


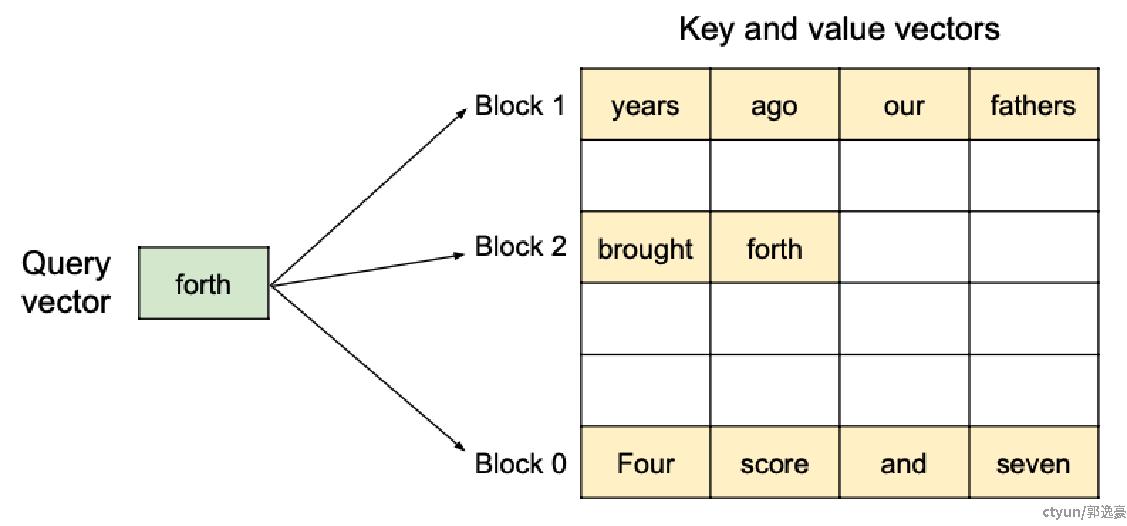
PagedAttention支持KV块存储在非连续的物理内存中,使得vLLM中的内存分页管理更加灵活。如下图所示,将kv cache分成多个block,而PagedAttention的目的是实现模型推理中self-attention的加速操作(如下图公式)
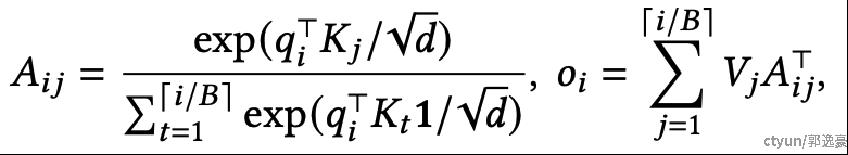
self-attention的Q、K、V的维度分别为:
Q[num_seqs, num_heads, head_size]
KCache [num_blocks, block_size, num_kv_heads, head_size]
VCache [num_blocks, block_size, num_kv_heads, head_size]
按照CUDA编程模型对任务进行并行切分: 每个block负责一个seq中一个head的运算,即grid大小(num_heads, num_seqs),grid中每个block含有NUM_THREADS个线程,NUM_THREADS是常量,默认为128。
1、确定线程组
一个Block有128线程,一个Warp是32线程,所以一个Block有4个Warp; 从KCache维度切分,每个Warp一次迭代可以负责一个KCache block的运算; 一个KCache block有16个token,则32个线程负责16个token,于是引入线程组THREAD_GROUP_SIZE,THREAD_GROUP_SIZE=2
2、确定向量长度
规定一个线程组(2个线程),每次迭代只拿16B的数据进行运算,那么每个线程要处理8B(16/2)的数据, 假如我们计算的qkv数据类型scalar_t是BFloat16,那么每个线程要处理的数据向量长度VEC_SIZE为 8 / sizeof(BF16) = 8/2 = 4。
3、加载q向量
thread Block内每个Warp都需要q向量参与,于是将q向量传到Share Memory;
存储形式:q_vecs[THREAD_GROUP_SIZE][NUM_VECS_PER_THREAD]; 其中THREAD_GROUP_SIZE = 2,NUM_VECS_PER_THREAD = head_size/THREAD_GROUP_SIZE/VEC_SIZE。
假设head_size=256,那么q_vecs的shape为[2, 32, 4],需要64个线程一次搬运即可。
4、加载k向量
KCache实际存储形式: KCache [num_blocks, block_size, num_kv_heads, head_size] ==> KCache [num_blocks, num_kv_heads, head_size/x, block_size, x]
如下图假设head_size=256,x=8,block_size=16, 那么KCache [num_blocks, num_kv_heads, 32, 16, 8],
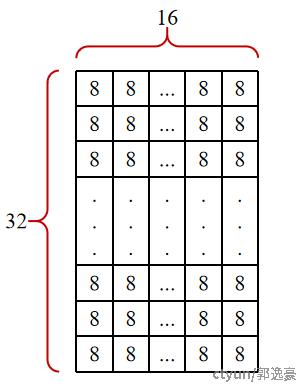
1个线程组(THREAD_GROUP_SIZE = 2)负责1个token的qk计算, 1个thread需要拷贝32*4的k数据量, 即循环32次获得k_vecs,k_vecs的shape为[32, 4]。
5、qk计算
每个thread对q_vecs[i](i=0or1)和k_vecs进行乘加运算,得到qk结果。
将线程组内qk结果进行相加,得到该线程组负责的一个token的完整qk计算结果。
这里使用__shfl_xor_sync进行一个warp内的归约操作,因为线程组THREAD_GROUP_SIZE = 2,所以循环1次即可完成线程组内qk相加。然后每个线程组派一个thread去把qk结果写入Shared Memory,即16个thread把16个token的qk结果传到Shared Memory。该warp继续处理下一个KCache block。
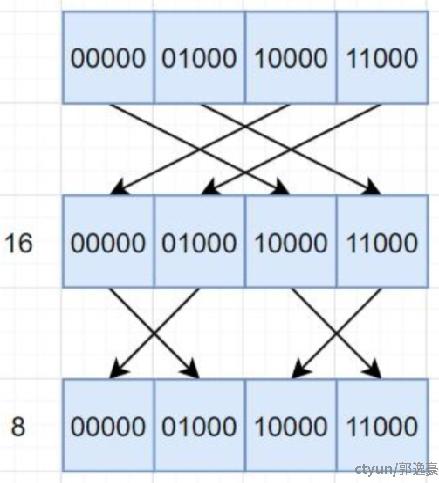
6、softmax计算
获得qk_max:
1、warp内使用__shfl_xor_sync归约操作得到warp内最大的qk_max,并写到Shared Memory,这里有4个warp即Shared Memory存有4个qk_max;
2、线程同步;
3、warp内前4个thread分别读取SHM上的4个qk_max,继续使用__shfl_xor_sync归约得到最大的qk_max;
4、使用__shfl_sync广播到warp内所有线程。
计算softmax分子:
这里直接128个thread分别计算每一个token的exp(qk[j] − qk_max),并将结果写到Shared Memory,同时每个thread累加计算结果sum_exp。
计算softmax分母:
1、warp内使用__shfl_xor_sync归约操作累加计算sum_exp,并写到Shared Memory;
2、线程同步;
3、warp内前4个thread分别读取SHM上的4个sum_exp,继续使用__shfl_xor_sync累加计算sum_exp;
4、使用__shfl_sync广播到warp内所有线程。
7、logits*v计算
VCache实际存储形式:
VCache [num_blocks, block_size, num_kv_heads, head_size] ==> VCache [num_blocks, num_kv_heads, head_size, block_size]
一个warp一次迭代负责一个VCache block的运算,warp内1个thread一次迭代处理16B的数据, 即处理的数据向量长度V_VEC_SIZE为 16 / sizeof(BF16) = 16/2 = 8,如下图,假设head_size=256,那么1个thread总共需要迭代 256*16/8/32 = 16次计算,所以1个thread会保存16个计算结果,通过warp内相邻线程归约相加, 每个thread最终保存该VCache block的完整的16个计算结果数据。
接下来进行warp间相加:
1、第3个和第4个warp分别将各自的16*16个计算结果写到Shared Memory;
2、线程同步;
3、第1个和第2个warp分别获取SHM上的第3和第4个warp的计算结果,与各自的计算结果进行相加;
4、线程同步;
5、第2个warp将计算结果写到Shared Memory;
6、线程同步;
7、第1个warp获取SHM上的第2个warp的计算结果,并进行相加后,作为最后的结果输出。
