


Abstract
问题:
- GPU显存大小限制,分布式多卡也不行(有的大模型)
- 训练时间长
- tensor和pipline并行不能在千卡训练的时候简单的使用
本文展示了如何在千卡训练时,使用张量、pipline和数据并行,提出了interleaved pipelining schedule使得吞吐量提升10%(内存占用不变),方法允许在3072个gpu上以502petaFLOP/s的速度对具有1万亿参数的模型执行训练迭代(每gpu吞吐量为理论峰值的52%)。
1 Introduction
可以通过GPU设备和主机之间的参数传输和交换可以减少一些GPU显存的占用
Data-parallel scale-out(数据并行扩展)可以对训练时长上有帮助,但有两大限制:
- 模型大了之后,每一个GPU的batch变得很小,会导致GPU利用率降低并导致通信成本增加
- 可以使用的最大设备数量是批处理大小,限制了可用于训练的加速器数量
模型(tensor)并行来解决数据并行上的限制,但也会引入两大限制:
- 张量并行中all-reduce通信需要通过服务器的链路,这个比GPU的nvlink的带宽要慢很多
- 高度的模型(张量)并行会创建一些小的矩阵乘法(GEMMs),潜在降低GPU的利用率。
模型(pipline)并行是指模型的层在多个GPU上进行剥离(分层),将batch分割成更小的批处理以流水线方式并行。无论进度如何,为了保持严格的优化器语义,需要跨设备同步优化器步骤,从而在每个批处理结束时刷新管道,允许微批处理完成执行(并且不注入新的微批处理)。
- 50%的时间用于冲洗pipline
- 更大的batch size,pipline刷新时间越短(本文引入新的piline来提高small btach size的效率)
本文解决的问题:如何结合并行技术来最大限度地提高给定批量大小(减少跨节点通信)的大型模型的训练吞吐量,同时保持严格的优化器语义?
pipline, tensor, data parallelism(PTD-P)结合,在千卡上峰值设备吞吐量达到(52%)
- 163 teraFLOP/s每张GPU
- GPT模型吞吐量(throughput) 502 petaFLop/s
研究影响吞吐量的多个部分,配置分布式训练的指导原则:
- 并行化策略会影响通讯量、执行内核时的计算效率,以及管道刷新导致的等待计算的空闲时间;张量并行对多GPU服务器是有效的,pipeline并行必须用于更大的模型
- pipeline并行的调度对通信量、pipeline的bubble大小和用于存储activations的内存占比都有影响。(提出新的交错调度提升10%吞吐量)
- 超参数(如microbatch size)会影响内存占用、内核的计算效率以及pipeline的bubble size。(微批量大小的最佳值可以提升15%吞吐量)
- 使用较慢的节点间互联或通信密集的分区会影响扩展性能。(892GB/s用于管道并行,13TB/s用于数据并行)
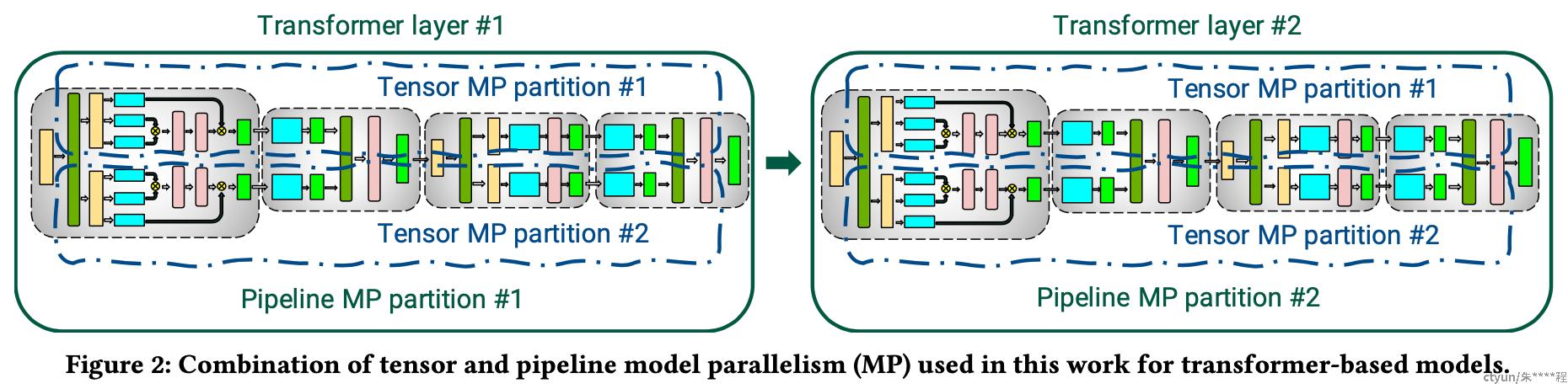
2 Modes of Parallelism
pipeline并行,tensor并行,数据并行(PTD-P)
数据并行
每一个worker都有完整的模型副本,输入数据集分片,worker定期汇总他们的梯度确保权重一致。大模型在较小的模型分片上使用DP。
- 在GPU中超过某个阈值后,每一个GPU上分配的microbatch过小,会导致单块GPU利用率降低,而通讯成本大大增加。
- 理论上最多支持并行的GPU数量等于batch size,这个限制了训练中可以使用的卡的规模。
流水线并行
模型的层被分散到多个GPU上,重复相同的transformer(不同的layer)会平分到每一个GPU上;batch分成micro-batch之间进行流水线执行,确保输入在前向和后向传递中看到一致的权重。为了保留严格的优化器语义,引入周期性的流水线刷新来保证不同设备之间优化器的同步。
- 流水线并行中,micro batch的数量/pipline尺寸(并行使用的GPU数量)越大,通常pipeline flush消耗的时间则越小。
pipeline bubble:在每个批处理开始和结束时,设备处于空闲状态
Gpipe调度跨设备的前向和后向microbatch,每个方法在pipeline bubble、通信和内存占用之间提供不同的权衡。
