1.1扩散模型生成
以DDPM为例,扩散模型的学习目标是学习训练数据的分布,生成符合训练数据分布的图片。
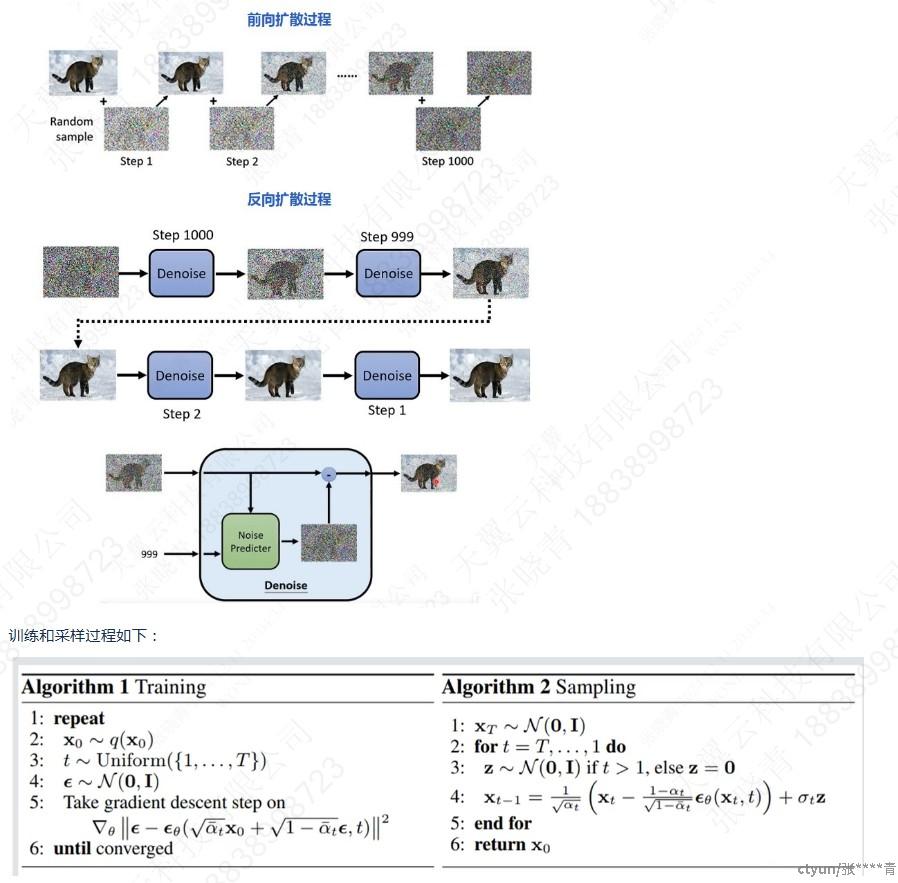
opensora模型训练流程:具体代码处理逻辑(opensora/schedulers/iddpm/gaussian_diffusion.py)
- 模型训练冻结vae encoder和text encoder,只更新diffusion model:STDiT的参数。
- 模型训练不涉及decoder部分,loss根据STDiT预测的噪声计算的。

1.2 模型结构
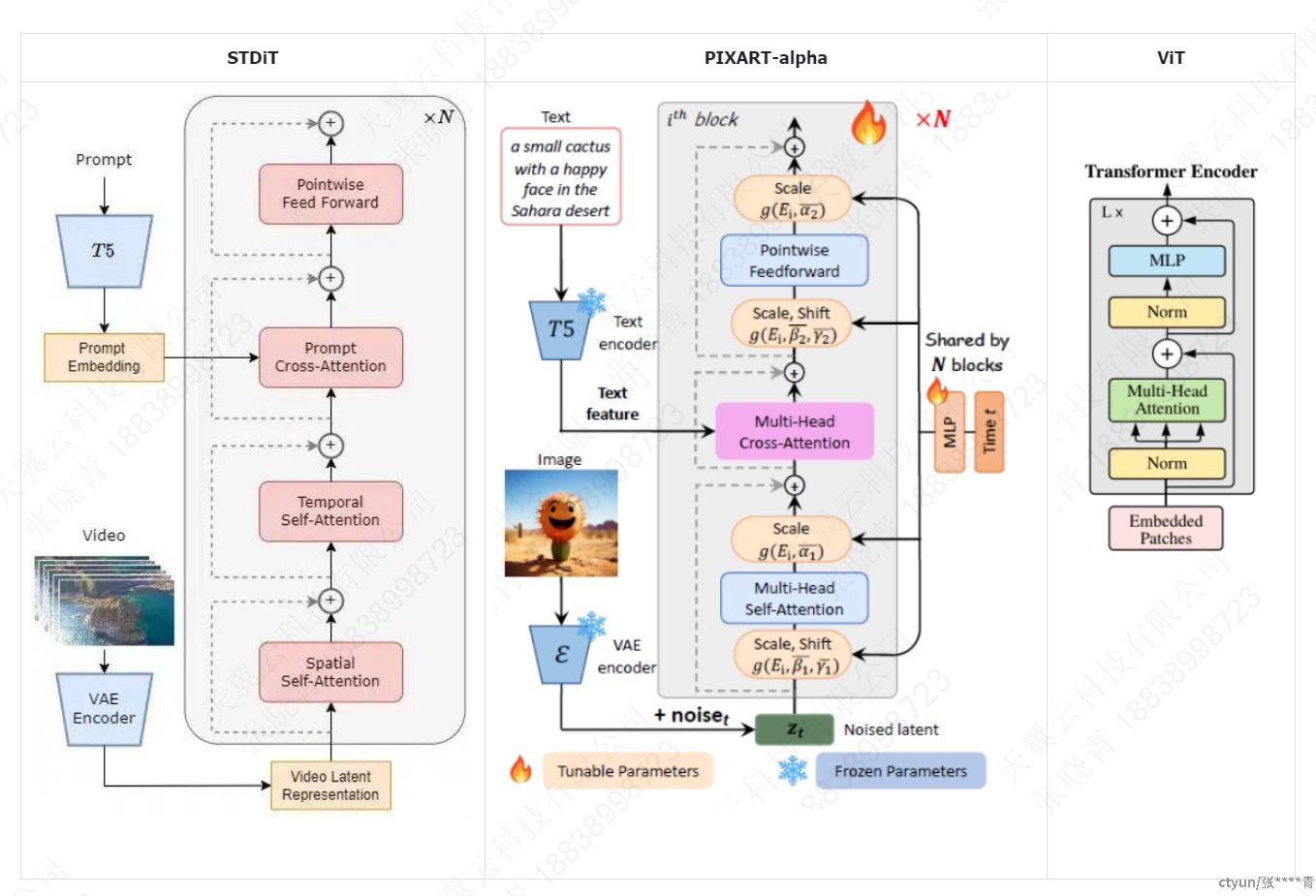
扩散模块STDiT结构如下,参考PIXART-alpha中DiT的实现增加了Temporal-Attention。
PIXART-alpha每个block相比ViT增加了CrossAttetion处理文本信息交互,修改层归一化为自适应层归一化。
STDiT在PIXART-alpha基础上增加了temporal attention进行时间维度的attention。
1.3 层归一化
模型层归一化与pixel-alpha模型采用的一致,目的是使模型更好的适应不同数据分布。自适应层归一化的发展如下。

1.4 分桶训练
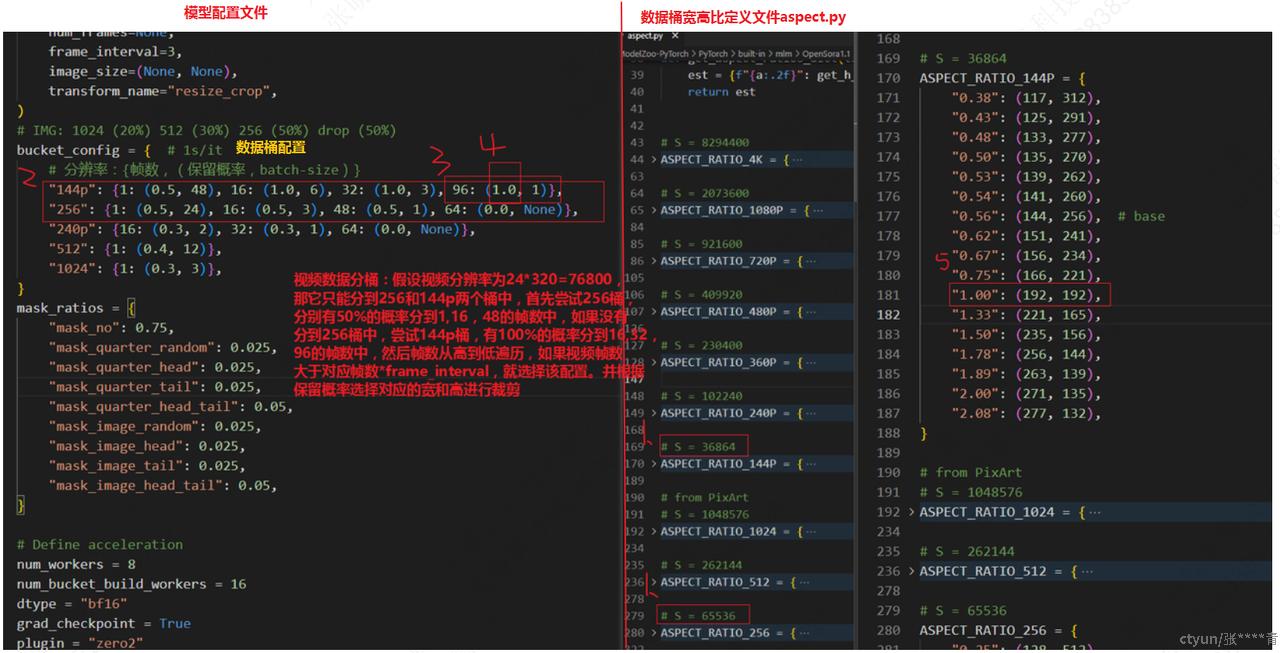
- 当数据集中视频大小差别比较大时,过长的视频可能OOM,过短的视频显存利用率比较低。为了解决这一问题采用分桶训练的方式。
- 桶是(分辨率,帧数量,宽高比)的三元组。一种分辨率涵盖大多数常见的视频宽高比。进一步地,为每个(分辨率,帧数量)二元组引入保留概率和batch_size,以降低计算成本并实现多阶段训练,并且可以控制不同桶中的样本数量,平衡GPU负载。
- 代码实现逻辑:(opensora/datasets/sampler.py)
- 找到≤视频分辨率的最大分辨率的桶;
- 找到≤视频帧数的最大帧数的桶;
- 根据桶保留概率判断是否选择该桶;
- 选择该桶中宽高比与视频最接近的子桶;
- 将视频resize到桶的帧数和宽高比对应的宽和高;
- 每次从一个桶中选择batch输入模型。
- 具体实例讲解如下
1.5 图生视频/长视频生成任务
具体的任务类型如下
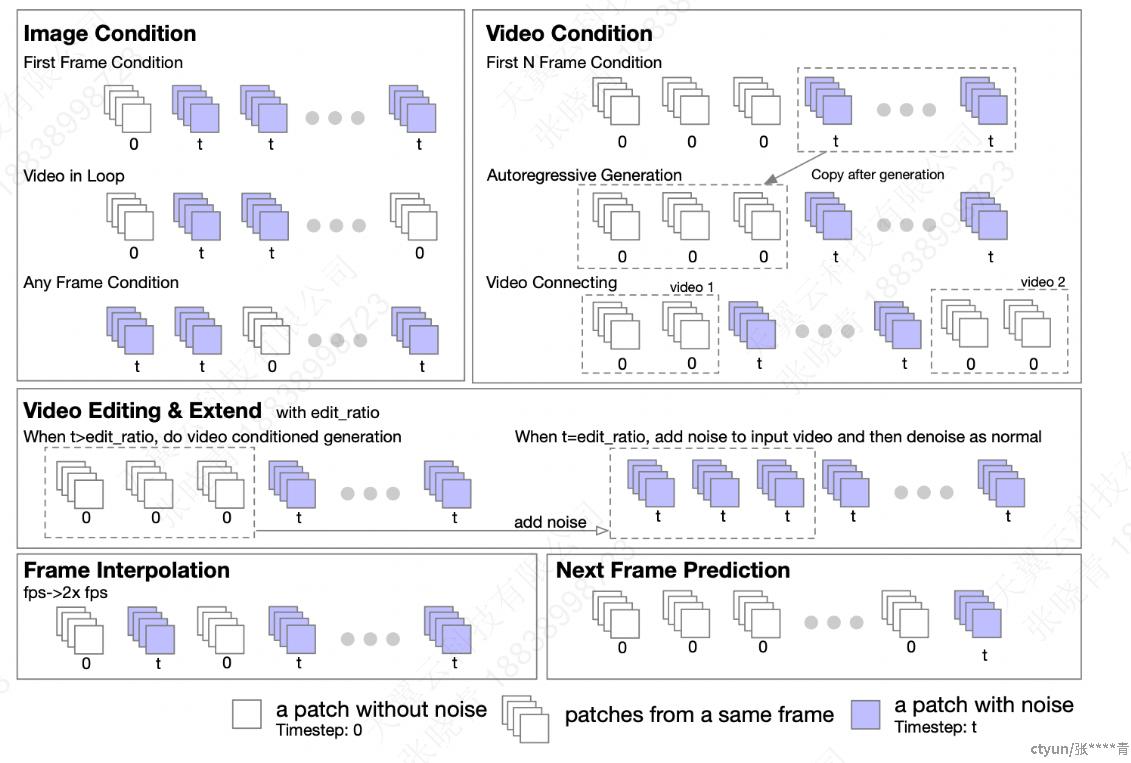
1.6 数据预处理
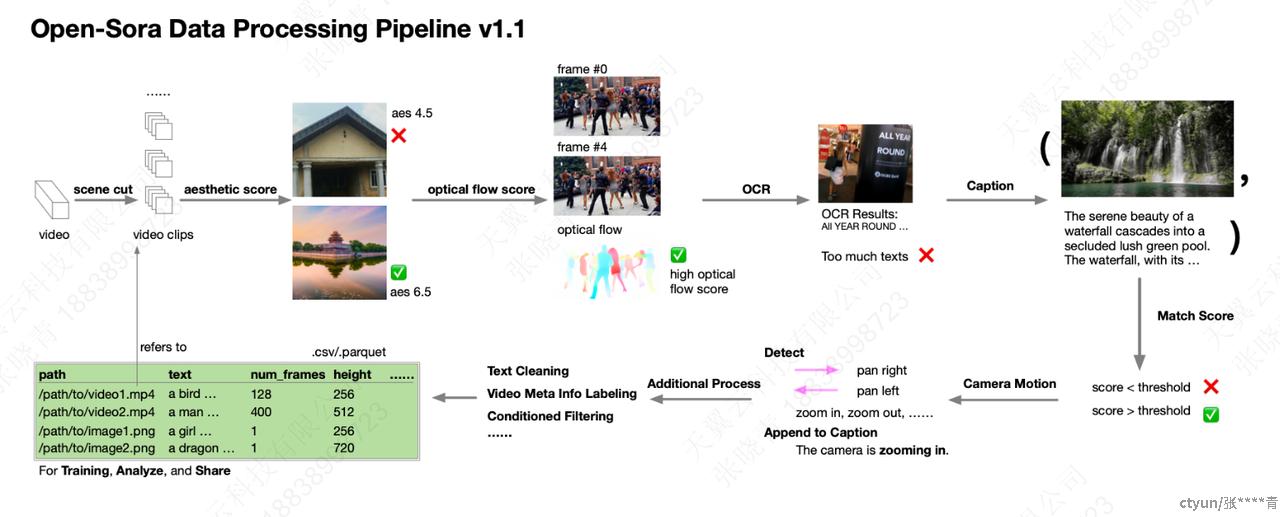
数据预处理包括视频剪辑、美学分数过滤、光流分数过滤、OCR检测过滤、文本匹配分数过滤,视频描述生成。可根据数据集的情况选择性进行某项预处理过程。
视频剪辑:原始视频通常包含多个场景并且对于训练来说太长。因此,根据场景将它们分割成更短的片段。需要安装视频剪辑工具如scenedetect。
美学分数过滤:评估视频的美学质量。需要安装clip,下载llava模型或者pllava模型。
光流分数过滤: 光流分数用于评估视频的运动。光流分数越高表示运动幅度越大。需要下载UniMatch模型。
OCR光学字符识别检测过滤: 一些视频是密集文本场景,如新闻广播和广告,这些不适合用于训练。需要下载 DBNet++模型
文本匹配分数过滤: 计算匹配分数来评估图像 / 视频与其描述之间的对齐情况。需要 CLIP 模型,使用余弦相似度作为匹配分数。