


谷歌于2017年提出了一种新的神经网络算法:transformer,它与传统的神经网络算法的区别主要是注意力机制(self-attention)。比如在自然语言处理时,模型会评估句子中各个词的重要性,从而根据上下文锁定关键信息,提高下一阶段的文本预测与建模能力。
-
整体流程介绍
Transformer主要由Encoder和Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block,整体结构如下所示:

简单介绍一下工作流程:
第一步:获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(从原始数据中提取出来的Feature) 和表示单词位置的 Embedding 相加得到。
第二步:将得到的单词表示向量矩阵传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,单词向量矩阵用 X(n×d)表示, n 是句子中单词个数,d 是表示向量的维度。
第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词i 翻译下一个单词 i+1。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
self-Attention
下方给出encoder-decoder的流程图:
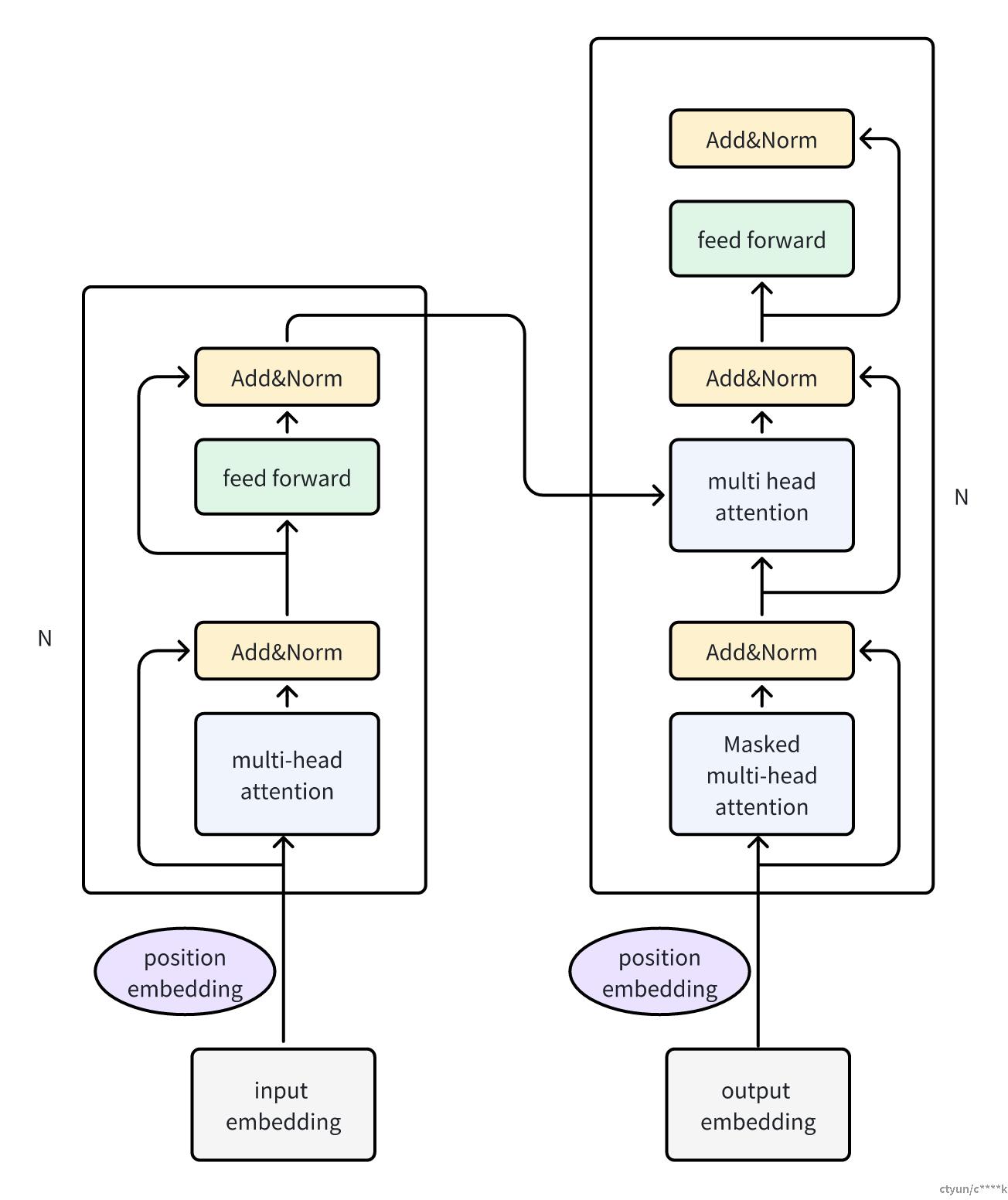
transformer 中encoder的每个block的组成如上图左侧所示,decoder的每个block则如右侧所示。可以看出,encoder中有一个Multi-Head Attention,其中Multi-Head Attention是由多个 Self-Attention组成的;而 Decoder block 则包含两个 Multi-Head Attention (其中有一个用到 Masked)。
self-attention是整个transformer的核心,我们重点看一下它的具体结构,如下图:
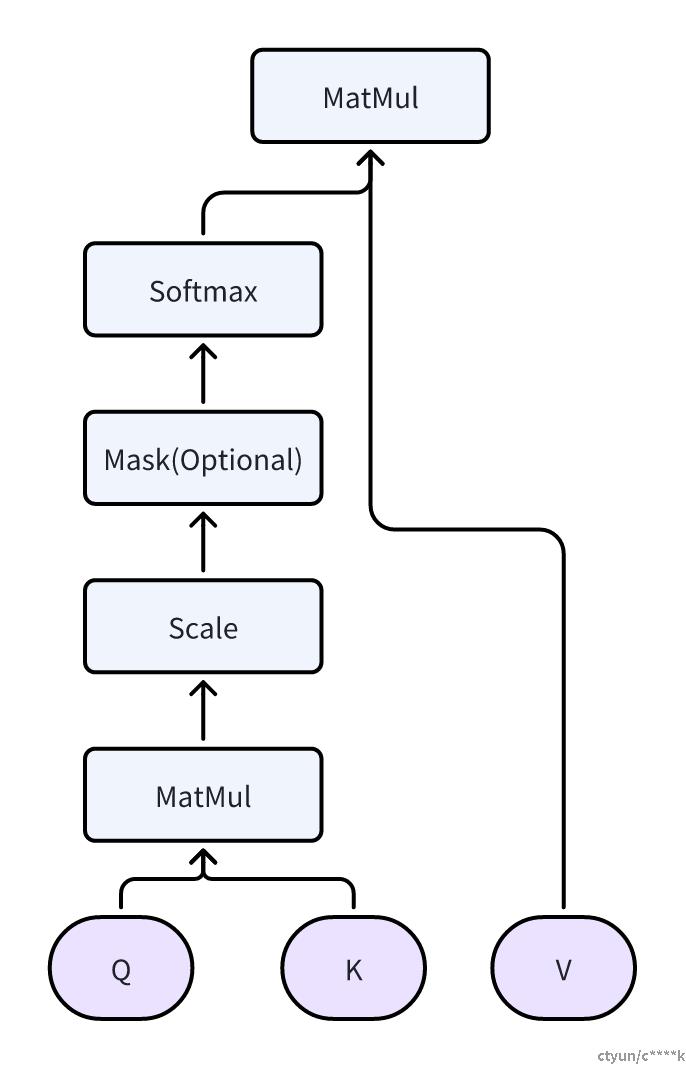
整个计算过程需要用到矩阵Q(查询),K(键值),V(值),Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出,Q,K,V都是通过 Self-Attention 的输入进行线性变换得到的。
如前所述,输入矩阵X是N*d的矩阵,N代表N个单词,即矩阵的每一行都代表一个单词。分别与WQ/WK/WV矩阵相乘,得到QKV三个矩阵, 同样都是N行,每一行代表一个单词。
将Q与K的转置矩阵相乘,得到N*N的矩阵,可以视作单词之间的attention矩阵。再除以它们列数的平方根,避免内积过大。再应用softmax,进行归一化处理,表示出每个单词与其它单词的attention系数值。
最终与矩阵V相乘,得到整个输出矩阵Z。Z依然是N行,列数取决于之前的WV矩阵的列数,这里记为Y。
事实上,transformer应用的往往是multi-attention机制,即输出M个Z矩阵,将它们按列拓展,最终是N行,M*Y列的矩阵。进行一个线性变换,乘以一个M*Y行,d列的矩阵,得到最终的输出矩阵:N行d列,同最初的X矩阵相同,这样可以再次作为下一个阶段的输入矩阵X。
Encoder
Encoder由多个block组成,而对于每个block,除了核心的self-attention,还有add-norm和feed forward 过程。
add过程:输入矩阵X+multi-head(X),或者X+feed-forwar(X),矩阵结构不变。它是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分
norm过程:对add后的结果进行Layer Normalization,相当于将输入的每一层都转成均值方差都一样的,这样可以加快收敛。
Feed-forward则是两层全连接层的结构,其中第一层使用了RELU的激活函数。
多个block组成的encoder,最终的输出矩阵记为编码信息矩阵 C,由前已知,矩阵结构与输入矩阵X相同,n*d。
Decoder
decoder相比encoder,它有两处multi-head操作。
第一个 Multi-Head Attention 层采用了 Masked 操作,它在QKV的计算过程与encoder相同,但是在Q与K的转置相乘得到n*n的注意力矩阵后,先将mask矩阵(下三角矩阵)与之相乘,这样可以让结果矩阵中,第一行任一位置的信息都只得到矩阵X第一行的相同位置的信息;而第二行任一位置则可以得到X的一二行相同位置的信息;这样完成masked操作:每一个单词(对应每一行的信息)都只利用上文,而不使用下文。该掩码矩阵得到后,再进行前述的归一化操作,及与Z矩阵相乘。
第二个 Multi-Head Attention 层的K,V矩阵则使用前述Encoder阶段输出的矩阵C进行计算,Q使用上一个 Decoder block 的输出计算(第一个 Decoder block 则使用输入矩阵 X 进行计算)。其它流程与encoder相同。
最后的Softmax 层计算下一个翻译单词的概率。
小结
Transformer 相比与RNN最大的优势是并行计算,它通过在初始矩阵里加入位置embedding的方式,来实现矩阵计算的无序化,可以提升计算效率。 在Decoder阶段,又通过掩码的方式,翻译单词的过程中又只利用前序阶段,而避免收到后续影响。但对于Decoder阶段,每次block的输入矩阵Q都是前序block的输出矩阵,所以多次block计算之间是不能并行的。
Transformer中最大的特点就是注意力机制,通过线性变换来计算QKV矩阵,并且通过通过多注意力的方式来提升不同单词之间的相关性系数。
