


pg_basebackup原理介绍
pg_basebackup使用方法
pg_basebackup是pg提供的一个基础备份工具,可以支持主备库的数据备份,它的主要参数如下:
pg_basebackup [option...]
-D directory 保存备份数据的本地目录,如果为 - 且F为tar就输出到标准输出流
--pgdata=directory
-F format 备份文件的格式,p 为平面文件,t为tar文件包。
--format=format plain|tar
-r rate 从该服务器传输数据的最大传输率。值的单位是千字节每秒。加上一个后缀M表示兆字节每秒。也接受后缀k,但是没有效果。合法的值在 32 千字节每秒到 1024 兆字节每秒之间。
--max-rate=rate
-R 在输出目录中(或者当使用 tar 格式时再基础归档文件中)写一个最小的recovery.conf来简化设置一个后备服务器。recovery.conf文件将记录连接设置(如果有)以及pg_basebackup所使用的复制槽,这样流复制后面就会使用相同的设置。
--write-recovery-conf -S slotname 这个选项只能和-X stream一起使用。它导致 WAL 流使用指定的复制槽。如果该基础备份意图用作一个使用复制槽的流复制后备服务器,它应该使用recovery.conf中相同的复制槽名称。那样就可以确保服务器不会移除基础备份结束和流复制开始之前任何必要的 WAL 数据。 --slot=slotname
-X method 如果为n,则备份时不会包含日志, 如果为f,在备份末尾收集日志文件,如果为s,在备份被创建时流传送预写日志。这将开启一个到服务器的第二连接并且在运行备份时并行开始流传输预写日志。
--wal-method=method none|fetch|stream
其他参数请参考pg_basebackup说明文档 从上述的参数可以看出pg_basebackup支持两种全量备份的方式, 1.以fetch的方式,先备份数据在备份日志
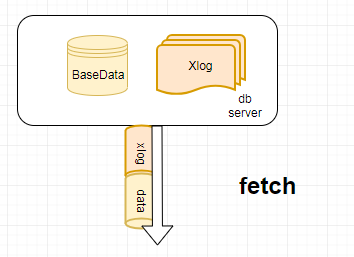
2.以stream的方式,并行的备份数据和日志
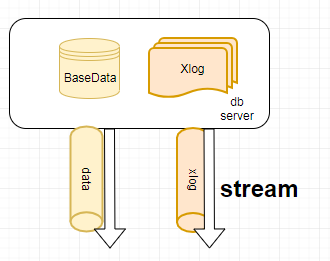
从上述的两图中可以看出,pg_basebackup对于全量备份的数据和日志,提供了串行备份和并行备份的方式。fetch模式也就是串行备份需要保证在备份数据的过程中,备份开始时刻的日志需要一直保存下来, 也就说pg的wal_keep_segments需要足够大去保存日志文件,如果备份数据期间,日志开始时刻的日志已经被移除,那么备份就会失败。而stream模式,也就是并行备份过程中wal_max_sender必须保证不小于2。 而stream模式不支持,将数据和日志以流的方式输出到标准输出。
pg_basebackup原理
pg_basebackup内部流程如下图所示:
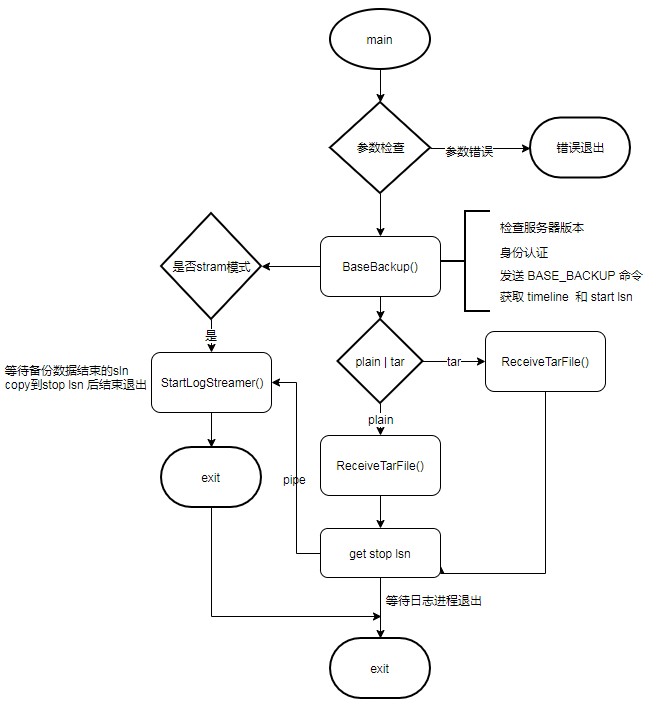
main为程序入口,接收pg_basebackup –args ,根据参数决定备份的方式选择。 进入main函数后首先进行各种参数合法性判断,最后调用BaseBackup()函数进行开始备份数据。 BaseBackup备份数据函数,首先对版本进行判断,必须大于9.1版本,建立服务器连接,创建recovery.conf文件如果需要,发送IDENTIFY_SYSTEM命令给服务器设置复制协议,调用 RunIdentifySystem获取相关信息。发送BASE_BACKUP命令通知服务器准备备份数据并创建检查点。 创建检查点完成后获取检查点在xlog中的lsn,然后获取备份头部数据,计算数据的size,并获取表空间map, 如果参数设置包含日志备份调用StartLogStreamer函数,创建管道,启动日志备份子进程,开始备份日志。 根据F参数t或p判断以tar格式接收(ReceiveTarFile)还是以平面文件格式接收(ReceiveAndUnpackTarFile)。 获取备份数据结束时wal的lsn,使用管道将endlsn发送给接收日志的子进程。然后等待后台接收日志子进程结束退出,清理recovery.conf文件, 确定data备份数据持久化到磁盘上,关闭连接,备份完成。 StartLogStreamer开始日志流备份函数,具体实现,首先获取备份日志的起始LSN,然后创建管道,fork子进程调用LogStreamerMain函数,开始并行备份日志文件。 ReceiveTarFile接收tar格式数据文件函数。根据参数判断是输出标准输出流还是写入.tar或者压缩文件。循环获取流数据并拷贝写入文件或者输出流。 ReceiveAndUnpackTarFile 接收平面文件格式数据函数,获取表空间集合,根据目录递归的拷贝文件并写入本地。 LogStreamerMain备份日志主函数,通过获取连接,和管道接收参数来初始化StreamCtl日志流操作结构体,然后调用ReceiveXlogStream函数接收日志流。具体细节如下图:
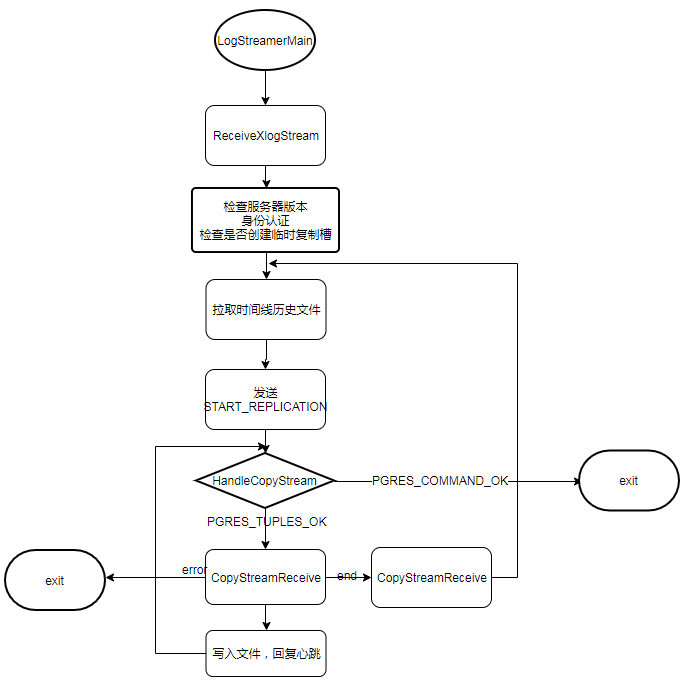
ReceiveXlogStream接收xlog流数据函数,主要流程为,检查服务器版本,确认和服务器连接,并获取标识等信息,根据需要创建临时复制槽, 初始化流日志的起始位置,检查时间线历史文件是否存在,检查是否需要停止备份日志流,循环调用HandleCopyStream函数,接收处理日志流。
pg_basebackup存在的问题
我们可以很容易的发现,对于全量备份,pg_basebackup的两个种方案,都有一定的缺陷,fetch模式,必须要保证wal_keep_segments必须保证足够大,当基础数据量非常大的时候,随便备份时间变长,产生过的日志会越来越多,所以这段过程中的日志可能需要很大的磁盘空间来保存,磁盘空间是有限的,而数据量永远是在增长,所以这种备份方式的失败是在所难免的。而第二种stream模式,随便不会对磁盘空间有要求,但是它并不支持,数据和日志同时输出到标准输出流,这样就不利于我们压缩,而且它的日志只能以落地方式,这一点也很不友好。 针对于这个缺陷,我们先来看一下服务端的原理,然后我做了一个改进方案。
备份内核服务端实现原理
备份流程
备份服务端的代码我们可以在 pg源码的/src/backend/replication目录下看到,这部分功能的程序入口在walsender.c中的exec_replication_command中,此函数当客户端和服务器建立连接时,且发送Q查询语句时调用。 主要的流程如下图所示:
基础数据发送
SendBaseBackup发送数据备份函数,首先对备份命令进行参数解析,检查pg_tblspc表空间目录,调用perform_base_backup函数,开始备份。 perform_base_backup执行基础备份函数,首先收集参数,判断是否处于恢复状态,调用do_pg_start_backup函数获取起始备份lsn,然后做错误检查,对整个过程进行错误检测,一旦出现错误就停止备份,向客户端发送起始日志的lsn和时间线,处理pg_stat目录,发送表空间的头部信息,根据参数设置网络速率,便利每一个表空间,逐一发送表空间数据流,调用do_pg_stop_backup获取结束日志lsn。发送数据拷贝完成,判断是否需要发送wal日志文件,若需要,打开pg_wal文件夹,检查为wal文件则加入wallist,如果为时间线历史文件则加入historyFileListlist,释放pg_wal,移除不需要的wal,然后对wallist的文件按时间从旧到新排序,检查队列中的wal的完整性没有缺页,且覆盖了备份数据时统计的起始lsn和结束lsn,一切准备就绪,然后准备循环发送wal文件。然后将历史文件也逐一发送出去,最后发送,结束lsn,一切完成。 do_pg_start_backup函数处理备份基础数据前的操作。首先判断是否处于恢复状态(即是standby)如果是,判断当前备份是否是排他备份,如果是则错误退出,否则,对wal插入排他锁,判断是否是排他备份来改变当前备份回话状态,释放排它锁。调用RequestCheckpoint,强制做一个检查点,对control文件加LW_SHARED,向control文件写入数据,并释放锁,如果是recovery(standby)模式,检查是否可以fullpagewrite,接下来构造表空间映射map,收集所有表空间的信息,构造backuplabel文件,根据是否排他备份设置备份会话状态为是否排他,返回备份的起始lsn。 do_pg_stop_backup函数处理备份基础数据后的操作,首先判断是否处于恢复状态,如果是,则判断当前备份是否是排他备份,如果是则错误退出。入股当前是排他备份,则标记当前备份状态为停止并且删除backuplabel,一处表空间映射map,释放会话状态等锁。如果不在恢复状态(standby),写下备份日志结束日志记录,并强制切换一个新的日志段,返回备份结束的lsn。 RequestCheckpoint请求检查点函数,如果是单独进程,则自己调用CreateCheckPoint函数,创建检查点。否则则向checkpoint进程发送创建检查点信号,让checkpoint进程创建检查点。 CheckpointerMain检查点进程主函数接收到请求检查点命令,首先检查我们应该执行检查点(master)还是restartpoint(standby),如果是执行检查点则调用CreateCheckPoint,是restartpoint则调用CreateRestartPoint。
重做日志发送
重做日志的发送主要是使用流复制原理传送日志 StartReplication 开始物理复制日志,首先检查当前时间线,然后选择开始复制的时间线,如果客户端已经给出,用客户端,否则用当前的最新时间线。检查客户端请求复制的日志起始点,调用WalSndLoop(XLogSendPhysical)循环发送日志。当前时间的日志发送完后,发送下一个时间线指示给客户端,发送结束标识。 WalSndLoop循环发送数据知道当前时间线结束或者客户端发送停止请求。 XLogSendPhysical 发送物理stream给客户端。
针对于pg_basebakcup做的改进
对于pg_basebackup的缺陷,我做了一个新的设计去支持,将两个流并行的输出到同一个标准输出流,我们称作rds_basebackup,它并没有对服务端做任何改动,可以很好的兼容pg_basebackup. 它的主要原理如下图所示:
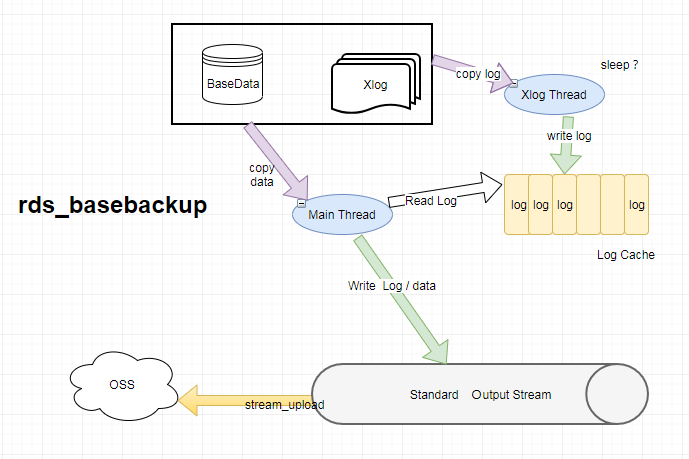
它的主要思想是交叉的备份数据和日志,然后支出输出标准输出流。我使用了两个线程,一个主线程,一个日志线程,主线程发送备份命令,后接收基础备份数据,日志线程发送流复制命令,接收日志。日志线程接收到日志之后就会将一个个完整的日志文件写入日志缓存区,主线程接收一个完整的数据文件后以tar的格式写入标准输出流,然后就去日志缓冲区刷掉所有的缓冲日志,同时每个日志文件以tar的格式写入流。日志线程会在缓存区满了之后睡眠。 这个缓存区我是用的是一个循环双向队列,然后对他的节点加互斥锁,避免主线程读到不完整的数据。这个缓冲区的大小,我提供了参数给用户设置,默认值是24个。
