


一、背景描述:
prometheus存有大量的监控明细数据,但是报表或者大屏监控需要的是更高维度的数据统计。如果直接从明细数据统计,很可能会因为数据量
过大而导致查询缓慢,甚至prometheus发生OOM。
二、解决思路:
借助prometheus提供的federate特性和recording rule特性实现。
1.在底层prometheus,通过recording rule预计算需要统计的明细metrics,形成新的指标。metrics命名最好遵循prometheus的规范
2.创建提供大屏查询的prometheus(暂且叫统计用prometheus),通过federate功能,从步骤1中的底层prometheus获取统计用metrics。
三、优势:
1.通过上述操作,即可将底层数据和统计数据分割。由于统计用prometheus只保存高维度数据,所以数据量会比底层prometheus少很多。可以设置更长的数据存留时间(比如一年),即可满足报表对历史数据统计的要求;
2.传统方式做法:利用定时器,将统计数据存到mysql。相比之下,prometheus federate方案对统计报表的时间精度可以细化到秒级。而且太久远的统计数据会自动清除(当然也可以存留5年、10年)。
四、实施步骤:
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
external_labels:
EXT_LABEL_LEVEL: 'base_prometheus' # 设置外部label:EXT_LABEL_LEVEL=base_prometheus
scrape_configs:
- job_name: 'node-exporter' # 采集node-exporter
static_configs:
- targets: ['node-exporter:9100']global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
external_labels:
EXT_LABEL_FEDERATE: 'true' # 有此label的数据,证明出自此prometheus
scrape_configs:
- job_name: 'federate'
honor_labels: true # 避免原始数据中,因为label重复被覆盖
metrics_path: '/prometheus/federate' # 因为我的prometheus配置文件中添加了前缀“/prometheus”
params:
'match[]':
- '{__name__=~"^node_.*"}' # 抽取底层prometheus中,所有node开头的metrics
static_configs:
- targets: # 设置底层prometheus地址
- 'prometheus:9090' # 本实施例,底层prometheus安装在k8s中,所以这里写的是servcie名称效果
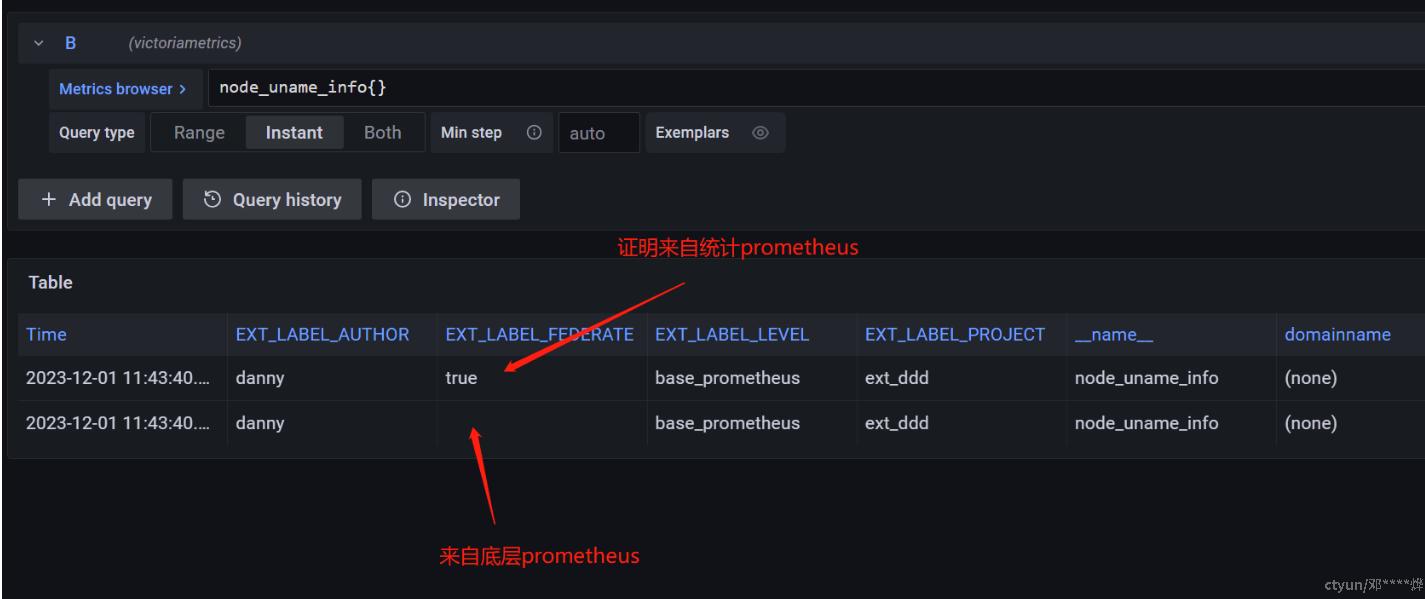
五、其他可选项
类似可选项还包括thanos、victoriaVM。但这些都不是prometheus原生的组件,且更适用于大型的数据监控。如果数据量不大(比如边缘集群),使用federate特性已经可以满足大部分场景。
