


引言
时序相关的流式处理过程是有状态流式处理过程的一个扩展。其中,时间扮演了其计算过程的重要角色。此外,其案例包括:时序分析,在特定时间周期内聚合(窗口)计算,或事件发生时间十分重要的事件处理过程。
在以下章节中,我们将重点介绍在使用时间相关的Flink应用时应该考虑的一些主题。
概念: 事件时间和处理时间
当提及流处理程序的时间时,比如窗口,我们会引用到不同的时间概念:
- 处理时间,即执行相应操作的那台机器的系统时间。
当流处理程序按处理时间来运行,那么所有基于时间的操作(比如时间窗口)都将使用运行相关算子的那台机器的系统时间。一个以每小时为处理周期的时间窗口,将包含了所有在系统时钟指示整点时间之间到达特定算子的记录。例如,如果应用程序在上午 9:15 开始运行,则第一个处理时间窗口将包括在上午 9:15 和上午 10:00 之间处理的事件,下一个窗口将包括在上午 10:00 和上午 11:00 之间处理的事件,以此类推。
处理时间是最简单的时间概念,不需要在流和机器之间进行协调。它提供了最佳性能和最低延迟。然而,在分布式和异步环境中,处理时间无法提供确定性。因为它容易受到数据到达系统(例如从消息队列)的速度,数据在系统内各算子间流动的速度,以及中断(计划或其他类型)的影响。
- 事件时间,即每个独立事件在其生产设备上发生的时间。
这个时间通常在数据进入 Flink 之前内嵌在数据中,而且该事件时间戳可从每条数据中提取。在事件时间中,时间的推进取决于数据,而不是任何时钟。事件时间程序必须指定如何生成事件时间水位线,即在事件时间中信号推进的机制。这种水位线机制将在后文中描述。
在一个完美的世界中,事件时间处理将产生完全一致和确定的结果,无论事件何时到达或它们的顺序如何。但除非已知事件按时间戳顺序到达,否则事件时间处理在等待无序事件时会产生一些延迟。由于只能等待一段有限的时间,这限制了事件时间应用程序的确定性。
假设所有数据都已到达,事件时间操作将按预期运行,并产生正确且一致的结果,即使在处理无序或延迟事件时,或者在重新处理历史数据时也是如此。例如,一个以每小时为处理周期的事件时间窗口,将包含所有带有属于该小时的事件时间戳的记录,无论它们到达的顺序或处理时间是多少。 (有关更多信息,请参阅有关迟到事件的部分)
注:有时当事件时间程序处理实时数据时,它们会使用一些处理时间操作以确保它们及时进行。
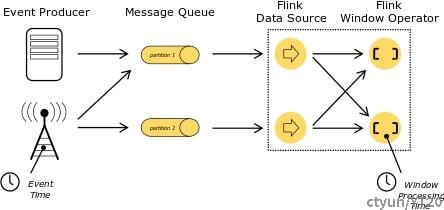
事件时间和水位线
支持事件时间的流处理器需要一种测量事件时间推进过程的方法。例如,一个以每小时为周期的窗口算子需要在事件时间超过一小时结束时得到通知,以便算子可以关闭窗口。
事件时间可以独立于处理时间(由时钟测量)推进。例如,在一个程序中,算子的当前事件时间可能稍微落后于处理时间(考虑到接收事件的延迟),而两者以相同的速度推进。另一方面,另一个流程序通过快速转发已经在 Kafka 主题(或另一个消息队列)中缓存的一些历史数据,即可花几秒钟的处理时间处理完在事件时间维度流过几个星期的数据。
Flink 中衡量事件时间进度的机制是水位线(watermarks)。水位线作为数据流的一部分进行流动,并带有时间戳 t。 Watermark(t) 声明了事件时间在该流中已达到时间 t,这意味着流中不应再有时间戳 t’ <= t 的元素(即时间戳早于或等于水位线的事件)。
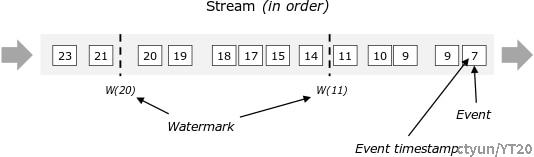
下图显示了带有(逻辑)时间戳的事件流,以及同时流动于其中的水位线。在此示例中,事件相对于它们的时间戳是有序的,这意味着水位线只是流中的周期性标记。
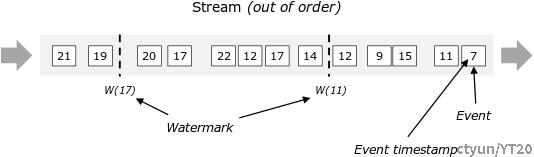
如下图所示,水位线对于其中事件不按时间戳排序的乱序流来说至关重要。 一般,水位线是一个声明,即到流中的那个点,直到某个时间戳的所有事件都应该已经到达。 一旦水位线到达一个算子,那这个算子可以将其内部事件时钟前置到水位线的值。
注:事件时间由新创建的流元素(或多个元素)从生成它们的事件或触发创建这些元素的水位线继承。
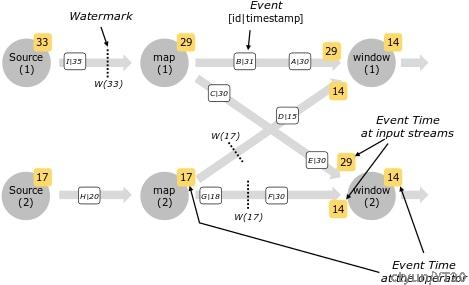
并行数据流中的水位线
水位线在源函数处或紧跟其后生成。源函数的每个并行子任务通常会独立生成其水位线。这些水位线定义了特定并行源的事件时间。
当水位线流经流程序时,它们会在到达的算子处前置事件时间。 每当算子前置其事件时间时,它就会为其后续算子在下游生成一个新的水位线。
一些算子消费多个输入流, 如:union,或 紧跟keyBy(…) 或 partition(…) 函数后面的算子。 这样一个算子的当前事件时间是其输入流事件时间的最小值。 当输入流更新它们的事件时间时,算子也做了相同操作。
下图显示了流经并行流的事件和水位线示例,以及跟踪事件时间的算子。
延迟
某些元素可能会违反水位线条件,这意味着即使在 Watermark(t) 发生之后,还会出现更多时间戳 t’ <= t 的元素。事实上,在许多现实世界的配置中,某些元素可以任意延迟,因此无法指定某个事件时间戳的所有元素将在何时发生。 此外,即使延迟可以有界,过多地延迟水位线通常也是不可取的,因为它会导致对事件时间窗口的评估延迟过多。
出于这个原因,流程序可能会明确地预期一些延迟元素。 延迟元素是在系统的事件时钟(由水位线发出信号)已经超过延迟元素的时间戳之后到达的元素。
窗口
聚合事件(如:计数counts、求和sums等)在流上的工作方式与批处理不同。例如,我们无法计算流中的所有元素,因为流通常是无限的(或无界的)。相反,在流上的聚合(计数、求和等)由窗口限定,例如“过去 5 分钟的计数”或“最后 100 个元素的总和”。
窗口可以是时间驱动的(例如:每 30 秒)或数据驱动的(例如:每 100 个元素)。人们通常区分不同类型的窗口,例如滚动窗口(无重叠)、滑动窗口(有重叠)和会话窗口(由非活跃间隙分隔)。

