


Kafka事务的目的
-
Exactly Once
-
操作的原子性
-
有状态操作的可恢复性
kafka的幂等性可以实现Exactly Once语义,幂等性提供了单会话单分区的Exactly-Once 语义的实现,幂等性实现是事务性实现的基础。Kafka在引入幂等性之前,Producer向Broker发送消息,然后Broker将消息追加到消息流中后给Producer返回Ack信号值。实现流程如下:

然而实际生产环境中会出现各种不确定的因素,比如在Producer在发送给Broker的时候出现网络异常。比如以下这种异常情况的出现:

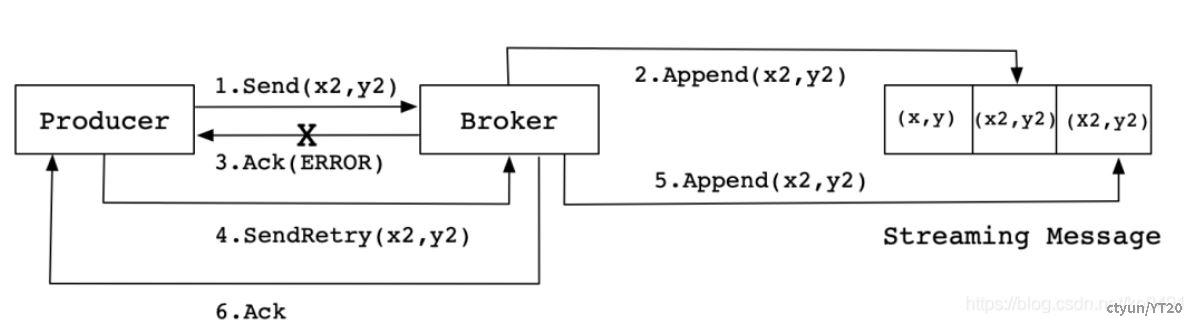
上图这种情况,当Producer第一次发送消息给Broker时,Broker将消息(x2,y2)追加到了消息流中,但是在返回Ack信号给Producer时失败了(比如网络异常) 。此时,Producer端触发重试机制,将消息(x2,y2)重新发送给Broker,Broker接收到消息后,再次将该消息追加到消息流中,然后成功返回Ack信号给Producer。这样下来,消息流中就被重复追加了两条相同的(x2,y2)的消息。
幂等性:
保证在消息重发的时候,消费者不会重复处理。即使在消费者收到重复消息的时候,重复处理,也要保证最终结果的一致性。所谓幂等性是指producer向server发送多条重复数据,server端只会持久化一条数据;数学概念就是: f(f(x)) = f(x) 。f函数表示对消息的处理。比如,银行转账,如果失败,需要重试。不管重试多少次,都要保证最终结果一定是一致的
幂等性的实现机制:
幂等性的实现离不开ack机制,ack=1 只要下端的broker的leader分区写入成功则任务是成功的;ack =0 producer之发送一次,不管对端有没有写入成功,对应语义是at most once;ack = -1 确保所有分区均写入成功,对应语义是at least once;
at least once确保了至少会发送一次,幂等性确保了及时收到重复消息也不会重复处理,因此想要实现 Exactly once ,可以将at least once与幂等性结合,即Exactly once = at least once + 幂等性。当使用幂等性时,此时默认ack=-1。 而幂等性确保了不会发送重复的数据,
为实现幂等性,引入了两个概念:
-
ProducerID:在每个新的Producer初始化时,会被分配一个唯一的ProducerID,这个ProducerID对客户端使用者是不可见的。
-
SequenceNumber:对于每个ProducerID,Producer发送数据的每个Topic和Partition都对应一个从0开始单调递增的SequenceNumber值。
Broker端会将<Pid,Partition,SequenceNumber> 持久化,具有相同主键的消息只会持久化一条。
幂等性解决的问题:
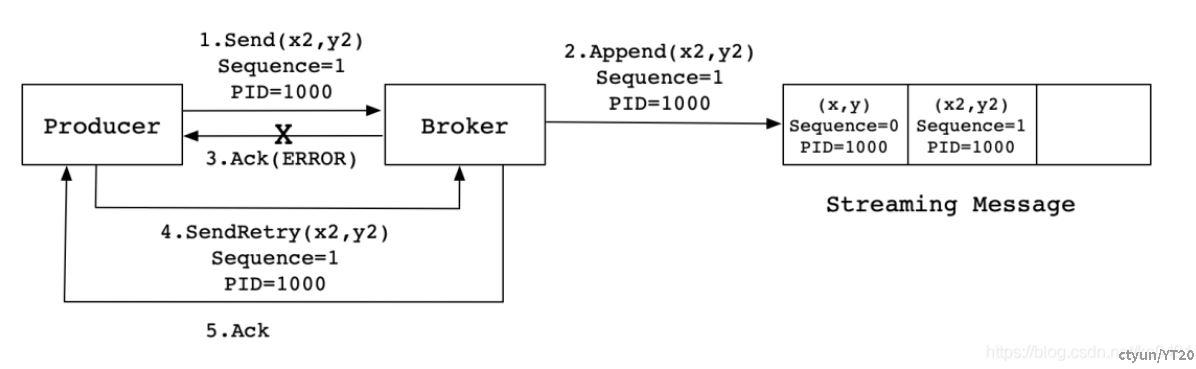
当Producer发送消息(x2,y2)给Broker时,Broker接收到消息并将其追加到消息流中。此时,Broker返回Ack信号给Producer时,发生异常导致Producer接收Ack信号失败。对于Producer来说,会触发重试机制,将消息(x2,y2)再次发送,但是,由于引入了幂等性,在每条消息中附带了PID(ProducerID)和SequenceNumber。相同的PID和SequenceNumber发送给Broker,而之前Broker缓存过之前发送的相同的消息,那么在消息流中的消息就只有一条(x2,y2),不会出现重复发送的情况;
如果消息序号比Broker维护的序号大一以上,说明中间有数据尚未写入,也即乱序,此时Broker拒绝该消息,Producer抛出InvalidSequenceNumber
-
Broker保存消息后,发送ACK前宕机,Producer认为消息未发送成功并重试,造成数据重复。
-
前一条消息发送失败,后一条消息发送成功,前一条消息重试后成功,造成数据乱序(由SequenceNumber)。
局限性:
只能保证 Producer 在单个会话内不丟不重,如果 Producer 出现意外挂掉再重启是无法保证的(幂等性情况下,是无法获取之前的状态信息,因此是无法做到跨会话级别的不丢不重);幂等性不能跨多个 Topic-Partition,只能保证单个 partition 内的幂等性,当涉及多个 Topic-Partition 时,这中间的状态并没有同步。如果需要跨会话、跨多个 topic-partition 的情况,需要使用 Kafka 的事务性来实现。
事务:
事务可以保证读写操作的原子性,要么全部成功,要么全部失败,即使该生产或消费跨多个<Topic, Partition>。尤其对于Kafka Stream应用而言,典型的操作即是从某个Topic消费数据,经过一系列转换后写回另一个Topic,保证从源Topic的读取与向目标Topic的写入的原子性有助于从故障中恢复。
-
Exactly Once即正好一次语义
-
操作的原子性
-
有状态操作的可恢复性
实现机制
为实现这种效果应用程序必须提供一个稳定的(重启后不变)唯一的ID,也即Transaction ID。Transactin ID与PID可能一一对应。区别在于Transaction ID由用户提供,而PID是内部的实现对用户透明。<Pid,Partition,SequenceNumber>+Transaction ID,通过不变的Transactin ID保证了跨会话的精准一次。
另外,为了保证新的Producer启动后,旧的具有相同Transaction ID的Producer即失效,每次Producer通过Transaction ID拿到PID的同时,还会获取一个单调递增的epoch。由于旧的Producer的epoch比新Producer的epoch小,Kafka可以很容易识别出该Producer是老的Producer并拒绝其请求。如果使用同一个TransactionID 开启两个生产者,那么前一个开启的生产者会报错:Producer attempted an operation with an old epoch. Either there is a newer producer with the same transactionalId, or the producer’s transaction has been expired by the broker.
有了Transaction ID后,Kafka可保证:
-
跨Session的数据幂等发送。当具有相同Transaction ID的新的Producer实例被创建且工作时,旧的且拥有相同Transaction ID的Producer将不再工作。
-
跨Session的事务恢复。如果某个应用实例宕机,新的实例可以保证任何未完成的旧的事务要么Commit要么Abort,使得新实例从一个正常状态开始工作。
事务流程图:
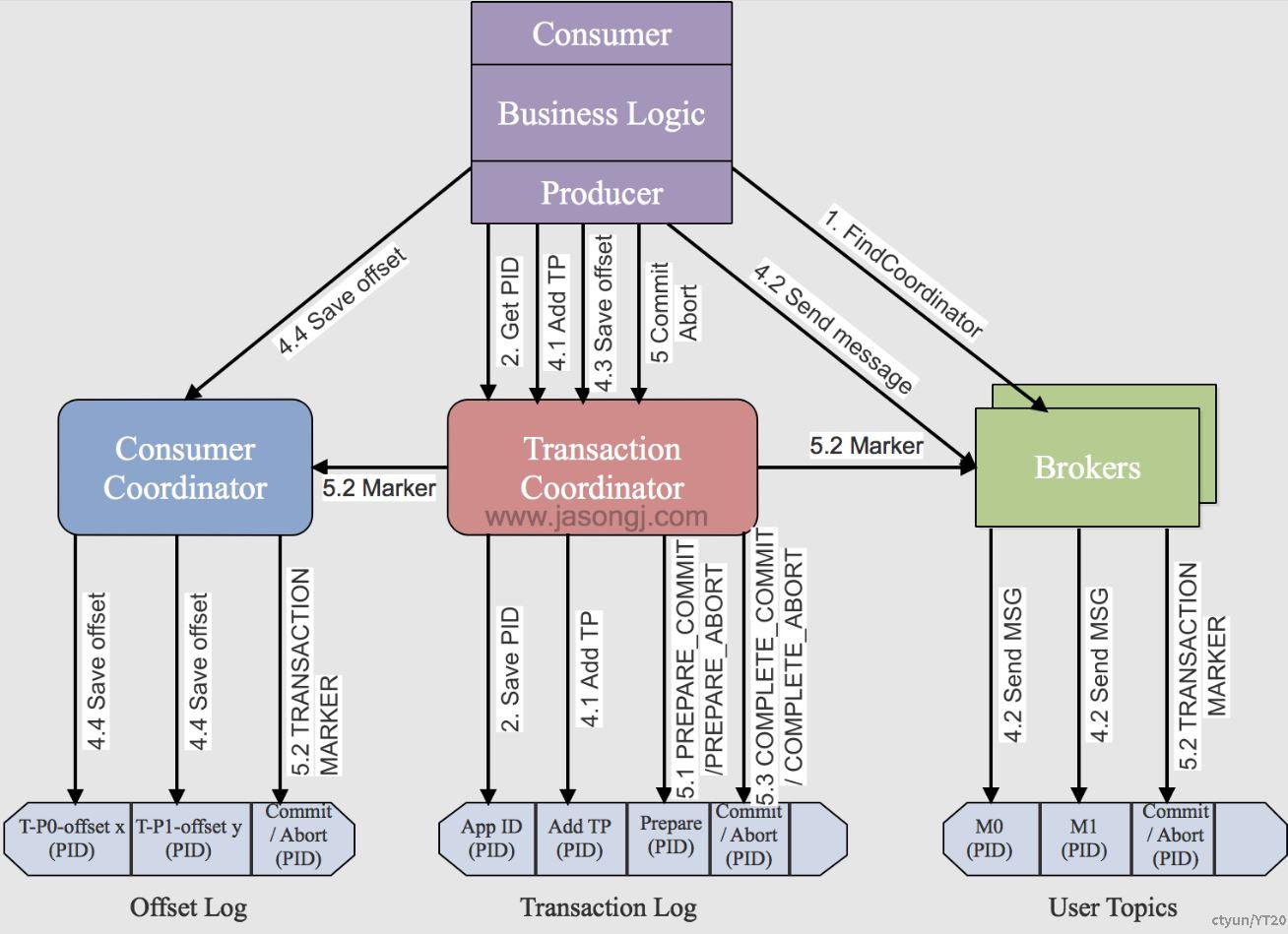
具体的执行步骤:
- 查找Tranaction Corordinator,Producer向任意一个brokers发送 FindCoordinatorRequest请求来获取Transaction Coordinator的地址;根据设置的transactional-id1的哈希值计算对_transaction_state分区数取余运算,找到分区编号,该分区对应的leader副本所对应的broker的即为Tranaction Coordinator所在节点。
- 初始化事务 initTransaction,此步骤为了获得和保存<TransactionId,pid>的映射关系,将<TransactionId,pid>持久化到内部主题中。恢复(Commit或Abort)之前的Producer未完成的事务,对PID对应的epoch进行递增,这样可以保证同一个app的不同实例对应的PID是一样,而epoch是不同的。
- 开始事务beginTransaction,执行Producer的beginTransacion(),它的作用是Producer在本地记录下这个transaction的状态为开始状态。这个操作并没有通知Transaction Coordinator,因为Transaction Coordinator只有在Producer发送第一条消息后才认为事务已经开启。
- read-process-write流程。这一阶段,包含了整个事务的数据处理过程,并且包含了多种请求。包括存储<TransactionId,TopicPartition>关系到_transaction_state,有了这个对应关系就可以后续给每个分区设置COMMIT和ABORT,根据groupId推导出在_consumer_offsets中的分区,并将该分区存储到_transaction_state中,发送请求给GroupCoordinator,从而将本次事务消费的offsets存储至_consumer_offsets.
- 事务提交或终结 commitTransaction/abortTransaction。第一阶段,将Transaction Log内的该事务状态设置为PREPARE_COMMIT或PREPARE_ABORT,第二阶段,将Transaction Marker写入该事务涉及到的所有消息(即将消息标记为committed或aborted)。这一步骤Transaction Coordinator会发送给当前事务涉及到的每个<Topic, Partition>的Leader,Broker收到该请求后,会将对应的Transaction Marker控制信息写入日志。一旦Transaction Marker写入完成,Transaction Coordinator会将最终的COMPLETE_COMMIT或COMPLETE_ABORT状态写入Transaction Log中以标明该事务结束。
事务使用的场景:
- 只有Producer生产消息,这种场景需要事务的介入;
- 消费消息和生产消息并存,比如Consumer&Producer模式,这种场景是一般Kafka项目中比较常见的模式,需要事务介入;
- 只有Consumer消费消息,这种操作在实际项目中意义不大,和手动Commit Offsets的结果一样,而且这种场景不是事务的引入目的。
