


对大型表分区
表分区让我们能通过把表划分成较小的、更容易管理的小块来支持非常大的表,例如事实表。 通过让TeleDB-ADB数据库查询优化器只扫描满足给定查询所需的数据而避免扫描大表的全部内容,分区表能够提升查询性能。
关于表分区
分区并不会改变表数据在Segment之间的物理分布。 表分布是物理的:TeleDB-ADB数据库会在物理上把分区表和未分区表划分到多个Segment上来启用并行查询处理。 表分区是逻辑的:TeleDB-ADB数据库在逻辑上划分大表来提升查询性能并且有利于数据仓库维护任务,例如把旧数据移出数据仓库。
TeleDB-ADB数据库支持:
- 范围分区:基于一个数字型范围划分数据,例如按照日期或价格划分。
- 列表分区:基于一个值列表划分数据,例如按照销售范围或产品线划分。
- 两种类型的组合。
图为多层分区设计的例子。
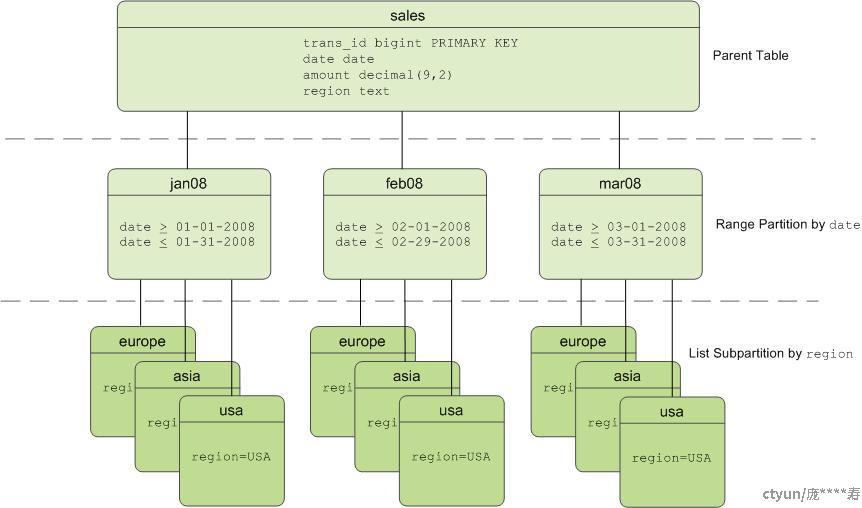
TeleDB-ADB数据库中的表分区
TeleDB-ADB数据库把表划分成部分(也称为分区)来启用大规模并行处理。 表分区在使用PARTITION BY(以及可选的SUBPARTITION BY)子句的CREATE TABLE执行期间进行。 分区操作会创建一个顶层(父)表以及一层或者多层子表。 在内部,TeleDB-ADB数据库会在顶层表和它的底层分区之间创建继承关系,类似于PostgreSQL的INHERITS子句的功能。
TeleDB-ADB使用表创建时定义的分区标准来创建每一个分区及其上一个可区分的CHECK约束,这个约束限制了该表能含有的数据。 查询优化器使用CHECK约束来决定要扫描哪些表分区来满足一个给定的查询谓词。
TeleDB-ADB系统目录存储了分区层次信息,这样插入到顶层父表的行会被正确地传播到子表分区。 要更改分区设计或者表结构,可使用带有PARTITION子句的ALTER TABLE修改父表。
要把数据插入到一个分过区的表中,用户需要指定根分区表,也就是用CREATE TABLE命令创建的那个表。 用户也可以在INSERT命令中指定分区表的一个叶子子表。 如果该数据对于指定的叶子子表不合法,则会返回一个错误。 不支持在DML命令中指定一个非叶子或者非根分区表。
决定表的分区策略
TeleDB-ADB数据库不支持对复制表进行分区(DISTRIBUTED REPLICATED)。 不是所有的哈希分布表或随机分布表都适合于分区。 如果下列问题的答案全部或者大部分都是yes,表分区就是一种可行的改进查询性能的数据库设计策略。 如果下列问题的答案大部分都是no,表分区对于该表就不是正确的方案。 请测试用户的设计策略来确保查询性能能得到预期的改进。
- 表是否足够大? 大型的事实表是进行表划分很好的候选。** 如果在一个表中有几百万或者几十亿个记录,从逻辑上将数据分成较小的块会让用户在性能方面受益。 **对于只有几千行或者更少数据的小表来说,维护分区的管理开销将会超过用户可能得到的性能收益。
- 用户是否体验到不满意的性能? 正如任何性能调节的动机一样,只有针对一个表的查询产生比预期还要慢的响应时间时才应该对该表分区。
- 用户的查询谓词有没有可识别的访问模式? 检查用户的查询负载的WHERE子句并且查找一直被用来访问数据的表列。 例如,如果大部分查询都倾向于用日期查找记录,那么按月或者按周的日期分区设计可能会对用户有益。 或者如果用户倾向于根据地区访问记录,可考虑一种列表分区设计来根据地区划分表。
- 用户的数据仓库是否维护了一个历史数据的窗口? 另一个分区设计的考虑是用户的组织对维护历史数据的业务需求。 例如,用户的数据仓库可能要求用户保留过去十二个月的数据。 如果数据按月分区,用户可以轻易地从仓库中删除最旧的月份分区并且把当前数据载入到最近的月份分区中。
- 数据能否基于某种定义的原则被划分成差不多相等的部分? 尽可能选择将把用户的数据均匀划分的分区原则。 如果分区包含基本同等数量的记录,查询性能会基于创建的分区数量而提升。 例如,通过将一个大型表划分成10个分区,一个查询的执行速度将比在未分区表上快10倍,前提是这些分区就是为支持该查询的条件而设计。
不要创建超过所需数量的分区。 创建过多的分区可能会拖慢管理和维护工作,例如清理、恢复Segment、扩展集群、检查磁盘用量等等。
除非查询优化器能基于查询谓词排除一些分区,否则分区技术不能改进查询性能。 每个分区都扫描的查询运行起来会比表没有分区时还慢,因此如果用户的查询中很少能排除分区,请避免进行分区。 请检查查询的解释计划来确认分区被排除。 参考查询分析获取更多关于分区的信息。
Warning: 请对多级分区格外谨慎,因为分区文件的数量可能会增长得非常快。 例如,如果一个表被按照日和城市划分并且有1,000个日以及1,000个城市,那么分区的总数就是一百万。 列存表会把每一列存在一个物理表中,因此如果这个表有100个列,系统就需要为该表管理一亿个文件。 在选定一种多级分区策略之前,可以考虑一种带有位图索引的单级分区。 索引会降低数据装载的速度,因此推荐用用户的数据和模式进行性能测试以决定最佳的策略。
创建分区表
在使用CREATE TABLE创建表时就可以对它们分区。 这个主题提供了用于创建带有数个分区的表的SQL语法的例子。
对一个表分区:
- 决定分区设计:日期范围、数字范围或者值的列表。
- 选择要按哪个(哪些)列对表分区。
- 决定用户需要多少个分区级别。 例如,用户可以按月创建一个日期范围分区表,然后对每个月的分区按照销售地区划分子分区。
定义日期范围分区表
一个按日期范围分区的表使用单个date或者timestamp列作为分区键列。 如果需要,用户可以使用同一个分区键列来创建子分区,例如按月分区然后按日建子分区。 请考虑使用最细的粒度分区。 例如,对于一个用日期分区的表,用户可以按日分区并且得到365个每日的分区,而不是先按年分区然后按月建子分区再然后按日建子分区。 一种多级设计可能会减少查询规划时间,但是一种平面的分区设计运行得更快。
用户可以通过给出一个START值、一个END值以及一个定义分区增量值的EVERY子句让TeleDB-ADB数据库自动产生分区。 默认情况下,START值总是被包括在内而END值总是被排除在外。例如:
CREATE TABLE sales (id int, date date, amt decimal(10,2))
DISTRIBUTED BY (id)
PARTITION BY RANGE (date)
( START (date '2016-01-01') INCLUSIVE
END (date '2017-01-01') EXCLUSIVE
EVERY (INTERVAL '1 day') );
用户也可以逐个声明并且命名每一个分区。例如:
CREATE TABLE sales (id int, date date, amt decimal(10,2))
DISTRIBUTED BY (id)
PARTITION BY RANGE (date)
( PARTITION Jan16 START (date '2016-01-01') INCLUSIVE ,
PARTITION Feb16 START (date '2016-02-01') INCLUSIVE ,
PARTITION Mar16 START (date '2016-03-01') INCLUSIVE ,
PARTITION Apr16 START (date '2016-04-01') INCLUSIVE ,
PARTITION May16 START (date '2016-05-01') INCLUSIVE ,
PARTITION Jun16 START (date '2016-06-01') INCLUSIVE ,
PARTITION Jul16 START (date '2016-07-01') INCLUSIVE ,
PARTITION Aug16 START (date '2016-08-01') INCLUSIVE ,
PARTITION Sep16 START (date '2016-09-01') INCLUSIVE ,
PARTITION Oct16 START (date '2016-10-01') INCLUSIVE ,
PARTITION Nov16 START (date '2016-11-01') INCLUSIVE ,
PARTITION Dec16 START (date '2016-12-01') INCLUSIVE
END (date '2017-01-01') EXCLUSIVE );
用户不需要为每一个分区声明一个END子句,只需要为最后一个分区写上就好。 在这个例子中,Jan16会在Feb16开始处结束。
定义数字范围分区表
一个按数字范围分区的表使用单个数字数据类型列作为分区键列。例如:
CREATE TABLE rank (id int, rank int, year int, gender
char(1), count int)
DISTRIBUTED BY (id)
PARTITION BY RANGE (year)
( START (2006) END (2016) EVERY (1),
DEFAULT PARTITION extra );
#### 定义列表分区表
一个按列表分区的表可以使用任意允许等值比较的数据类型列作为它的分区键列。
一个列表分区也可以用一个多列(组合)分区键,反之一个范围分区只允许单一列作为分区键。
对于列表分区,用户必须为每一个用户想要创建的分区(列表值)声明一个分区说明。例如:
```
CREATE TABLE rank (id int, rank int, year int, gender
char(1), count int )
DISTRIBUTED BY (id)
PARTITION BY LIST (gender)
( PARTITION girls VALUES ('F'),
PARTITION boys VALUES ('M'),
DEFAULT PARTITION other );
Note:* 当前的TeleDB-ADB数据库传统优化器允许列表分区带有多列(组合)分区键。 一个范围分区只允许单一列作为分区键。 *TeleDB-ADB查询优化器不支持组合键,因此用户不能使用组合分区键。
定义多级分区表
用户可以用分区的子分区创建一种多级分区设计。 使用一个 子分区模板可以确保每一个分区都有相同的子分区设计,包括用户后来增加的分区。 **例如,下面的SQL创建所示的两级分区设计图:
CREATE TABLE sales (trans_id int, date date, amount
decimal(9,2), region text)
DISTRIBUTED BY (trans_id)
PARTITION BY RANGE (date)
SUBPARTITION BY LIST (region)
SUBPARTITION TEMPLATE
( SUBPARTITION usa VALUES ('usa'),
SUBPARTITION asia VALUES ('asia'),
SUBPARTITION europe VALUES ('europe'),
DEFAULT SUBPARTITION other_regions)
(START (date '2011-01-01') INCLUSIVE
END (date '2012-01-01') EXCLUSIVE
EVERY (INTERVAL '1 month'),
DEFAULT PARTITION outlying_dates );
下面的例子展示了一个三级分区设计,其中sales表被按照year分区,然后按照month分区,再然后按照region分区。
SUBPARTITION TEMPLATE子句保证每一个年度的分区都有相同的子分区结构。
这个例子在该层次的每一个级别上都声明了一个DEFAULT分区。
CREATE TABLE p3_sales (id int, year int, month int, day int,
region text)
DISTRIBUTED BY (id)
PARTITION BY RANGE (year)
SUBPARTITION BY RANGE (month)
SUBPARTITION TEMPLATE (
START (1) END (13) EVERY (1),
DEFAULT SUBPARTITION other_months )
SUBPARTITION BY LIST (region)
SUBPARTITION TEMPLATE (
SUBPARTITION usa VALUES ('usa'),
SUBPARTITION europe VALUES ('europe'),
SUBPARTITION asia VALUES ('asia'),
DEFAULT SUBPARTITION other_regions )
( START (2002) END (2012) EVERY (1),
DEFAULT PARTITION outlying_years );
CAUTION:* 当用户创建基于范围的多级分区时,很容易会创建大量的子分区,有一些包含很少的甚至不包含数据。 这可能会在系统表中增加很多项,这些项增加了优化和执行查询所需的时间和内存。 增加范围区间或者选择一种不同的分区策略可减少创建的子分区数量。 *对已有的表进行分区
对已有的表进行分区
表只能在创建时被分区。 如果用户有一个表想要分区,用户必须创建一个分过区的表,把原始表的数据载入到新表,再删除原始表并且把分过区的表重命名为原始表的名称。 用户还必须重新授权表上的权限。例如:
CREATE TABLE sales2 (LIKE sales)
PARTITION BY RANGE (date)
( START (date 2016-01-01') INCLUSIVE
END (date '2017-01-01') EXCLUSIVE
EVERY (INTERVAL '1 month') );
INSERT INTO sales2 SELECT * FROM sales;
DROP TABLE sales;
ALTER TABLE sales2 RENAME TO sales;
GRANT ALL PRIVILEGES ON sales TO admin;
GRANT SELECT ON sales TO guest;
分区表的限制
对于每个分区级别,一个已分区的表最多能有32,767个分区。
一个已分区表上的主键或者唯一约束必须包含所有的分区列。
一个唯一索引可以忽略分区列,但是它只能在已分区表的每个部分而不是整个已分区的表上被强制。
用DISTRIBUTED REPLICATED分布策略创建的表不能被分区。
当一个叶子子分区是外部表时,对分区表有一些限制:
- 针对包含外部表分区的分区表运行的查询将用传统查询优化器执行。
- 外部表分区是一个只读外部表。尝试在该外部表分区中访问或者修改数据的命令会返回一个错误。例如:
-
尝试在外部表分区中改变数据的INSERT、DELETE以及UPDATE命令会返回一个错误。
-
TRUNCATE命令返回一个错误。
-
COPY命令无法复制数据到一个会更新外部表分区的分区表中。
-
尝试从一个外部表分区中复制出数据的COPY命令会返回一个错误,除非用户为COPY命令指定IGNORE
EXTERNAL PARTITIONS子句。
如果用户指定该子句,数据不会被从外部表分区复制出来。
要对一个有外部表作为叶子子表的分区表使用COPY命令,可以使用一个SQL查询来拷贝数据。
例如,如果表my_sales包含一个外部表作为叶子子表,这个命令可以把其数据发送到stdout:
COPY (SELECT * from my_sales ) TO stdout
-
- VACUUM命令会跳过外部表分区。
- 如果在外部表分区上没有数据改变,则支持下列操作。否则,返回一个错误。
- 增加或者删除一列。
- 更改列的数据类型。
- 如果分区表包含一个外部表分区,则不支持这些ALTER PARTITION操作:
- 设置一个子分区模板。
- 更改分区属性。
- 创建一个默认分区。
- 设置一种分布策略。
- 设置或者删除列的一个NOT NULL约束。
- 增加或者删除约束。
- 分裂一个外部分区。
- 如果分区表的一个叶子子分区是一个可读的外部表,ADB数据库工具gpbackup不会从该叶子子分区中备份数据。
加载分区表
在用户创建了分区表结构之后,顶层父表为空。 数据会被路由到底层的子表分区中。 在一个多级分区设计中,只有层次底部的子分区能够包含数据。
不能被映射到一个子表分区的行会被拒绝并且载入会失败。 为了避免无法映射的行在载入时被拒绝,可以为用户的分区层次定义一个DEFAULT分区。 任何不匹配一个分区的CHECK约束的行会被载入到DEFAULT分区。 参见增加默认分区。
在运行时,查询优化器扫描整个表继承层次并使用CHECK表约束来决定要扫描哪个子表分区来满足查询的条件。 DEFAULT分区(如果用户的层次中有一个)总是会被扫描。 包含数据的DEFAULT分区会拖慢总体扫描时间。
当用户使用COPY或者INSERT来载入数据到父表时,数据会被自动路由到正确的分区,这就像是向一个常规表中载入数据一样。
向分区表中载入数据的最佳方法是创建一个中间状态表,把数据载入其中,然后把它交换到用户的分区设计中。参见交换分区。
验证分区策略
当一个表基于查询谓词被分区时,用户可以使用EXPLAIN来验证查询优化器只扫描相关的数据来检查查询计划。
**例如,假设一个sales表被按日期范围分区,先用月份分区然后用地区建立子分区。 对于下列查询:
EXPLAIN SELECT * FROM sales WHERE date='01-07-12' AND
region='usa';
这个查询的查询计划应该展示只涉及到下列表的表扫描:\
- 返回0-1行的默认分区(如果用户的分区设计有一个默认分区)
- 返回0-1行的January 2012分区(sales_1_prt_1)
- 返回若干行的USA地区子分区(sales_1_2_prt_usa)。
下面的例子展示了相关的查询计划片段。\
-> Seq Scan onsales_1_prt_1 sales (cost=0.00..0.00 rows=0
width=0)
Filter: "date"=01-07-12::date AND region='USA'::text
-> Seq Scan onsales_1_2_prt_usa sales (cost=0.00..9.87
rows=20
width=40)
确保查询优化器不会扫描不必要的分区或者子分区(例如,扫描没有在查询谓词中指定的月份或者地区),以及顶层表的扫描返回0-1行。
选择性分区扫描疑难解答
下列限制可能导致一个对用户的分区层次进行非选择性扫描的查询计划。
- 只有当查询包含表的使用不可变操作符,例如 =, < <= , >, >= , 和 <>
的直接或者简单限制时,查询优化器才能有选择地扫描分区表。 - 选择性扫描识别查询中的STABLE以及IMMUTABLE函数,但是不识别VOLATILE函数。 例如,date > CURRENT_DATE这样的WHERE子句导致查询优化器选择性扫描分区表,但是time > TIMEOFDAY不会。
查看用户的分区设计
用户可以使用pg_partitions视图查看有关分区设计的信息。 例如,要查看sales表的分区设计:
SELECT partitionboundary, partitiontablename, partitionname,
partitionlevel, partitionrank
FROM pg_partitions
WHERE tablename='sales';
下列表和视图展示了关于分区表的信息。
- pg_partition - 跟踪分区表以及它们的继承层次关系。
- pg_partition_templates - 展示使用一个子分区模板创建的子分区。
- pg_partition_columns - 显示在一个分区设计中用到的分区键列。
维护分区表
要维护一个分区表,对顶层父表使用ALTER TABLE命令。
最常用的情景是删除旧的分区以及增加新的分区,以此在一种范围分区设计中维护数据的一个滚动窗口。
用户可以把旧的分区转换(交换)成追加优化的压缩存储格式来节省空间。
如果在用户的分区设计中有一个默认分区,用户可以通过分裂默认分区来增加一个分区。
Important: 重要:
在定义和改变分区设计时,要使用给定的分区名而不是表对象名。
尽管用户可以直接使用SQL命令来查询和装载任何表(包括分区表),用户只能使用ALTER
TABLE...PARTITION子句修改一个分区表的结构。
分区并不要求有名称。如果一个分区没有名称,可使用下列表达式之一来指定它:
PARTITION FOR (value)或者PARTITION FOR(RANK(number)。
增加分区
用户可以用ALTER TABLE命令为一个分区设计增加一个分区。
如果原始分区设计包括由一个子分区模板定义的子分区,新增加的分区也会根据该模板划分子分区。例如:
ALTER TABLE sales ADD PARTITION
START (date '2017-02-01') INCLUSIVE
END (date '2017-03-01') EXCLUSIVE;
如果在创建表时没有使用一个子分区模板,用户可以在增加分区时定义子分区:
ALTER TABLE sales ADD PARTITION
START (date '2017-02-01') INCLUSIVE
END (date '2017-03-01') EXCLUSIVE
( SUBPARTITION usa VALUES ('usa'),
SUBPARTITION asia VALUES ('asia'),
SUBPARTITION europe VALUES ('europe') );
当用户为一个现有分区增加一个子分区时,用户可以指定要更改的分区。例如:
ALTER TABLE sales ALTER PARTITION FOR (RANK(12))
ADD PARTITION africa VALUES ('africa');
Note: 用户不能向一个具有默认分区的分区设计中增加分区。* *用户必须分裂默认分区来增加分区。 参见分裂分区。
重命名分区
分区表使用下列命名习惯。分区子表的名称服从唯一性要求和长度限制。
<parentname>_<level>_prt_<partition_name>
例如:
sales_1_prt_jan16
对于自动生成的范围分区,在没有给出名称时会分配一个数字:
sales_1_prt_1
要重命名一个已分区的子表,应重命名顶层父表。在所有相关的子表分区的表名中,\
\<parentname\>都会改变。例如下面的命令:
ALTER TABLE sales RENAME TO globalsales;
会修改相关的表名:
globalsales_1_prt_1
用户可以更改一个分区的名称让它更容易标识。例如:
ALTER TABLE sales RENAME PARTITION FOR ('2016-01-01') TO jan16;
会把相关的表名改为如下:
sales_1_prt_jan16
在使用ALTER
TABLE命令修改分区表时,总是用它们的分区名(jan16)而不是它们的完整表名(sales_1_prt_jan16)引用表。
*Note: 表名不能是一个ALTER TABLE语句中的分区名。 例如,ALTER TABLE
sales\...是正确的。 ALTER TABLE sales_1_part_jan16\...则不被允许。*
#### 增加默认分区
用户可以用ALTER TABLE命令为一个分区设计增加一个默认分区。
```
ALTER TABLE sales ADD DEFAULT PARTITION other;
如果用户的分区设计是多级的,该层次中每一级都必须有一个默认分区。例如:
ALTER TABLE sales ALTER PARTITION FOR (RANK(1)) ADD DEFAULT
PARTITION other;
ALTER TABLE sales ALTER PARTITION FOR (RANK(2)) ADD DEFAULT
PARTITION other;
ALTER TABLE sales ALTER PARTITION FOR (RANK(3)) ADD DEFAULT
PARTITION other;
如果到来的数据不匹配一个分区的CHECK约束并且没有默认分区,该数据就会被拒绝。
默认分区确保到来的不匹配一个分区的数据能被插入到默认分区中。\
#### 删除分区
用户可以使用ALTER TABLE命令从用户的分区设计中删除一个分区。
当用户删除一个具有子分区的分区时,子分区(以及其中的所有数据)也会被自动删除。
对于范围分区,从范围中删除较老的分区很常见,因为旧的数据会被移出数据仓库。例如:
```
ALTER TABLE sales DROP PARTITION FOR (RANK(1));
截断分区
用户可以使用ALTER TABLE命令截断一个分区。 当用户截断一个具有子分区的分区时,子分区也会被自动截断。
ALTER TABLE sales TRUNCATE PARTITION FOR (RANK(1));
交换分区
用户可以使用ALTER TABLE命令交换一个分区。
交换一个分区用一个表换掉一个现有的分区。
用户只能在分区层次的最底层交换分区(只有包含数据的分区才可以被交换)。
不可以交换包含复制表的分区。 不支持使用分区表或分区表的子分区交换分区。
分区交换对数据装载有用。
例如,装载一个分段表并且把装载好的表换入到用户的分区设计中去。
用户可以使用分区交换来把较老分区的存储类型改为追加优化表。例如:
CREATE TABLE jan12 (LIKE sales) WITH (appendoptimized=true);
INSERT INTO jan12 SELECT * FROM sales_1_prt_1 ;
ALTER TABLE sales EXCHANGE PARTITION FOR (DATE '2012-01-01')
WITH TABLE jan12;
Note:* *这个例子指的是表sales的单级定义,就是在前面那些例子对它增加或者修改分区之前。
[Warning:]如果用户指定WITHOUT* VALIDATION子句,用户必须确保用户用于交换现有分区的表中的数据对于该分区上的约束是合法的。 *否则,针对分区表的查询可能会返回不正确的结果。
数据库服务器配置参数gp_enable_exchange_default_partition控制EXCHANGE DEFAULT PARTITION子句的可用性。 该参数的默认值是off,表示该子句不可用,如果在ALTER TABLE命令中指定了该子句,数据库会返回一个错误。
在用户交换默认分区前,用户必须确保要被交换的表中的数据(即新的默认分区)对于默认分区是合法的。 例如,新默认分区中的数据不能含有对分区表其他叶子子分区有效的数据。 *否则,交换过默认分区的分区表上由GPORCA执行的查询可能会返回不正确的结果。
分裂分区
分裂一个分区会把一个分区划分成两个分区。 用户可以使用ALTER TABLE命令分裂分区。 只能在最低层级的分区做分裂(包含数据的分区)。 对于对级别分区,只是范围分区可以分裂,列表分区不行。 用户指定的分裂值会分在后一个分区中。
例如,把一个月度分区分裂成两个,第一个分区包含日期January 1-15而第二个分区包含日期January 16-31:
ALTER TABLE sales SPLIT PARTITION FOR ('2017-01-01')
AT ('2017-01-16')
INTO (PARTITION jan171to15, PARTITION jan1716to31);
如果用户的分区设计有一个默认分区,用户必须分裂该默认分区来增加分区。
在使用INTO子句时,指定当前的默认分区为第二个分区名。
例如,要分裂一个默认的范围分区来为January 2017增加一个新的月度分区:
ALTER TABLE sales SPLIT DEFAULT PARTITION
START ('2017-01-01') INCLUSIVE
END ('2017-02-01') EXCLUSIVE
INTO (PARTITION jan17, default partition);
修改子分区模板
使用ALTER TABLE SET SUBPARTITION TEMPLATE 来修改一个分区表的子分区模板。 在用户设置了新子分区模板之后增加的分区会具有新的分区设计。 现有的分区不会被改变。
下面的例子修改这个分区表的子分区模板:
CREATE TABLE sales (trans_id int, date date, amount decimal(9,2), region text)
DISTRIBUTED BY (trans_id)
PARTITION BY RANGE (date)
SUBPARTITION BY LIST (region)
SUBPARTITION TEMPLATE
( SUBPARTITION usa VALUES ('usa'),
SUBPARTITION asia VALUES ('asia'),
SUBPARTITION europe VALUES ('europe'),
DEFAULT SUBPARTITION other_regions )
( START (date '2014-01-01') INCLUSIVE
END (date '2014-04-01') EXCLUSIVE
EVERY (INTERVAL '1 month') );
这个ALTER TABLE命令修改子分区模板。
ALTER TABLE sales SET SUBPARTITION TEMPLATE
( SUBPARTITION usa VALUES ('usa'),
SUBPARTITION asia VALUES ('asia'),
SUBPARTITION europe VALUES ('europe'),
SUBPARTITION africa VALUES ('africa'),
DEFAULT SUBPARTITION regions );
当用户为表sales增加一个日期范围分区时,它包括非洲的新地区列表子分区。 例如,下面的命令创建子分区usa、asia、europe、 africa以及一个名为other的默认分区:
ALTER TABLE sales ADD PARTITION "4"
START ('2014-04-01') INCLUSIVE
END ('2014-05-01') EXCLUSIVE ;
要查看为分区表sales创建的表,用户可以从psql命令行使用\\dt sales\*。
要移除一个子分区模板,使用带有空圆括号的SET SUBPARTITION TEMPLATE。
例如,要清除sales表的子分区模板:
ALTER TABLE sales SET SUBPARTITION TEMPLATE ();
用外部表交换叶子子分区
用户可以用一个可读的外部表交换一个分区表中的一个叶子子分区。 外部表数据可以位于一个主机文件系统、一个NFS挂载或者一个Hadoop文件系统(HDFS)。
例如,如果用户有一个分区表,它按月被分成月度分全局并且对该表的大部分查询值访问较新的数据,用户可以把较旧的、较少访问的数据拷贝到外部表并且把较旧的分区与这些外部表交换。 对于之访问较新数据的查询,用户可以创建使用分区排除的查询来防止扫描较旧的、不需要的分区。
如果分区表含有一个带检查约束或者NOT NULL约束的列,用一个外部表交换一个叶子子分区是不可以的。
关于交换和修改一个叶子子分区的信息,请见ALTER TABLE命令。
关于含有外部表分区的分区表的限制,请见分区表的限制。
用外部表交换分区的例子
这是一个简单的例子,它把这个分区表的一个叶子子分区交换为一个外部表。分区表包含2010至2013年份的数据。
CREATE TABLE sales (id int, year int, qtr int, day int, region text)
DISTRIBUTED BY (id)
PARTITION BY RANGE (year)
( PARTITION yr START (2010) END (2014) EVERY (1) ) ;
该分区表有四个叶子子分区。 每一个叶子子分区含有单一年份的数据。
叶子子分区表sales_1_prt_yr_1包含2010年的数据。
这些步骤把表sales_1_prt_yr_1交换为一个使用gpfdist协议的外部表:
-
确保ADB数据库系统启用了该外部表协议。
下面例子使用了gpfdist协议。可以使用命令开始gpfdist协议。 -
创建一个可写的外部表。
下面CREATE WRITABLE EXTERNAL TABLE命令用和分区表相同的列创建一个可写的外部表。CREATE WRITABLE EXTERNAL TABLE my_sales_ext ( LIKE sales_1_prt_yr_1 ) LOCATION ( 'gpfdist://gpdb_test/sales_2010' ) FORMAT 'csv' DISTRIBUTED BY (id) ; -
创建一个可读的外部表,它从前一步创建的可写外部表的目的地读取数据。
下面CREATE EXTERNAL TABLE创建一个可读外部表,它使用和可写外部数据相同的外部数据。CREATE EXTERNAL TABLE sales_2010_ext ( LIKE sales_1_prt_yr_1) LOCATION ( 'gpfdist://gpdb_test/sales_2010' ) FORMAT 'csv' ; -
从叶子子分区中拷贝数据到该可写外部表。
INSERT INTO my_sales_ext SELECT * FROM sales_1_prt_yr_1 ; -
用该外部表交换现有的叶子子分区。
ALTER TABLE sales ALTER PARTITION yr_1 EXCHANGE PARTITION yr_1 WITH TABLE sales_2010_ext WITHOUT VALIDATION;以表名sales_1_prt_yr_1成为叶子子分区的外部表,并且旧的叶子子分区变成表sales\_-2010_ext。 *[Warning:]{style="color: codered"} 为了确保针对分区表的查询返回正确的结果,外部表数据必须针对叶子子分区上的CHECK约束有效。 在这种情况下,数据会从其上定义有CHECK约束的叶子子分区表中取出*。 -
删除移出分区表的表。
DROP TABLE sales_2010_ext ;
用户可以重命名该叶子子分区的名称来表明sales_1_prt_yr_1是一个外部表。
下面命令把分区名改为yr_1_ext把叶子子分区表的名称改为sales_1_prt_yr_1_ext。
ALTER TABLE sales RENAME PARTITION yr_1 TO yr_1_ext ;
