


1.前言
Continous Batching提出于论文《Orca: A Distributed Serving System for Transformer-Based Generative Models》,因其可以实现数倍乃至数十倍的系统吞吐提升,已广泛被各大LLM推理框架采用(原名Iteration Batching,TGI和vLLM称之为Contious Batching,TensorRT-LLM称之为In-flight Batching)。
笔者曾阅读几篇关于Continous Batching的解读,始终觉得对运行机制的理解不够透彻,因而自己看论文做了这篇解说。
2.解决的3个问题
- 对Early-finished Requests的处理。不同请求所生成的文本长度不一致,可能差别很大,并且不易预测。如果没有一个将已生成结束的请求从Batch中移除并提前返回结果的机制,那么只能等一个Batch内所有请求都完成生成后才返回生成结果,导致生成短文本的用户则需要多“陪跑”数秒到数十秒才能得到结果,这对于服务响应时间是不利的;
- 对Late-joining Requests的处理。完整生成一段文本需要长达数秒或数十秒的时间,是漫长的。所以如果没有一个将新请求插入到推理Batch的机制,那么只能像CV业务那样,等前面的请求都完成推理了才进行后续请求的推理。这会导致请求需要在系统中长时间等待排队,表现为服务响应时间过长甚至不可接受;
- Batching an arbitrary set of requests( 指将一组不同请求,例如不同长度的输入序列组合在一起进行批量处理 )。每个请求对应的QKV Tensor的Length维度各不相同,在批量计算Attention时,需要处理此问题。 诚然Padding+Masking的方法可以解决,但严重浪费算力和显存,对于算力和显存均有限的推理GPU是不利的。
(补充解释:Padding+Masking 是一种常用的方法,用来统一这些序列的长度,以便进行批量计算。具体来说:
- Padding:通过在较短的序列后面添加特殊的填充(padding)符号,使所有序列的长度相同。
- Masking:在计算注意力时,对这些填充符号进行遮蔽(mask),使其不会对计算结果产生影响。
尽管这种方法可以解决序列长度不一致的问题,但它也会导致计算资源的浪费,因为填充部分并不包含有效信息,却仍然占用了显存和计算资源。在算力和显存有限的推理GPU上,这种浪费是很不利的。)
3.算法解说
3.1. 示意图
所谓“一图胜千言”,FriendliAI(ORCA作者单位之一)用一个动图诠释了Continous Batching的精华。
3.2.Early-Finished 和 Late-Joining的解决
为了更好地解决Early-Finished 和 Late-Joining,ORCA提出了Iteration-level Scheduling。笔者对其做了密集注释,应该很清晰了

ORCA版Iteration-level Scheduling的算法描述
解决问题的关键点是:CLM(Casual Language Modeling)模型(典型如GPT系列),并不是一次推理就能生成全部的文本,而是像下图那样迭代式地调用GPU推理生成每一个Token。因此在每次GPU推理的空隙,可以插入调度操作,实现Batch样本的增删和显存的动态分配释放(这就是论文提出的核心思想:Iteration-level Scheduling)。具体而言,Early-finished 的问题通过算法描述中第13~14行的逻辑解决(还应有request出队列的逻辑,但没有描述),而Late-joining 的问题通过算法描述中第23~27行的逻辑解决。
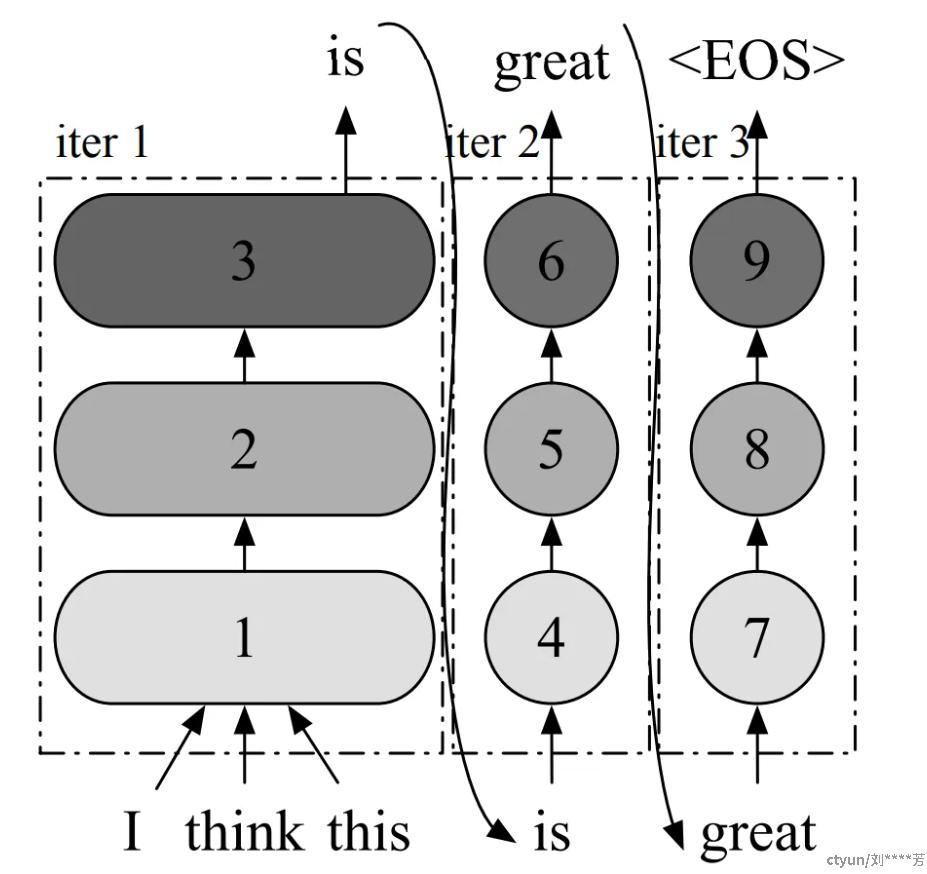
这是一个表示使用 GPT 模型进行推理过程的计算图。为了简化,该图未描绘除 Transformer 层之外的其他层(例如嵌入层)
3.2.Batching An Arbitrary Set of Requests的解决
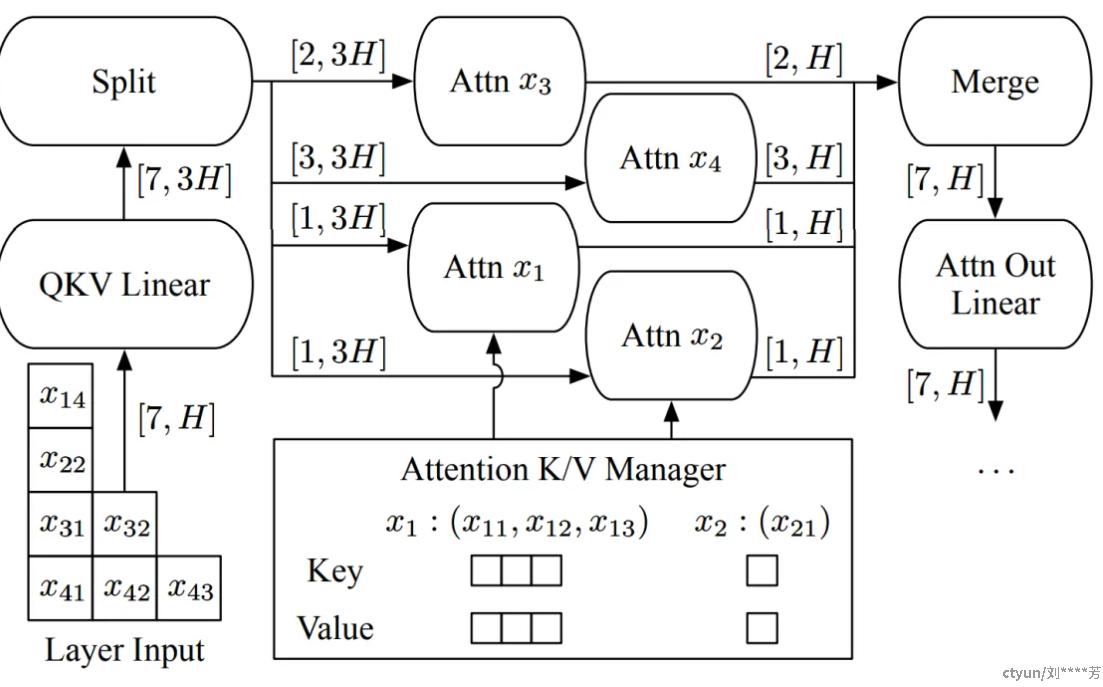
OCRA解决这个问题的思路没啥特别的,上图就可以说的很明白了,笔者稍微做下解读:
- 示意图描述的是,系统正在生成请求x3、x4的第1个Token(论文称为Initiation Phase),同时生成请求x1、x2的后续Token(论文称为Increment Phase)。因为产生第1个Token后才会有K/V Cache,所以从Attention K/V Manager那里看有没有request对应的K/V cache,就能分辨出每个request处于哪个phase;
- Linear的计算不涉及Token之间的交互,因此将输入的Batch维度和Seq维度Reshape成1个维度,即可完成Linear的Batch计算(注:有的读者可能会疑惑为什么Linear的输入和输出维度分别是[7,H]和[7,3H],为什么升维了?这是因为通过矩阵拼接可以实现用一个Linear同时计算出QKV,即输出包含了有H维的Q、H维的K和H维的V,合计3H维);
- Attention的计算设涉及Token之间的交互,OCRA的操作是:将输入按Batch维Split,每个样本分别计算Attention,最后再将结果Merge在一起。
4.实验结果
因为大模型推理发展迅速,比如ORCA发表时被比下去的框架现在也用上了Continous Batching,还加入了其他的优化方法(比如Paged Attention),所以实验结果有明显的时效性问题,笔者不做过多解读。
5.存在的不足和后续改进
作者关注过一些针对原版Continous Batching(即OCRA版)某些细节做的改进,在这里列一下:
1. 对Canceled Requests(部分请求已要求中止生成)的处理。对于这些请求应及时从Batch中剔除并释放相应显存,但ORCA版没有提及。现在流行的推理框架都应补全了这块逻辑,例如TGI中Filtering的服务逻辑包含了对Canceled Requests的清除。
2. 拆分Initiation Phase(又称Prefill)和Increment Phase(又称Decode)。OCRA版把这2个阶段合并在一起做,但其实它们的计算模式差很多,分开做能够更好地做优化(例如计算Linear时,Initiation Phase的计算Kernel更接近GEMM,Increment Phase的计算Kernel更接近GEMV)。以TGI为例,它的改动是将Initiation Phase的请求批量做完计算后,再这些请求与已在Increment Phase的请求合并做批量计算。
3.优化K/V Cache的释放机制或时机。ORCA版在请求生成结束时就立即释放其K/V Cache。在多轮对话场景中,这个机制会导致冗余计算,即“上一轮对话生成K/V Cache → 释放K/V Cache显存 → 通过本轮对话的Prompt生成 之前的K/V Cache”。这样会恶化后续几轮对话的First Token Time(产生第一个Token的时延)指标(很明显后面的Prompt会非常长,算力一下就吃满了)。
4. 优化时延抖动问题。Contious Batching增大了整个系统的吞吐,但可能会给单个用户的体验带来一些小问题:在自己请求的文本生成过程中,如果有新的请求进来就会一起加入生成计算中。因为BatchSize在动态变化,计算时延会有比较明显的波动——这会让用户产生LLM系统卡顿或忽快忽慢的感觉。这个小问题在产品上还是容易解决的,例如笔者留意过某些国产LLM会在一些合适的地方主动作停顿,做一下缓冲(例如生成冒号或分号后停一下,模拟人类分点讲述时的必要停顿)。技术上的解决方案也有,例如有一位大神把解决时延抖动的关键定位在Prefill阶段,通过将Prefill阶段拆分为多次完成来削弱对时延的影响,同时因为拆分对齐了某些特定维度,使算力得到更好的发挥。
