


我们知道LLM推理主要有两个阶段:prefill和decode。前者瓶颈在于计算,而后者在于带宽。在prefill中已经有将sequence length拆开计算再汇总的做法,上下文并行则是将这个过程并行完成,以减少对显存大小的需求。
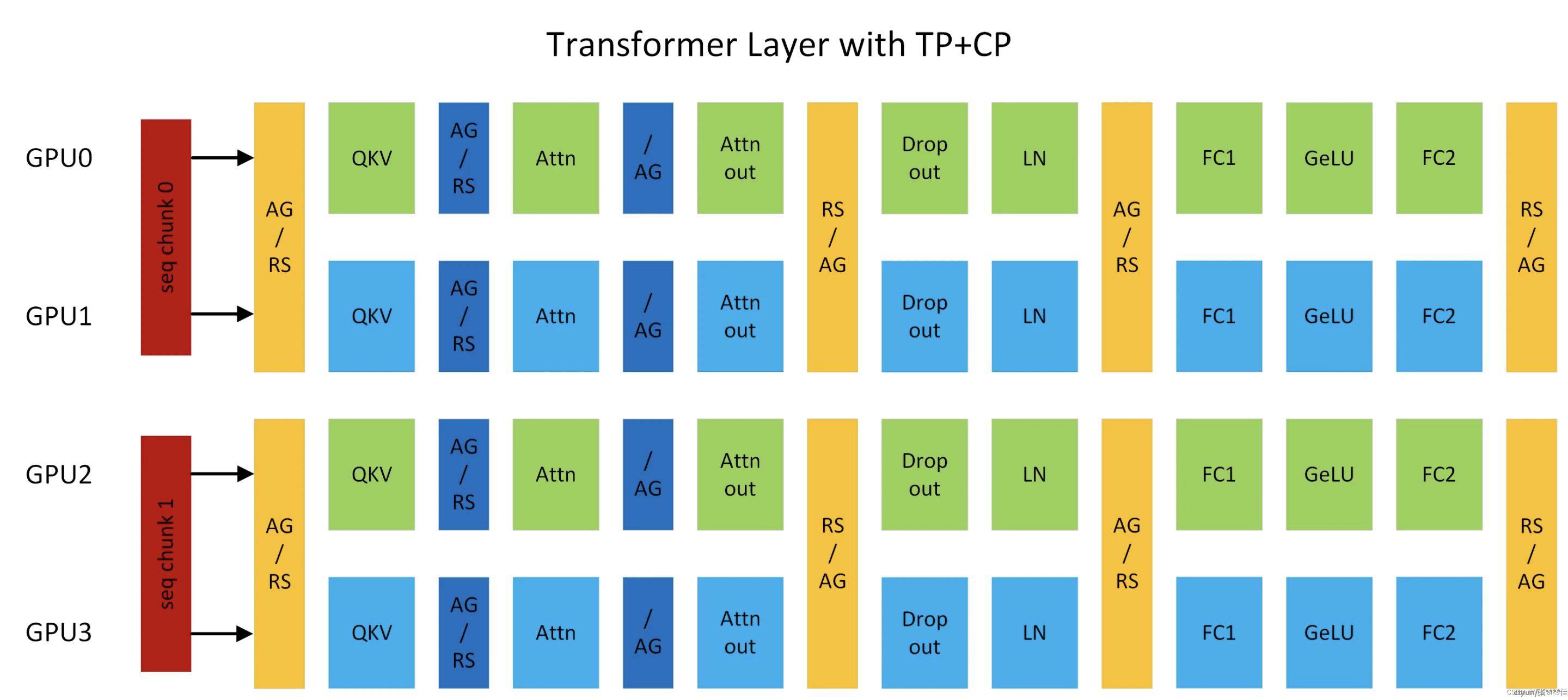
上下文并行最近出现在NVIDIA Megatron-Core中,被应用在GPT类型的模型中,其主要是针对self-attention(Linear,LayerNorm)进行优化,它将原本的输入按照sequence length维度拆开,分到不同的device上,分别计算QKV,然后通信整合其他device上算出的KV(all-gather和reduce-scatter)。下面一张图可以概括这个过程,其中同时加入了TP,互不影响。
这个并行机制主要的目的还是为了解决文本过长导致的OOM问题。
关于all-gather
在 all-gather 操作中,每个进程都拥有一部分数据,并希望从其他所有进程收集类似的数据片段。完成 all-gather 操作后,每个进程都将拥有所有进程中的数据的完整集合。
这种操作在多个进程需要交换信息以便进行下一步计算时非常有用。例如,在并行模拟、机器学习和深度学习中,多个工作节点可能需要同步它们的模型参数或中间计算结果。
All-gather 操作的步骤通常包括:
数据分发:每个进程拥有一部分数据,并将其发送给其他所有进程。
数据收集:每个进程接收来自其他所有进程的数据片段。
数据重组:每个进程将收到的数据片段整合到本地数据结构中,以便重建完整的数据集。
关于reduce-scatter
在 reduce-scatter 操作中,每个进程都有一个数据输入,它们首先在本地执行约简操作,然后将结果发送到所有其他进程。不同于简单的广播(broadcast)或归约(reduce)操作,reduce-scatter 确保每个进程都接收到所有其他进程的约简结果,而不仅仅是发送给一个特定的进程。
Reduce-scatter 操作的步骤通常包括:
本地约简:每个进程对其拥有的数据执行约简操作(例如,求和)。
发送数据:每个进程将其约简结果发送到所有其他进程。
接收数据:每个进程接收来自所有其他进程的约简结果。
数据分发:每个进程将接收到的数据分发给其本地的相应部分,以便在后续计算中使用。
Pytorch实现CP
import torch
def gen_causal_mask(seq_q_len, seq_kv_len):
row_idx = torch.arange(seq_q_len).unsqueeze(-1)
col_idx = torch.arange(seq_kv_len)
r = row_idx + seq_kv_len - seq_q_len + 1 <= col_idx
return r
def attention(q, k, v):
# q, k, v: (batch_size, n_heads, seq_len, hidden_dim)
seq_q_len, seq_kv_len, hidden_dim = q.shape[2], k.shape[2], k.shape[-1]
attn = torch.matmul(q, k.permute(0,1,3,2)) / hidden_dim**0.5
mask = gen_causal_mask(seq_q_len, seq_kv_len)
attn = attn.masked_fill(mask, float('-inf'))
attn = torch.softmax(attn, dim=-1)
out = torch.matmul(attn, v)
return out
if __name__ == "__main__":
batch_size, n_heads, seq_len, hidden_dim = 4, 8, 1024, 128
cp = 2
q = torch.randn(batch_size, n_heads, seq_len, hidden_dim)
k = torch.randn(batch_size, n_heads, seq_len, hidden_dim)
v = torch.randn(batch_size, n_heads, seq_len, hidden_dim)
original_output = attention(q, k, v)
# prefilling
new_output = []
for st in range(0, seq_len, seq_len//cp):
ed = st + seq_len // cp
seq_q = q[:, :, st:ed, :]
seq_k = k[:, :, :ed, :]
seq_v = v[:, :, :ed, :]
out = attention(seq_q, seq_k, seq_v)
new_output.append(out)
new_output = torch.cat(new_output, dim=2)
print(torch.allclose(original_output, new_output, atol=1e-6))
