


大模型Agent介绍
1. 介绍
假设读者已经具备基础的强化学习知识。
本文大概分为如下几个章节:
● 大模型Agent介绍
● 大模型Agent和RLAgent的关系
● 大模型Agent的适用场景
● 典型Agent介绍
● 大模型Agent的关键技术
● 总结
2. 大模型Agent介绍
LLM-Based Agent最开始的定义来自于这个图
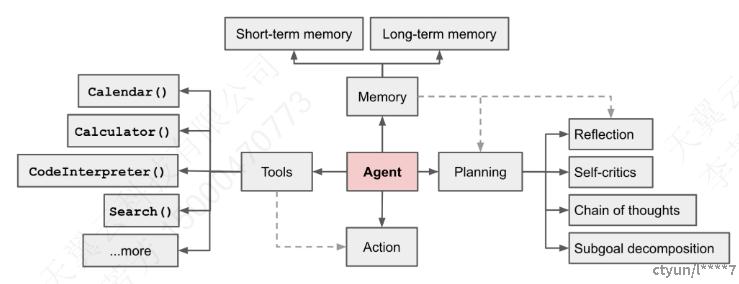
图表 1:大模型Agent
这个图虽然把LLM-Based Agent的关键要素Memory、Tools、Planning、Action都画出来了,但是各个模块的功能没有定义,感觉并不是很好。
这里以其他论文中的1个图来说明:
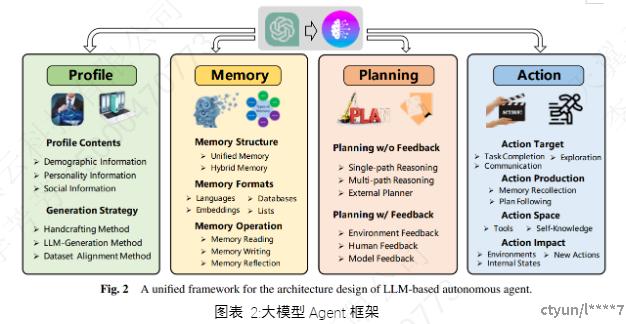
图表 2:大模型Agent框架
Profile模块:
定义和管理Agent角色的特性和行为。以强化学习里面的AC算法为例,Actor和Critic就是不同的Agent。
它包含一系列参数和规则,描述了Agent的各种属性,如角色、目标、能力、知识和行为方式等。这些属性决定了Agent如何与环境交互,如何理解和响应任务,以及如何进行决策和规划。
Agent角色生成有3种常用的方式,包括手工生成、LLM生成方法、数据集对齐方法。
1. 手工生成方法:手动指定Agent配置文件,利用大语言模型+Prompt设置Agent。例如,如果一个人想设计具有不同个性的Agent,他可以使用“你是一个外向的人”或“你是一个内向的人”来描述Agent。这种场景如果需要生成很多Agent,效率比较低下。
2. LLM生成方法:首先设定Agent的组成规则,明确目标Agent应具备的属性;然后指定几个手工创建的种子配置文件作为示例;最后利用语言模型的Self-Instruct能力生成大量Agent配置文件。
3. 数据集对齐方法:是从真实世界的人口数据集中获取Agent的配置文件信息,比如通过抽取人口调查数据组织成自然语言描述。这样可以使Agent行为更真实可信,准确反映真实人口的属性分布。
Memory模块:
存储和组织从环境中获取的信息,以指导未来行动。和强化学习DQN里面的经验池功能类似。
内存模块通常包含短期记忆和长期记忆两个部分。短期记忆暂存最近的感知,长期记忆存储重要信息供随时检索。
格式上,内存信息可以用自然语言表达,也可以编码为向量嵌入提高检索效率。还可以利用数据库存储,或组织为结构化列表表示内存语义。
操作上,主要通过记忆读取、写入和反射三种机制与环境交互。读取提取相关信息指导行动,写入存储重要信息,反射总结见解提升抽象水平。反射这个操作有点类似于强化学习里面的优先级经验采样,只不过优先级经验采样是从经验池中挑选数据,反射是对所有的记忆进行抽象。
Planning模块:
帮助Agent将复杂的任务分解为更易处理的子任务,并制定出有效的策略。
它大致分为两种类型,一种是不依赖反馈的计划,另一种则是基于反馈的计划。反馈类似于强化学习里面的Reward
a) 不依赖反馈的计划在制定过程中并不参考任务执行后的反馈,它有几种常用的策略。比如单路径推理,它按照级联的方式,一步一步地生成计划。另外,还有多路径推理,它会生成多个备选的计划路径,形成树状或图状的结构。当然,我们也可以利用外部的规划器进行快速搜索,以找出最优的计划。
b) 基于反馈的计划,它会根据任务执行后的反馈来调整计划,这种方式更适合需要进行长期规划的情况。反馈的来源可能来自任务执行结果的客观反馈,也可能是根据人的主观判断给出的反馈,也可能是根据其他Agent给出的反馈,甚至还可以是由辅助模型提供的反馈。由辅助模型提供的反馈类似于强化学习里面的Reward Modeling。
Action模块:
将抽象的决策转化为具体的行动。这个就和强化学习的Action是类似的。
在执行任务时,需要考虑行动的目标、生成方式、应用范围以及可能产生的影响。
理想的行动应当是有目的的,例如完成特定任务、与其他代理进行交流或者探索环境。行动的产生可以依赖于查询过去的记忆经验,或者遵循预设的计划。而行动的范围,不仅可以通过利用如API和知识库等外部工具来扩展,还需要发挥大型语言模型(LLM)的内在能力,例如规划、对话及理解常识等。
3. 大模型Agent和RLAgent的关系
从前文来看,大模型Agent和RLAgent是非常类似的,这里我们分析一下他们两者的异同点。

图表 3:RLAgent关键要素
智能体:
强化学习里面的智能体通常需要手工指定,而且智能体数量不会很多,例如在游戏指定场景中敌人和队友,在AC算法中指定Actor和Critic。每个Agent的输入输出维度是固定的。
而大模型Agent可以有多种生成方式,由(大模型+Prompt)的方式定义Agent。每个Agent的输入输出问题也不是固定的,可以接受自然语言的输入输出。
状态:
强化学习里面的State维度是需要人工定义的,维度是固定的。而且NextState是从环境反馈中得到的。
大模型Agent中的NextState可以由环境反馈,也可以由人类交互反馈,也可以是大模型Agent主动从环境中思考总结。
动作:
强化学习里面的Action是需要人工定义的,维度是固定的,通常是离散的行为(例如下棋)或者连续向量(例如自动驾驶,方向盘向左偏移75度)。
大模型Agent中的Action可以更加丰富多样,例如Action可以是外部API,也可以是大模型的内在能力(规划、对话及理解常识等)
奖励
强化学习里面的Reward是需要人工定义的,如果设计的不好,会出现RewardShaping的问题。
大模型Agent的Reward可以从环境反馈中Agent自我思考得到,也可以由人类交互反馈。
环境
强化学习的1个要求就是训练环境和测试环境是完全一样的。例如AlphaGo训练环境是按照围棋规则训练的,如果在测试环境中增加1条规则(例如规定棋盘的角落不能落子),那么AlphaGo大概率是会挂掉的。
大模型Agent对环境的适应能力没有强化学习要求这么高,可以适应一定的环境变化。
4. 大模型Agent的适用场景
我们先来分析下强化学习的适用场景,再来讨论大模型Agent的适用场景。
4.1 强化学习的适用场景
强化学习需要满足如下几个要求:环境固定、目标明确、数据廉价、过程复杂、自由度高。
环境固定
训练环境尽可能做到与测试环境相同。
举个例子:agent在环境中遇到一条峡谷,跳过去的过程中有30%的概率被落石击中,这里的30%就属于这类因素,训练和测试环境要保持一致。30%这个数字在RL叫状态转移概率。RL的理论基础即建立在马尔可夫决策过程之上,Value函数和policy就是通过隐式(model-free)或显式(model-based)地对环境model建模得到的。model变了,policy就废了。
目标明确
目标明确很好理解,任务要达到何种效果清晰具体,最好可以量化。工业界的需求一般都是优化某个指标(效率、能耗、胜算等),基本满足这个条件。目标越明确,设计优质的reward函数就越容易,从而训练得到更接近预期的policy
数据廉价
数据廉价对RL至关重要,毕竟挥霍数据是RL与生俱来的属性,这里就涉及1个关键技术高仿真模拟器。模拟器和真实世界有一个reality gap的问题,如果gap太大则训练出的policy无法直接应用。对模拟器精度的要求和上文的“环境固定”要求是类似的。
除此之外,数据廉价还包含了另一层意思——采样速率。AlphaGo在宣传的时候动不动就说他们的agent学习了相当于人类XX万年的经验,显然没有高速模拟器是不可能做到的
过程复杂
前三个特征决定了“能不能”,那么接下来两个特征决定了“值不值”。
如果任务太简单,依靠规则和启发式就能解决问题了,相当于拿到了“解析解”,哪里还需要神经网络?
自由度高
自由度高指的是选择空间大、限制少。
自由度越高,DRL优势越明显,自由度越低,越有利于规则。因此在决定用DRL之前,一定要认真评估任务场景是否有足够的优化空间,千万不要拎着锤子找钉子,否则即使训出了模型,性能也不如传统算法,白忙活一场
4.2大模型Agent的适用场景
大模型Agent由于大模型自身具备强大的迁移和泛化能力,适用场景也不像强化学习有这么多约束。但是另外一方面,大模型运行推理成本较高,openai经常说他们亏损了几十亿美元,更别说其他大模型公司了。此时,大模型Agent值不值显得尤为重要。
环境:
LLMs 具备强大的迁移与泛化能力,一个大模型Agent可以具备对未知任务的泛化能力、从上下文情境学习的能力。
但是大模型Agent并不是万能的,在Profile模块已经定义了Agent的特性和行为,在特定领域定义的Agent,迁移到其他环境,需要通过微调LLM来提高性能。看过美剧《西部世界》的同学应该知道,1个甜水镇的妓女可以应对各种各样的客人(Agent的泛化性);但是甜水镇的妓女到了日本幕府乐园中,此时Agent需要重新学习日本幕府乐园的生存规则才能够生存(微调LLM)。
目标:
目标也是越明确越好。但是在多大模型Agent的场景下,可能很难对每个Agent定义1个具体的指标,此时可以定义1个全局目标,每个Agent的子目标由Agent自行协商。全局目标也是越明确越好。
数据:
和RL一样,数据也是越廉价越好。毕竟大模型Agent和RL一样,需要从数据中学习经验。
过程:
和RL一样,如果任务很简单,通过1个工具很容易完成,就没有必要使用大模型Agent。毕竟,吴恩达爆火的ChatGPT课一开始就只出了“ChatGPT放弃了倒写单词,但理解了整个世界”。只有遇到很复杂的任务,充分使用大模型Agen调用各种外部工具的能力,此时才值得使用大模型Agent。
自由度:
和RL一样,选择空间大,限制小的场景才需要使用大模型Agent。
“选择空间大”这一点很容易理解,如果选择空间小,用if-else代码就可以完成的,为啥要用大模型Agent呢?
“限制小”这一点体现在大模型Agent,如果完成一个任务有很多约束,约束信息大概率是通过Prompt完成,约束很多,Prompt就会很长,大模型推理成本就会变高。
5. 典型Agent介绍
大模型Agent的能力这么强化,那么怎么才能生产出1个可用的Agent呢?下面我们分别介绍1个学术界的大模型Agent和1个工业界的大模型Agent,来看看完成1个Agent需要哪些工作。
5.1 OpenBMB-XAgent
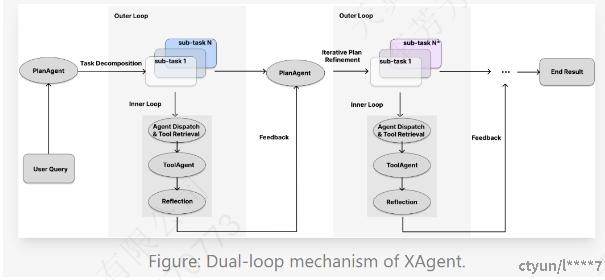
图表 4:XAgent总体流程
XAgent是1个可以调用rapid api的各种工具,完成用户请求的1个系统。
Profile模块:
定义了5个Agent,DispatcherAgent,PlanGenerateAgent,PlanRefineAgent,ToolAgent和ReflectAgent。
1. DispatcherAgent:初始Agent,使用前文提到的“LLM生成方法”生成其他Agent,用户提供任务(例如需要1个任务分解Agent和1个工具执行Agent),DispatcherAgent负责生成其他Agent的Prompt。
2. PlanGenerateAgent:初始Plan生成。接收到用户请求后,将初始用户请求分解为多个subTask
3. PlanRefineAgent:迭代Plan重新生成,如果ToolAgent未完成任务,PlanAgent从Memory中反思改进,生成下一轮的多个subTask。
4. ToolAgent:使用大模型自身能力(例如文本理解、文本分析)或者从rapid api找到可用外部工具(例如播放音乐)
5. ReflectAgent:从Memory中反思改进的Agent。职责包含总结现有流程的工具调用和想法、SubTask的反思(例如xxx Task找不到合适的工具)、工具调用的反思(例如“工具 xxx 现在不可用”,或“我需要在工具 aaa 中提供字段 yyy”)
Memory模块:
Memory包含如下内容:PlanAgent历史的Plan生成过程,ToolAgent检索工具的工程,工具完成Action的过程。此处没有区分长期记忆和短期记忆。
Planning模块:
PlanGenerateAgent和PlanRefineAgent都使用了Planning能力
Action模块:
Action有2种,大模型自身完成和rapid api完成。rapid api已经提供了各种工具的标准RestAPI接口。例如获取足球信息的api。
图表 5:rapidapi示例
5.2 快手- Kwai Agents

图表 6:KwaiAgents架构
Profile模块:
设计 Meta-Agent,对特定问题集合,生成实例化的 Agent Prompt 模板。其他Agent包含PlanAgent和ConclusionAgent。
1. PlanAgent:根据任务目标和已有Task,规划一个新Task
2. ConclusionAgent:总结Agent,整理Memory中的历史信息给出最终的结论。
Memory模块:
包含知识库、对话、任务历史三类记忆,依托于混合向量检索、关键词检索等技术的检索框架,在每一次规划路径中检索所需的信息
Planning模块:
PlanAgent使用了Plan能力。
Action模块:
包含浏览器网页搜索、日历、农历节气、时间差、天气工具集,这些工具有些需要调用RestAPI完成,有些需要直接调用函数完成。
总体来说KwaiAgent工具集数量和XAgent相比少了很多,完成的任务也很有限。
6. 大模型Agent的关键技术
强化学习的关键技术包含:算法选择、动作空间设计、状态设计、Reward设计。这里我们总结一下完成1个大模型Agent需要哪些关键技术。
6.1 强大的基座模型
这个很容易理解,毕竟大模型Agent的基础就是“大模型”。如果基座大模型不够强大,大模型Agent就无法顺利运行。
6.1 Agent定义
在前面的XAgent和KwaiAgent都使用了1个MetaAgent来生成其他Agent的模板,但是对于一些专业角色(如程序员、研究员等),LLM现在还很难精确扮演。针对这些专业角色,如何找到最佳提示并不容易。一个可行的方法是“LLM生成+数据集对齐”的方法,可以首先收集不常见角色或心理特征的真实人类数据,然后利用这些数据来微调LLM。
尤其是在多Agent场景下,设计几个Agent?多个Agent如何交互?都需要精心的设计。
6.3 Memory存储、搜索和反思
RL是从海量经验中学习,大模型Agent也是类似的,需要从Memory中反思改进。Memory的存储需要关注哪些信息需要存储?多Agent场景下是否需要使用共享存储。Memory的搜索如何实现高效搜索?如何保证搜索结果的有效性?特别关注的是“反思”能力, “反思”能力一般是使用(大模型+prompt)从Memory中反思总结,反思不仅包含从自己的Memory中反思,还包含从他人的Memory中反思。
6.4 Tools标准化
前面的Plan、Memory等都是为了生成执行计划,而任务执行是依赖外部Tools的。显而易见,如果所有的外部Tool都提供了Rest访问方式,Agent只需要调用RestAPI,则可以执行执行更多的任务;另外1种场景,有个外部Tool是RestAPI,有的外部Tools是RPC接口,那么Agent就需要理解不同Tool的调用方式,出错概率越大。总而言之,工具数量的多少和标准化程度直接决定Agent执行多少任务。
7. 总结
大模型Agent发展非常迅速,几乎每过几天都会有爆款的Agent问世,从HuggingGPT、AutoGPT,斯坦福小镇的Generative Agents、清华的Ghost in the Minecraft (GITM)。大模型Agent作为一种新型的智能体,具有强大的迁移和泛化能力,适用于多种复杂的场景。它们通过结合大型语言模型的内在能力和外部工具,能够执行多样化的任务。然而,大模型Agent的有效运行需要考虑Agent定义、Memory管理和工具标准化等关键技术,当前还是在学术界流行,工业界虽然有微软的Copilot Studio、 Copilot Team,但是还没有成为爆款应用。相信随着技术的发展,大模型Agent有望在更多领域发挥重要作用。
