


DLRover 是什么
- DLRover:蚂蚁开源的大规模智能分布式训练系统
- github.com/intelligent-machine-learning/dlrover
- 蚂蚁集团 AI Infra 团队维护的开源社区,是基于云原生技术打造的智能化分布式深度学习系统
- DLRover 使得开发人员能够专注于模型架构的设计,而无需处理任何工程方面的细节,例如硬件加速和分布式运行等。
DLRover的目标
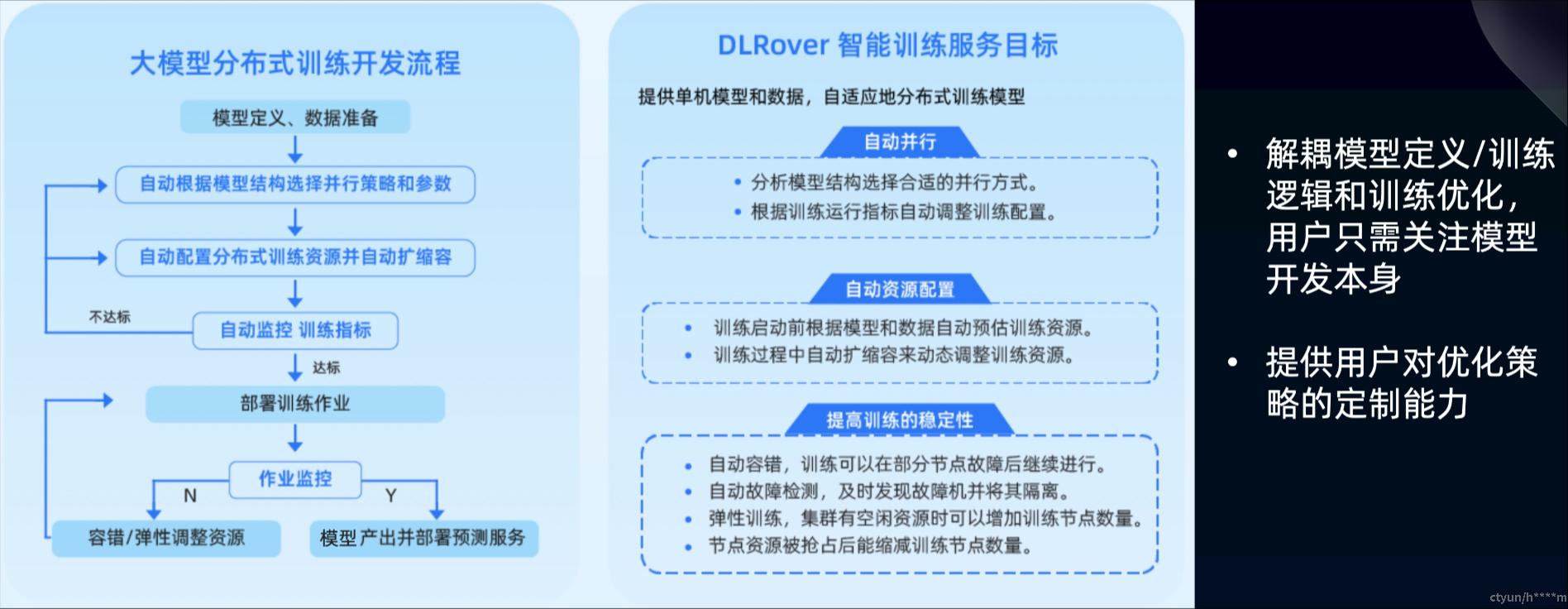
DLRover能力
-
自动资源推导:帮助用户自动初始化训练资源,提升资源利用率与作业稳定性。
-
动态训练数据分片:针对不同 Worker 性能不通造成的木桶效应,根据实际消费速度分配训练数据,可配合 Failover 记录消费位点,数据不丢失。
-
单点容错:提供单点容错的能力,不需要完整重启作业。
-
资源弹性:支持运行时 Pod 级和 CPU/Memory 级的资源弹性扩缩容,动态全局优化决策。
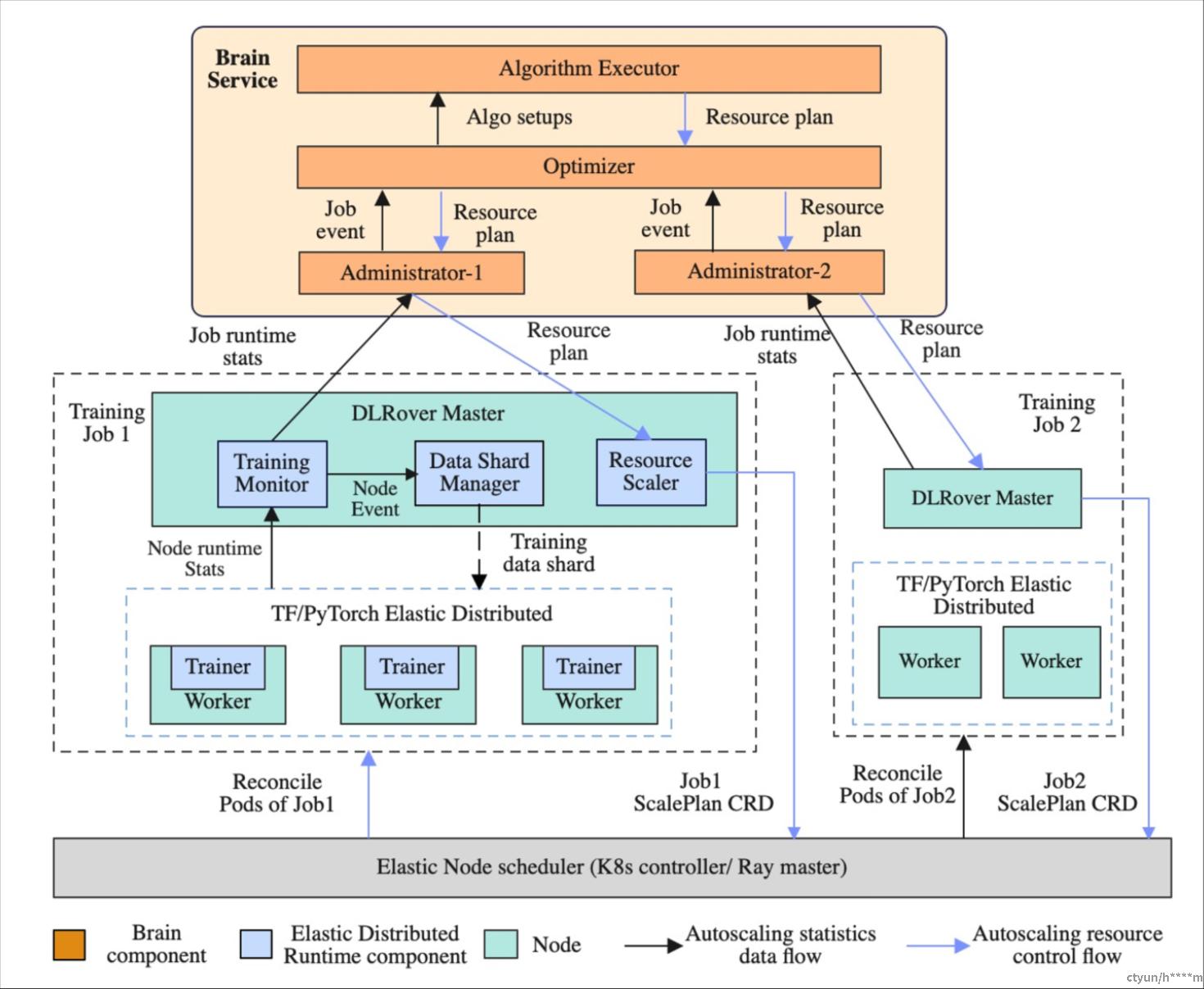
整体架构
DLRover 由四个主要组件组成:
-
ElasticJob
-
Elastic Trainer
-
Brain 服务
-
Cluster Monitor
组件-ElasticJob
-
ElasticJob 负责管理和调度分布式机器学习任务
-
服务是一个Operator
-
提前安装在集群内
-
golang开发
组件-Elastic Trainer
-
Elastic Trainer 是负责实际执行机器学习训练任务的组件
-
master pod(由Operator 创建)
-
worker pod(由master pod创建)
-
python开发
组件-Brain服务
- Brain Service: 负责资源自动优化。基于实时采集的训练速度和各个节点负载来自动优化作业的资源配置。
-
服务单独部署,属于可选服务
-
可选服务,默认不触发
-
只有在job的yaml中写了optimizeMode:cluster才会触发Brain服务
-
golang开发
组件-Cluster Monitor
- Cluster Monitor:用于监控和管理集群资源及节点状态
-
已实现的监控:
-
资源使用情况(CPU、内存和 GPU)
-
全局步数
-
节点心跳
-
集成在ElasticTrainer的agent中
-
python开发
