据库包括Redis、Memcached、Aerospike等。
2.2.2 基于B+-tree算法
基于B+-tree的Key-Value数据库是一种数据存储和检索系统,它使用B+-tree作为其基本的数据结构。在基于B+树的Key-Value数据库中,B+树被用作索引结构,所有的键(Key)和值(Value)都存储在叶子节点上,并形成了一个链表。查找、插入和删除等操作时,时间复杂度比较稳定且都为O(logn)。
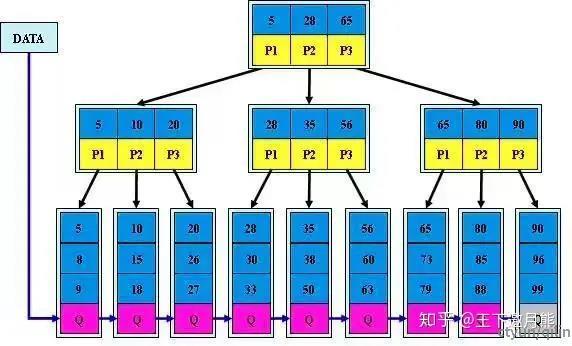
基于B+-tree的Key-Value数据库具有一些显著的特点:
• 由于B+-tree的特性,相近的key-value对能够存储在一起,数据库可以支持范围查询和有序查找等操作
• B+-tree的平衡特性使得其可以支持多个线程或进程同时进行读写操作
• B+-tree算法相对复杂,维护存在难度:基于B+-tree的Key-Value数据库的插入操作通常需要在叶子节点上进行,如果插入的键(Key)已经存在,则需要进行分裂操作。分裂操作会将节点分裂成两个节点,并重新平衡树结构。在分裂操作时,如果根节点只有一个子节点,则需要进行合并操作,以保证树的平衡性。
基于B+-tree算法的代表NoSQL数据库使MongoDB。
2.2.3 基于LSM-Tree算法
LSM-Tree 采取读写分离的策略,会优先保证写操作的性能:其数据首先存储内存中,而后需要定期Flush 到硬盘上。LSM-Tree可以将离散的随机写请求转换成批量的顺序写操作,无论是在RAM、HDD还是在SSD中,LSM-Tree的写性能都更加优秀。基于LSM-Tree的KV数据库有HBase, Cassandra,RocksDB, LevelDB 等。
根据LSM-tree算法,写入请求通常直接写入在内存中维护的内存表数据结构中,性能很好。但当内存表的数据量达到一定阈值时,将内存表持久化到SSTable文件;同时,在分层结构中,上一层Level的SSTable数量达到一定阈值,就会进行Compaction合并成下一级Level的SSTable。
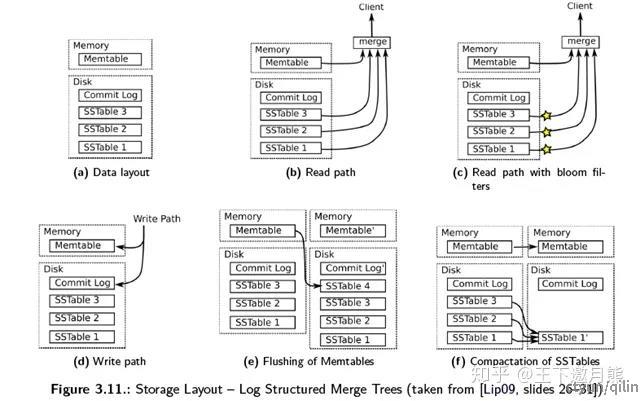
基于LSM-tree的Key-Value数据库存在以下问题:
• 写入性能的波动:Compaction操作会占用CPU,内存和IO资源,这导致了写入性能波动。
• 较大的写入放大(WA>10x):为了确保数据的一致性和完整性,LSM-tree需要将写前日志(Write Ahead Log)存储在盘上,这需要额外的空间。数据在SSTable中从旧到新可能会存在多个版本,成倍的增加了存储空间。此外Compaction操作也需要额外的临时空间存放数据文件。
• 随机读性能相对较差:最好情况是从内存中直接读取,最差情况是遍历所有Level层级的SSTable,所以随机读的平均时延不可预期,性能也相对较差。
