


设想一下,互联网宛如一座庞大的图书馆,而每一个网页恰似其中的一册书籍。URL 就如同书籍的标题,磁盘位置则等同于书籍在图书馆书架上的精准定位。如今,我们的使命是根据书籍的标题寻觅其在书架上的位置,进而将其取出。
在现实中的图书馆里,通常都会存在一个数据库,用以记载书籍以及相应的书架编号,如此一来,凭借书名便能够知晓其所在位置。这个数据库便是记录书名与位置之间的关联,然而,每次数据库自磁盘启动时,这一关联都需要重新构建,倘若数据量极为庞大,那么重建所需的时间可能会相当漫长,那么是否存在不必建立此类关联的可能呢?
首先,我们需要为每一本书赋予一个独一无二的标识符,我们将其称作“MD5 值”。这恰似我们为每本书贴上了一个独特的条形码。
有了书籍的条形码(MD5 值)之后,试想一下,倘若我们拥有一个大书架,每个格子对应一个 md5,如此一来,给出一个条形码便能找到对应的格子,但这种情况在现实中难以实现,毕竟哪有如此巨大的书架。
于是,我们采用了一种方法:构建了一个大书架(哈希表),并非每个条形码都拥有单独的书架格子。相反,我们将众多的条形码映射至同一个格子上。
当两个不同的条形码映射到同一个书架格子时,这种情况被称作“冲突”。为了化解这一难题,我们在每个书架格子上悬挂了若干小篮子(链表),所有映射至此格子的书籍都被放置在这些小篮子中。
如此一来,当我们想要找一本书时,依据 md5 值便可找到对应的格子,接着查看格子里的所有小篮子里是否存在我们所需的书籍。
Apache Traffic Server(ATS)便是依照这样的方式运作。它运用 MD5 值充当条形码,构建了一个大书架(哈希表),并且在每个格子上悬挂了若干小篮子(链表)来应对冲突。
具体实现 ats 索引结构是这样的
ats 索引大小是固定的,初始化的时候会根据磁盘大小,文件平均大小,一次性创建若干segments,每个segment不超过65535个索引(dir), 每个segment里包含相同的buckets数量,每个bucket包含4个索引(dir),并且每个segment有一个freelist链表,这个防止每个bucket里面4个索引不够用解决hash冲突用的,所有segment下bucket共用同一freelist取索引
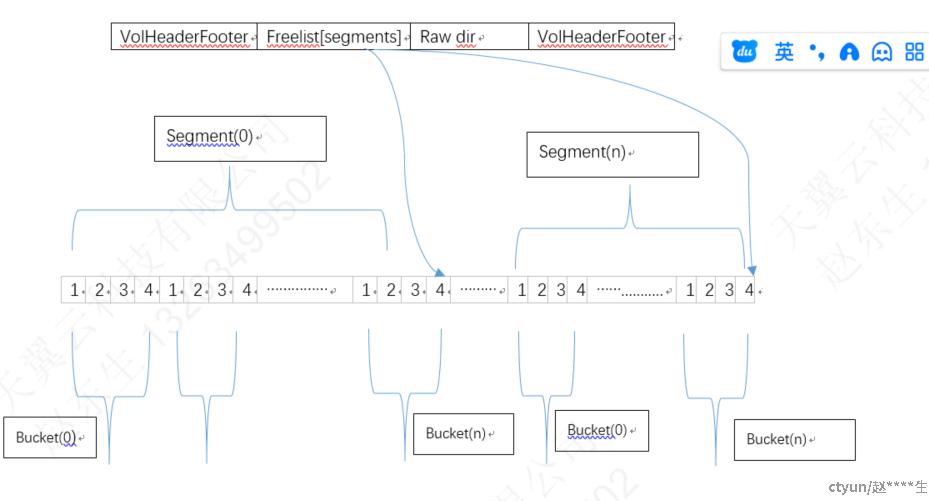
上图一个索引结构,这个结构就是固化到磁盘上,相当于磁盘上一个大数组,缓存启动的时候加载这个大的数组到内存,索引关系自动就有了,包括
VolHeaderFooter,freelist[segments], raw dir, VolHeadFooter
VolHeaderFooter就是索引的元数据,记录当前写入的位置,圈数
freelist[segments] 每个segments的freelist,如上图,初始化的时候会将每个segment所有bucket下的2,3,4索引组成该segment的feelist链表
raw dir, 就是索引(dir),每个索引10个字节,每个索引记录磁盘位置,文件大小等信息
缓存的查找:
根据缓存的url计算出md5值,之后计算segment和bucket,之后遍历bucket里面索引,找到需要的索引,因为索引的信息没有记录md5值,所以找到的索引不一定是要的索引,需要读取磁盘信息,因为磁盘数据里是记录md5值的
ats 索引优点:
1.索引只有10个字节,支持TB级别的数据,也不过就G级别内存,例如7TB盘,平均存储大小64KB,每个索引10个字节, 需要 1GB内存
2. 不用启动的时候重新建立索引,给一个url,就可以算出md5值,之后就可以计算出segment bucket
缺点
1. 浪费索引,大多数索引是用不到的,可以看到索引也就用了20%
2. 索引不能准确知道是否要找的,需要读取磁盘才能知道,这样读取磁盘就限制其相关性能了
