


Greenplum整体架构
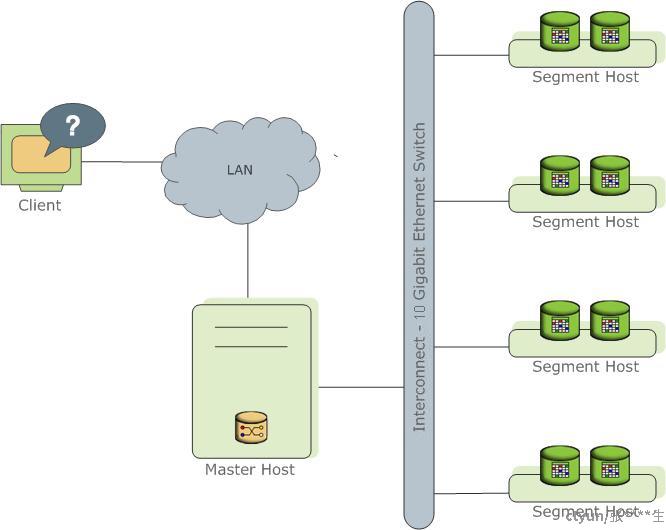
Greenplum数据库通过将数据和处理负载分布在多个服务器或者主机上来存储和处理大量的数据。Greenplum数据库是一个由基于PostgreSQL的数据库组成的集群,集群中的数据库协同工作,对外呈现了一个单一数据库的景象。Master是Greenplum数据库系统的入口。客户端会连接到这个数据库实例并且提交SQL语句。Master会协调与系统中其他称为Segment的数据库实例一起工作,Segment负责存储和处理数据。如图所示。
-
Master
Greenplum数据库的Master是整个Greenplum数据库系统的入口,它接受连接和SQL查询并且把工作分布到Segment实例上。
Greenplum数据库的最终用户与Greenplum数据库(通过Master)交互时,会觉得他们是在与一个典型的PostgreSQL数据库交互。他们使用诸如psql之类的客户端或者JDBC、ODBC、libpq(PostgreSQL的C语言API)等应用编程接口(API)连接到数据库。
Master是全局系统目录的所在地。全局系统目录是一组包含了有关Greenplum数据库系统本身的元数据的系统表。Master上不包含任何用户数据,数据只存在于Segment之上。Master会认证客户端连接、处理到来的SQL命令、在Segment之间分布工作负载、协调每一个Segment返回的结果以及把最终结果呈现给客户端程序。
-
Segment
Greenplum数据库的Segment实例是独立的PostgreSQL数据库,每一个都存储了数据的一部分并且执行查询处理的主要部分。
用户定义的表及其索引会分布在Greenplum数据库系统中可用的Segment上,每一个Segment都包含数据的不同部分。服务于Segment数据的数据库服务器进程运行在相应的Segment实例之下。
-
Interconnect
Interconect是Greenplum数据库架构中的网络层。
Interconnect指的是Segment之间的进程间通信以及这种通信所依赖的网络基础设施。
默认情况下,Interconnect使用带流控制的用户数据包协议(UDPIFC)在网络上发送消息。Greenplum软件在UDP之上执行包验证。如果Interconnect被改为TCP,Greenplum数据库会有1000个Segment实例的可扩展性限制。默认协议UDPIFC则不存在这种限制。一条SQL的查询过程
一条SQL,从postgresql接收到文本起,会经历如下阶段:
-
进行语法分析,生成语法树
简单的产生raw parse tree,这个里面不涉及语义检查。只是做语法扫描
-
语义分析和查询重写
会进行语义分析,会访问数据库中的对像,将涉及到的数据库对象转换为内部表示。
-
生成查询计划
-
执行查询
Greenplum的查询计划
查询计划是数据库为了实施一个查询所进行的一系列操作。计划中的每个步骤(也叫节点,Node)都代表了一个数据库操作,比如表扫描,连接操作,聚合操作,排序等。当涉及到数据的join、聚合之类的操作时,Greenplum还提供了一种特殊的操作,叫Motion。一个motion代表了查询的时候,数据元组在segment之间的移动。并不是每个查询都会产生motion操作。
为了在查询执行期间实现最大的并行度,Greenplum将查询计划的工作划分为slices。slice是计划中可以独立进行处理的部分。当查询计划包含motion时,也会生成slice,motion的每一侧都有一个slice。
考虑下面的关联查询:
SELECT customer, amount
FROM sales JOIN customer USING (cust_id)
WHERE dateCol = '04-30-2016';
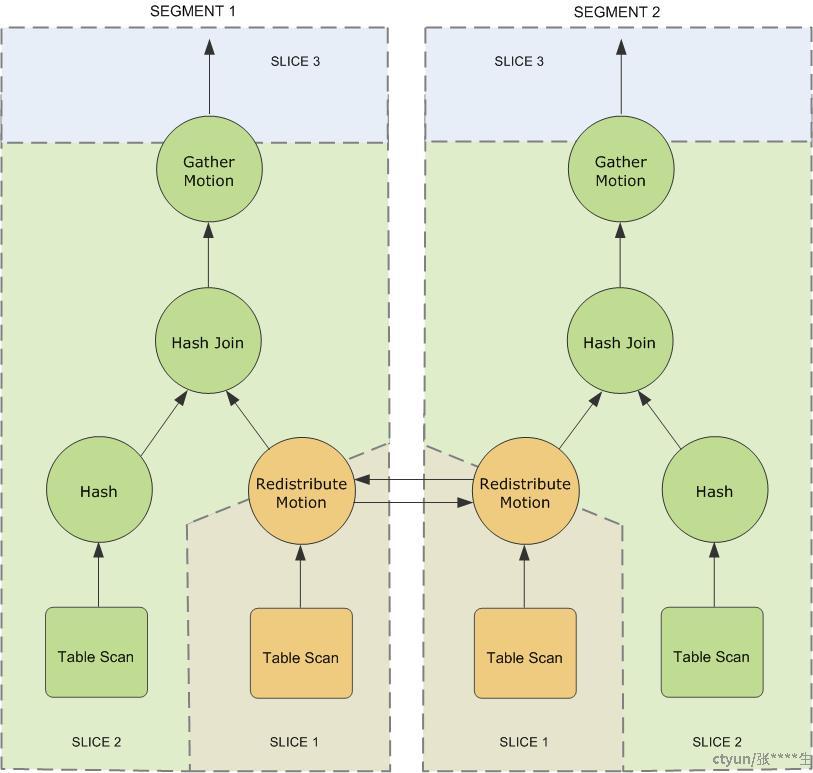
上图展示了这个查询的查询计划. 每个segment
接收到查询计划的一份拷贝,然后执行.
在这个查询计划中,为了完成join操作,有一个数据重分布( redistribute
)motion,是因为在customer表中,数据是按照cust_id进行分布的,而sales表是按照sale_id分布的。为了完成关联操作,我们必须把sales表的数据按照cust_id重新分布。在motion的两个,产生了两个slice,即slice
1 and slice 2。 查询计划中还有另外一个motion: gather
motion。当所有的segment把结果发给master返回给客户端的时候就会产生一个
gather motion。
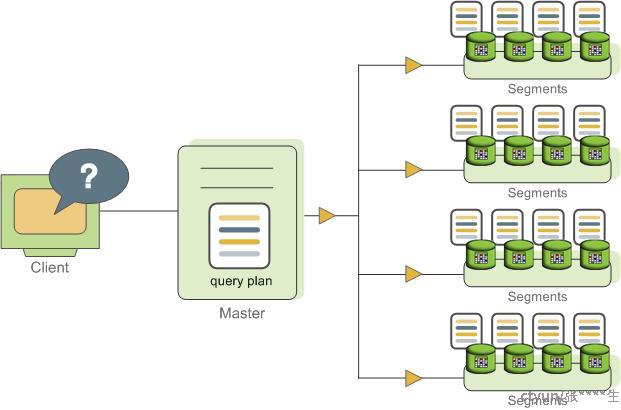
查询计划分发
Master接收客户端发来的查询语句,对之进行解析与优化,生成查询计划。查询计划可能是并行的(Parallel)或者定向的(Targeted)。并行指的是master将生产的查询计划发往所有的segments,如下图所示
Targeted指的是master将生产的查询计划发往特定的一个segment,如下图所示
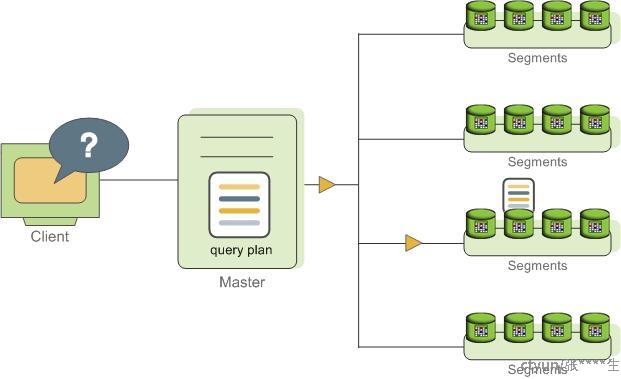
大多数的数据库操作,比如表的扫描,表关联,聚合操作以及排序等都涉及到在所有的segments上并发进行。有一些特定的操作,会在单个segment上执行,比如单行的insert,update,delete等。而在指定分区上的Select查询,查询则会被派发到具有指定分区的数据的segment上执行。
查询计划执行
Greenplum会Fork相应的后台进程来处理查询。在Master进程上,Fork出来处理查询的进程被称为query
dispatcher(QD)。QD主要负责生成与分发查询计划。,同时收集最终的结果,返回给客户端。在segments侧,每个查询进程称为
query executor
(QE)。每个QE负责完成部分查询工作以及将中间结果发送给其他进程。
在Greenplum中,执行相同分片的一组segment进程称为一个Gang。当查询计划的一个slice在一个Gang执行完毕,tuples就会从一个Gang流转到另外一个Gang。Segment之间的数据通信由interconnect组件完成。
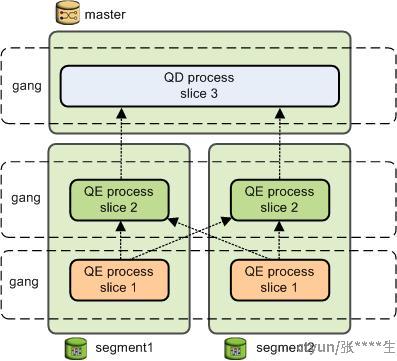
查询计划涉及到的组件
-
节点
-
Master节点
一个集群只有一个Master,Master可以有一个备用节点。通过流复制实现master的高可用
-
Segment节点
一个集群可以有多个segment。
在高可用集群中,每个segment有一个primary节点和mirror节点.
-
-
进程
-
Postmaster进程
每个Greenplum集群有一个postmaster进程.
-
Utility 进程
Utility 进程按照功能有: bgwriter(data writer), Stats Collector
Process, ftsprobe(only master, heartbeat service),
seqserver(only master, global sequence), Logger -
Backend 进程
Master监听来自客户端的请求,然后fork一个后端子进程来处理客户端请求。Master
Fork出来的后端进程又称为 QD(Query
Dispatcher)。同理,Segment节点也会Fork后端子进程来处理请求,这些后端子进程称为QE(Query
Executor)
-
-
MPP处理
-
Motion
在Greenplum,为了处理节点之间的数据移动引入的算子,这些算子用来接收或者发送数据。主要有Gather
Motion,Broadcast Motion以及Redistribute motion。 -
Slice
查询计划中可以在单个节点执行部分。
查询计划被Motion拆分成不同的Slice。一个分布式查询计划一般有多个Slice。 -
Gang
执行同一个Slice的多个QE称为一个Gang。
-
查询执行具体步骤
Master接收客户端的请求,分发查询计划到各个segments,segment加载数据,返回数据给Master,Master返回数据到Client。一般都会经历如下步骤:
- Master监听端口, 客户端连接Postmaster进程
- Postmaster fork 子进程QD (Query Dispatcher process)
- Clien向QD发送查询请求
- QD查询解析、分析以及重写
- QD生成查询计划
- QD准备查询计划执行环境(gangs, 分配QEs and 建立interconnects连接等)
- QD下发计划到QE进程
- QE准备执行
- QE执行查询计划
- QEs之间数据交换
- QE返回结果给QD
接下来的章节会针对源码进行梳理,敬请关注。
未完待续
