


1. 基于检索的生成(RAG)
1.1 为什么需要RAG
随着人工智能技术的发展,基础模型在许多领域得到了广泛应用。然而,通用的基础模型并不能完全满足特定行业和任务的需求,因此,我们需要对基础模型进行调整,以更好地服务于实际工作。
不同的公司和行业有着各自的专业术语和表达方式,通用大模型往往无法很好地适应这些行业的特殊需求。此外,各公司有着不同的任务需求,通用大模型在特定任务上的表现未必出色。再者,通用大模型的时效性问题也不容忽视,它们通常使用一两年前的数据进行训练,无法结合公司的特有背景知识,来提高对客户咨询和投诉的处理能力,从而提升客户满意度。
RAG(Retrieval-Augmented Generation)就是一种可以调整大模型,解决上述问题的方法。
1.2 什么是RAG
RAG的工作原理可以分为三个主要步骤:检索、增强和生成。
1. 检索(Retrieval):从外部知识库或数据源中检索原始信息。基于用户的查询,模型会获取相关内容。这一步骤的目的是找到最相关的信息,以便后续使用。
2. 增强(Augmented):将检索到的相关上下文添加到用户提示中,作为输入传递给基础模型。这一步骤确保模型在生成回答时,能够利用最相关的信息背景,从而提高回答的准确性。
3. 生成(Generation):基础模型基于增强后的提示生成准确的回答。这个过程使得模型的回答不仅基于预训练的知识,还结合了最新的、相关的外部数据。
1.3 RAG的作用
RAG可以在以下几个方面发挥作用:
1. 改进内容质量:通过减少模型的幻觉(即生成不准确或虚假的信息),RAG可以提高内容的质量。预训练模型基于大量数据进行训练,但这些数据可能并不是最新的。通过连接企业的最新知识,RAG 可以提供更准确的回答。
2. 上下文聊天机器人和问答系统:RAG可以将模型聚焦于特定数据,增强聊天机器人的能力,通过与实时数据集成,提高其响应能力。
3. 个性化搜索:基于用户的历史搜索记录和个性进行搜索,提高搜索结果的相关性和个性化。
4. 实时数据摘要:从数据库或API调用中检索和总结事务数据,提供及时和准确的信息。
2. 检索
大模型的基础框架的第一步就是检索。通常,大模型的检索分为三种类型:
1. 规则基础检索:从文档或关键词中获取非结构化数据。这种方式适用于简单的关键词匹配和规则查询。
2. 结构化数据检索:从数据库或API中进行事务性检索,例如从订单数据库中选择特定客户。这种方式适用于处理结构化数据和特定查询需求。
3. 语义搜索:基于文本嵌入获取相关文档,例如从“纽约”联想到“地铁”、“自由女神像”和“高楼”。这种方式可以理解和处理更复杂的自然语言查询。
RAG主要需要使用的检索方式是语义搜索,而实现语义搜索的方法是向量搜索。
2.1 向量搜索与RAG
向量搜索是一种将文本转换为数值表示(向量)的方法,这种表示捕捉了词语之间的语义和关系。接下来,我们详细说明向量搜索的原理、其重要性以及其在RAG模型中的应用。
2.2 向量搜索的原理
1. 文本转换为数值表示(向量):向量搜索首先将文本转换为数值表示,称为向量。这个向量能够捕捉文本中词语的语义和相互关系。
2. 嵌入(Embedding)模型捕捉文本特征和细微差别:嵌入模型能够捕捉文本的特征和细微差别,使得向量能够准确地反映文本的语义内容。
3. 使用丰富的嵌入进行文本相似性比较:通过使用丰富的嵌入,向量搜索能够比较文本之间的相似性。这在文本检索和信息匹配中尤为重要。
4. 多语言文本嵌入:多语言文本嵌入能够识别不同语言中的含义,使得向量搜索在多语言环境中也能发挥作用。
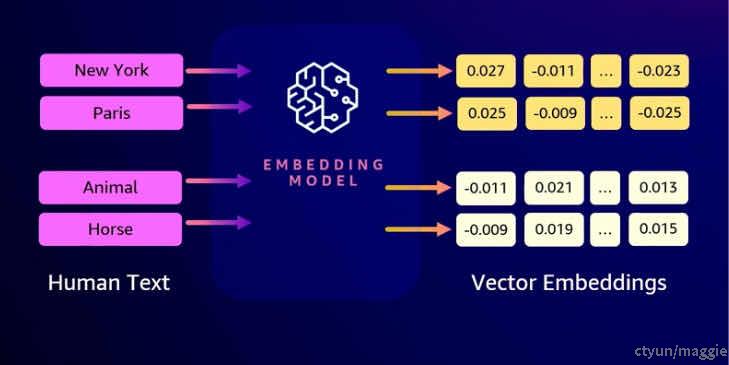
语义上相似的词语如纽约和巴黎、动物和马在向量嵌入上数值也很接近。
2.2 向量搜索对RAG的重要性
1. 基于语义意义进行文本检索:向量搜索能够基于文本的语义意义进行检索,而不仅仅是关键词匹配。这使得检索结果更加准确和相关。
2. 用于增强RAG提示的准确上下文:向量搜索能够从向量存储中检索到与用户查询最相关的上下文,并将其用于增强RAG提示。这提高了模型的回答质量。
3. 高精度嵌入提升上下文和回答质量:使用高精度的嵌入模型可以显著提升上下文的准确性和高质量的大模型生成的回答。这对于提供准确和有用的用户响应至关重要。
2.3 向量相似性度量
在向量搜索中,有几种常见的相似性度量方法:
1. 余弦相似性:通过计算两个向量之间的余弦值来衡量相似性,值越接近1,表示两个向量越相似。
2. 欧几里得距离:通过计算两个向量之间的欧几里得距离来衡量相似性,距离越小,表示两个向量越相似。
3. RAG 的具体工作原理
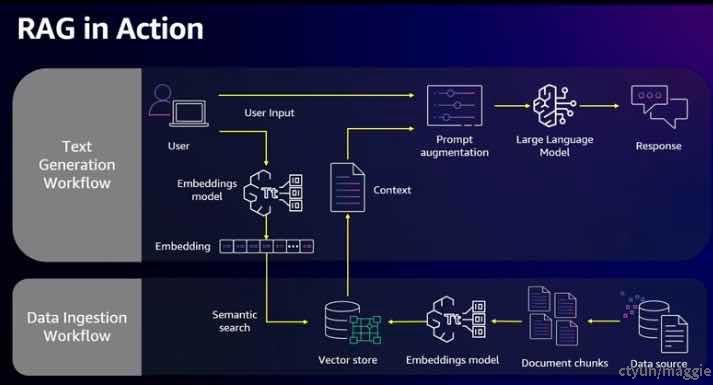
RAG 模型通过结合外部数据源和强大的向量搜索,显著提升了文本生成的质量和准确性。我们将从数据注入工作流和文本生成工作流两个方面来详细解释 RAG 的操作原理。
3.1 数据注入工作流
RAG 的数据注入工作流包括以下几个步骤:
1. 数据源:首先,RAG 需要从外部数据源获取相关信息。这些数据源可以是企业内部的知识库、文档或其他数据文件。
2. 文档分块:将获取到的文档进行分块处理,将长文档分成更小的段落或片段,这样有助于提高检索效率和准确性。
3. 嵌入模型:将文档块输入到嵌入模型中,将文本转换为数值表示(向量)。这些向量能够捕捉文本的语义和关系。
4. 向量存储:将生成的向量存储在一个优化的向量存储库中。这个存储库经过优化,可以高效地进行向量检索,并保持词语的语义关系。

3.2 文本生成工作流
当用户提出问题时,RAG 模型通过以下步骤生成最终的响应:
1. 用户提问:用户向系统提出一个问题。
2. 嵌入模型生成向量:系统将用户的问题输入嵌入模型,生成对应的向量表示。
3. 向量相似性搜索:通过向量存储库进行向量相似性搜索,找到与用户问题最相关的文档片段。这一步骤利用了向量存储库中的语义信息,确保检索到的内容与用户问题高度相关。
4. 增强提示:将检索到的相关上下文信息添加到用户的问题提示中,形成增强提示。这一步骤是为了提供更丰富的背景信息,使得模型生成的回答更加准确和有依据。
5. 生成最终响应:基础模型基于增强后的提示生成最终的回答。通过结合外部数据源和高质量的向量搜索,RAG 模型能够提供准确且详细的响应。
4. RAG 落地实现
下面将探讨基于检索的生成(RAG)模型在实际应用中需要达到的几个关键功能。这些功能确保 RAG 模型的高效运行和可靠性,涵盖了从数据管理到安全连接再到结果生成的各个方面。
4.1 完整管理的端到端 RAG 工作流程
RAG 模型需要支持端到端的工作流程,从数据注入到最终响应生成,确保整个过程高效且无缝。具体包括:
1. 当新数据到来时:
- 选择数据源:支持多种数据源,确保灵活的数据管理。
- 支持增量更新:能够处理新数据的增量更新,避免每次都重新处理所有数据。
- 多种数据文件格式支持:兼容不同格式的数据文件,增加系统的适应性。
2. 文档分块:
- 选择分块策略:根据需要选择固定分块、无分块或默认分块策略,以优化数据处理和检索效率。
3. 选择嵌入模型:
- 嵌入模型选择:根据具体需求选择适合的嵌入模型,确保生成高质量的向量嵌入。
4. 选择向量存储:
- 向量存储选择:支持多种向量存储选项,如 OpenSearch、Pinecone 和 Redis,以适应不同的性能和存储需求。
4.2 安全连接基础模型和数据源
RAG 模型需要能够安全地连接基础模型和各种数据源,确保数据的安全性和隐私保护。这包括建立安全的连接通道,保护数据在传输过程中的安全,并确保数据访问权限的严格管理。
4.3 轻松检索相关数据并增强提示
RAG 模型需要具备高效的数据检索和提示增强功能。通过高效的向量搜索,模型能够快速找到与用户查询相关的文档,并将其内容用于增强提示,从而生成更准确和相关的响应。
4.4 提供来源归因
在生成响应时,RAG 模型需要能够提供清晰的来源归因。这意味着模型不仅要给出答案,还要指出答案的来源,确保回答的可信度和透明度。
5. 小结
RAG的技术为大模型AI领域带来了新的可能性。通过结合外部数据和先进的嵌入模型,RAG不仅提升了内容的质量和准确性,还为个性化搜索带来了新的可能性。未来,随着其在AI领域的广泛应用,RAG将继续推动信息处理和用户体验的边界的进一步拓展。
