前言
AI模型开发平台提供模型代码开发IDE,模型训练,模型微调,模型部署等业务能力。我们希望在用户使用这些功能的过程中,能够监控相应功能的失败率,提供线上失败告警,从而快速响应线上问题。业界有很多成熟的监控告警工具,比如Skywalking, prometheus, victoriametrics等等,本文介绍如何利用业界监控技术实现我们自定义的业务指标的监控和告警能力。
架构
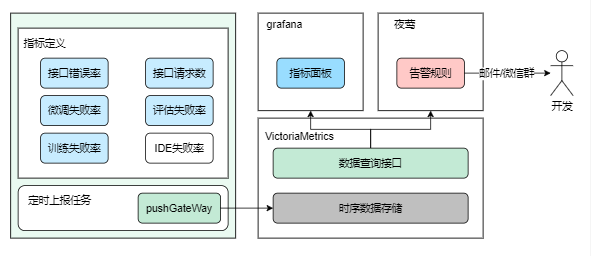
从架构图可以看到,整个监控链路涉及如下几个模块
- 业务系统
- 时序数据库存储,如Prometheus/VictoriaMetrics
- 监控指标展示,如grafana等
- 指标告警能力,如夜莺
实现
为实现业务监控,大体需要一下几个步骤
- 技术选择
- 业务指标的定义
- 业务指标上报到时序数据库
- 根据指标数据配置监控面板
- 根据指标数据配置告警规则
技术选择
prometheus指标已经成为事实的业务标准,所以指标采集,上报都依赖prometheus的指标协议。
时序数据库有很多,开源的包括prometheus, VictoriaMetrics。两者性能比较如下:
| 比较 | Prometheus | VictoriaMetrics |
|---|---|---|
| 数据采集 | 基于拉动 | 基于拉式和推式 |
| 数据摄取 | 每秒高达 240,000 个样本 | 每秒高达 360,000 个样本 |
| 数据查询 | 每秒高达 80,000 次查询 | 每秒高达 100,000 次查询 |
| 内存使用情况 | 高达 14GB RAM | 高达 4.3GB 的 RAM |
| 数据压缩 | 使用LZF压缩 | 使用 Snappy 压缩 |
| 磁盘写入频率 | 更频繁地将数据写入磁盘 | 减少将数据写入磁盘的频率 |
| 磁盘空间使用情况 | 需要更多磁盘空间 | 需要更少的磁盘空间 |
| 查询语言 | PromQL | MetricsQL(向后兼容 PromQL) |
可以看出VM兼容Prom的数据格式,且数据压缩比更高,内存和硬盘使用较少,另外提供pull和push两种数据采集能力,更方便业务使用。例如用prometheus, 那么数据采集需要在业务服务侧安装agent,业务服务先把数据上报给agent, prometheus再从agent定期拉取。使用vm则不依赖agent, 可以直接通过rest接口把业务指标上报给vm。
监控面板和告警规则配置大同小异,公司提供的夜莺服务能同时支持面板配置,告警规则配置等能力,因此直接选了夜莺。
指标定义
指标的数据模型协议有两种,openMetrics和opentelemetry,两种协议可以互相转换翻译。
openMetrics兼容prometheus, 具体数据格式如下
<metric name>{<label name>=<label value>, ...}
根据业务指标定义指标名称,标签名称等。4种不同的指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。
计数器
Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如http_requests_total,node_cpu都是 Counter 类型的监控指标。一般在定义Counter类型指标的名称时推荐使用_total作为后缀。
通过 counter 指标我们可以和容易的了解某个事件产生的速率变化。
仪表盘
Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
通过Gauge指标,我们可以直接查看系统的当前状态
直方图
Histogram 类型的指标同样用于统计和样本分析。与 Summary 类型的指标相似之处在于 Histogram 类型的样本同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。不同在于 Histogram 指标直接反应了在不同区间内样本的个数,区间通过标签len进行定义。同时对于Histogram的指标,可以通过 histogram_quantile() 函数计算出其值的分位数。
摘要
Summary 主用用于统计和分析样本的分布情况。比如某 Http 请求的响应时间大多数都在 100 ms 内,而个别请求的响应时间需要 5s,那么这中情况下统计指标的平均值就不能反映出真实情况。而如果通过 Summary 指标我们能立马看响应时间的9分位数,这样的指标才是有意义的。
业务已经提供多种prometheus数据采集的SDK,不同SDK的使用方式有些微差异,但最终上报的数据格式都是一样的。SDK可以用prometheusClient, 也可以直接用SpringMetrics提供的封装,比较限制指标的采集,标签修改,且不提供push数据上报方式。最终选择prometheusClient来采集
数据上报
业务代码通过pushgateway方式上报到victoriametrics。和prometheus的pushgateway不是一回事。不需要安装额外的组件,通过http接口,定时上报。上报的数据也是每个固定时间“刮下“监控数据提交。数据格式:openmetrics格式
提供定时任务,每个n分钟刮取数据,调用push接口上报给vm。从VMUI查询数据是否上报成功
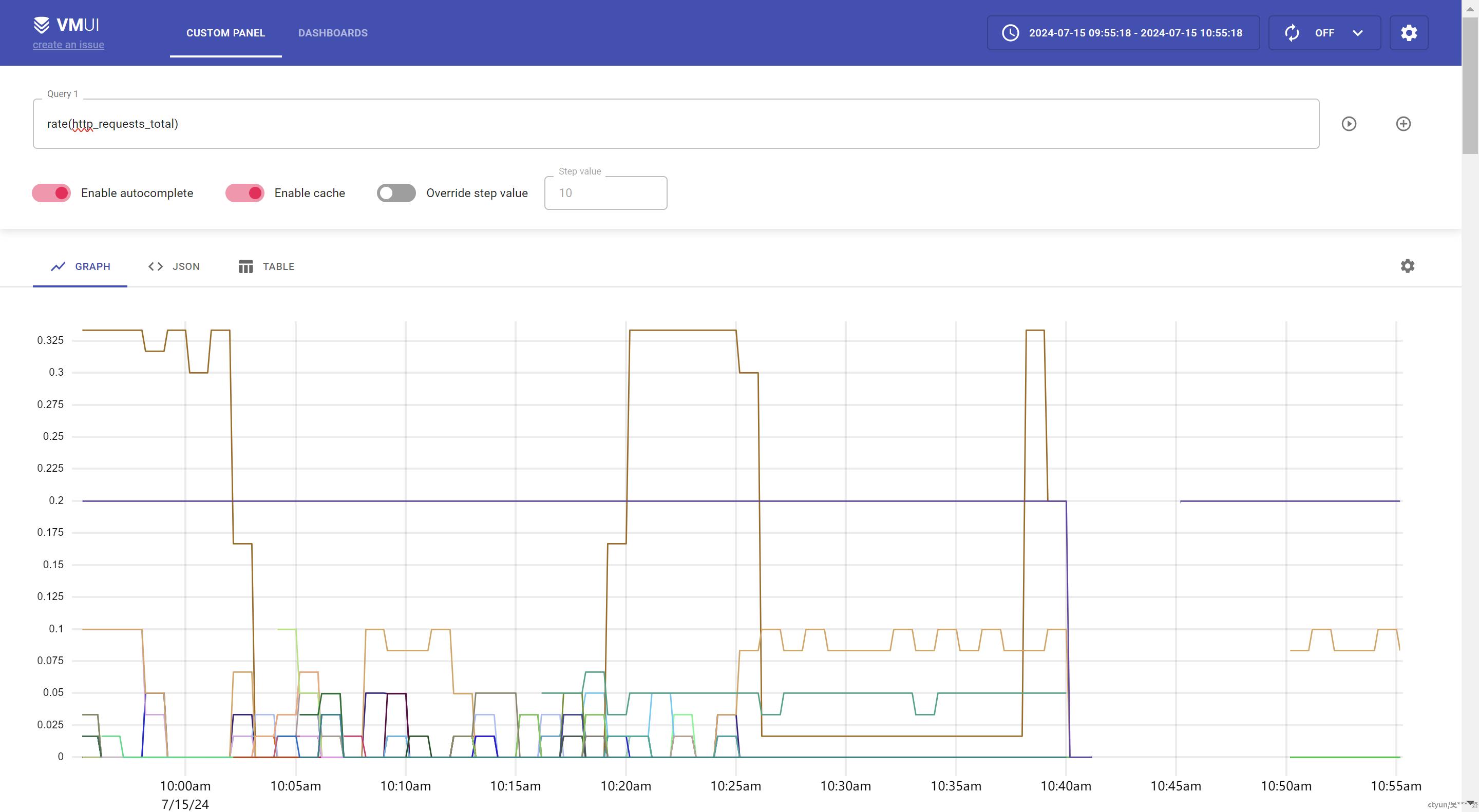
监控面板
在夜莺仪表盘配置监控面板,通过PromQL查找业务指标数据,展示在面板上。例如监控http请求数,需要把http_request_total这个指标的数据查找出来。这个指标是Counter类型,直接展示的话,会看到数据一直在递增,不符合我们的需求,需要用prometheus的rate函数计算数据的变化率来查看每秒请求数。
PromQL: http_request_total

PromQL: rate(http_requests_total{}[1m]) 其中rate是PromQL里计算数据变化率的函数, http_requests_total是业务监控指标名称;花括号{}中可以设置选择标签,比如要查看请求成功的数据{code=200}; [1m]指定了要计算的数据的时间范围,即计算1分钟的内的Counter数据的变化率。
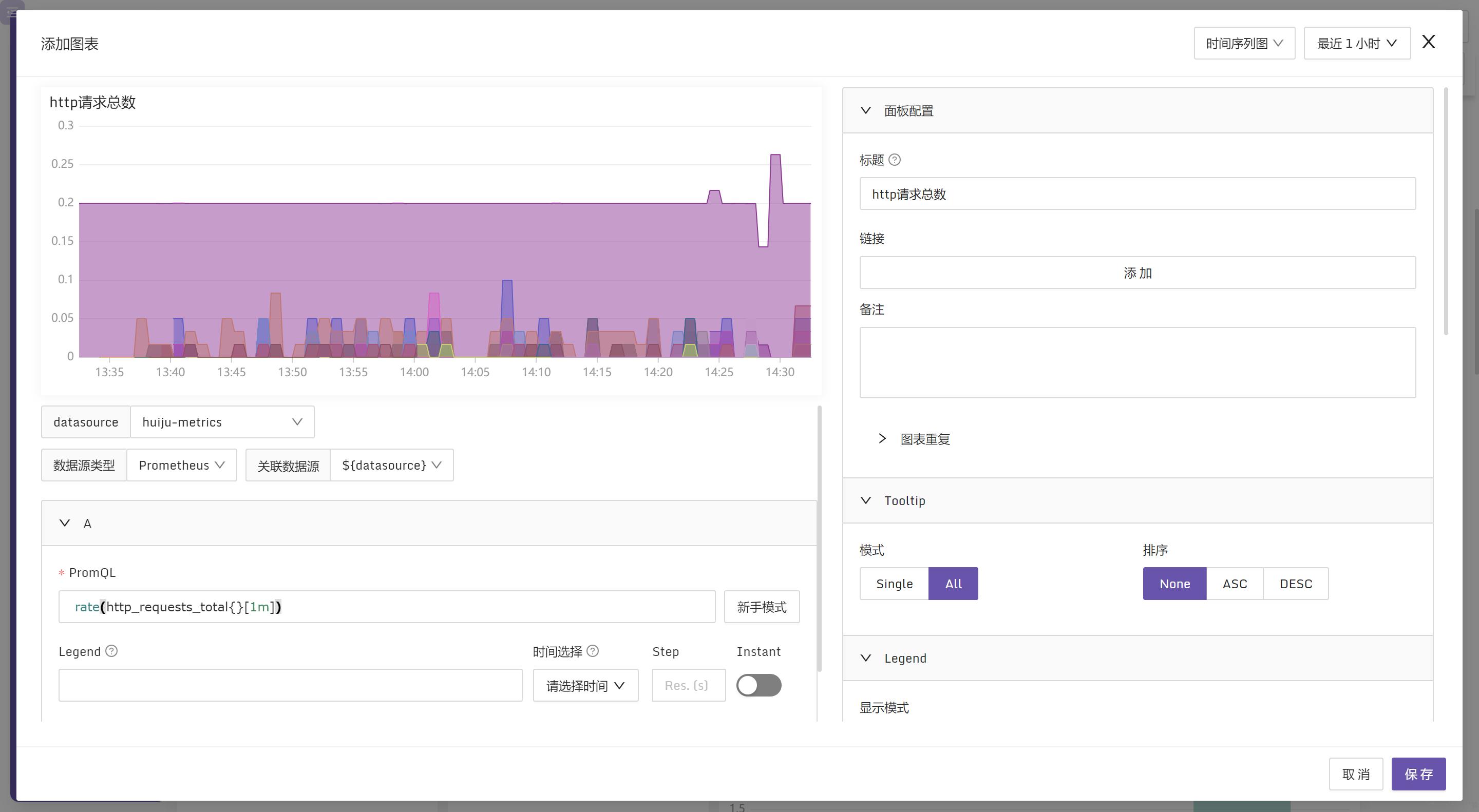
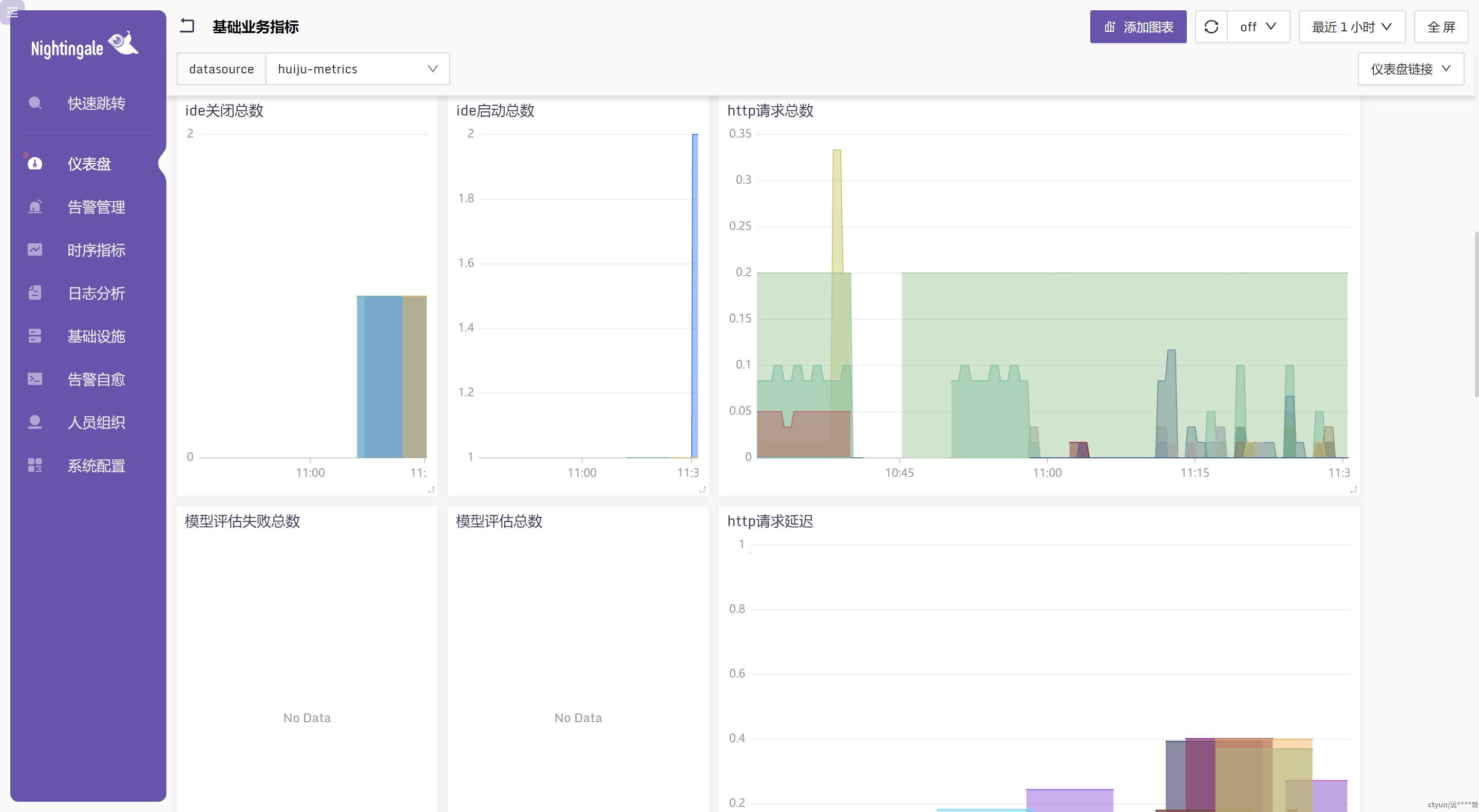
多个指标编排到同一个面板中,实现多指标的监控
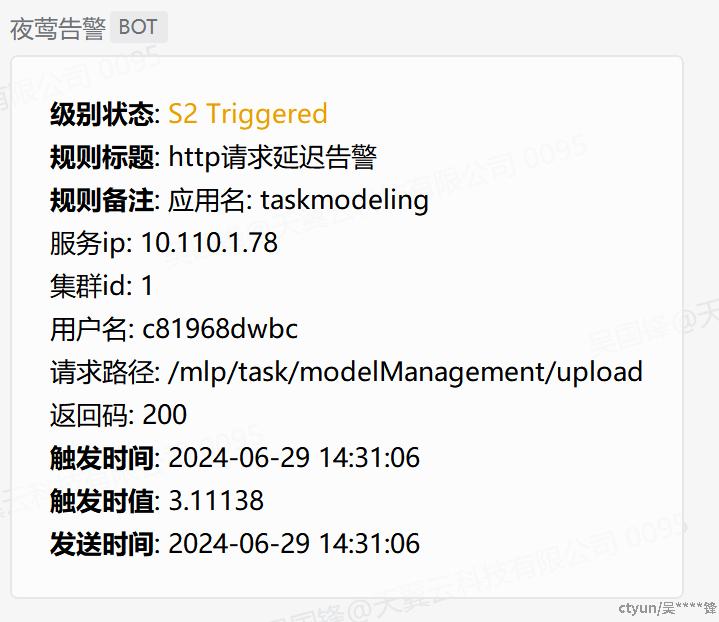
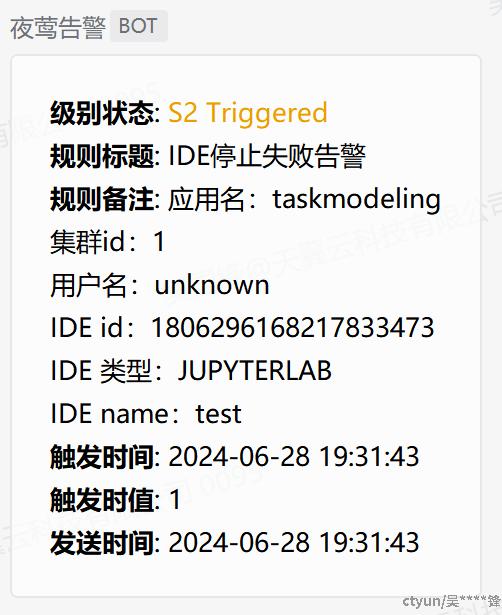
告警规则
同样使用PromQL可以在夜莺中实现对监控数据异常的告警。告警规则可以设置
- 触发告警的条件,比如请求失败数,请求延迟超过某个阈值等
- 告警的方式,如邮件,微信群等
- 告警的时间间隔
- 自定义告警的数据内容格式,比如告警的请求连接,服务名称, ip, 请求的用户等等