



Branchformer
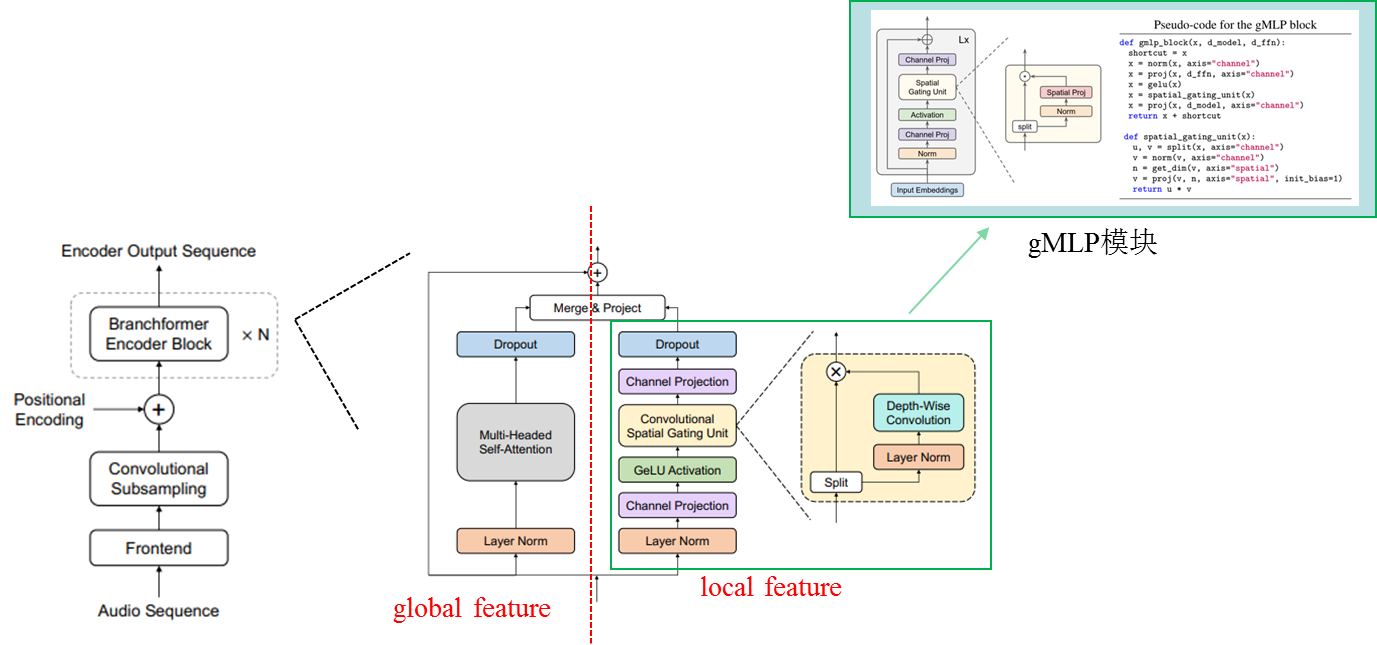
1. 并行的双分支结构:1)利用multi-headed self-attention机制提取输入序列中的全局特征;2)引入了cgMLP结构,意在捕获音频序列中的局部特征。
2. cgMLP模块:利用深度可分离卷积于线性门控单元的组合来学习序列中的特征表示。
3. Merge:Concat与可学习参数加权等多种特征组合方式
E-Branchformer
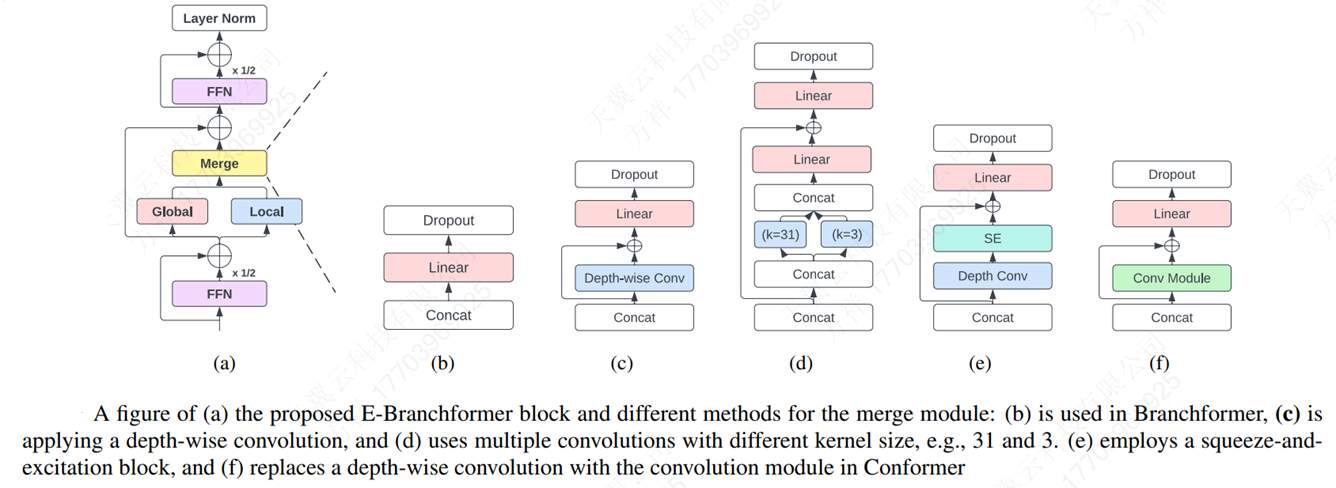
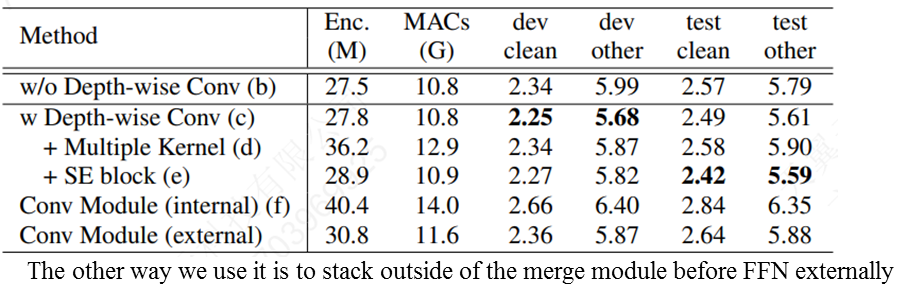
Efficient Conformer

Squeezeformer
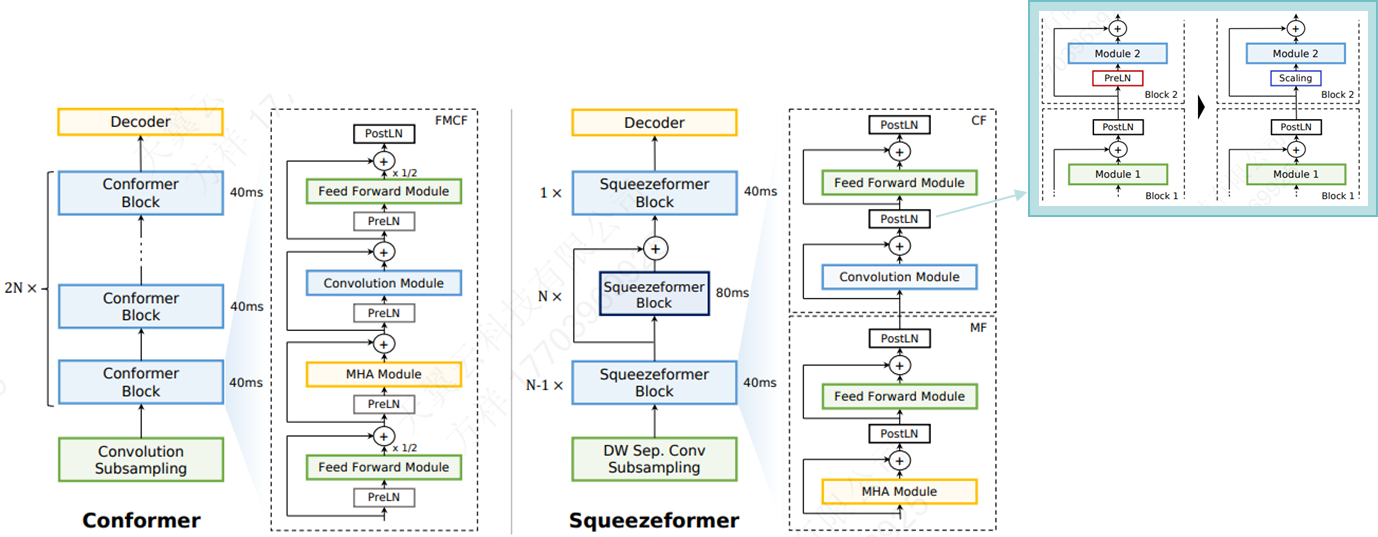
1. Temporal U-Net Architecture
•ASR训练过程中,中间层的帧embedding相似度很高,因此在时间维度上对中间层的帧数进行压缩;
•时间下采样会导致训练不稳定和发散;因此最后一层加上上采样
2. Transformer-Style Block
•由Conformer的FMCF结构替换成MF-CF结构,以同时捕获全局/局部信息
3.微观结构
•激活函数全部/统一替换为GLU(避免硬件部署复杂化)
•全部采用PostLN(减少冗余)
Paraformer
一种具有高识别率与计算效率的单轮非自回归模型

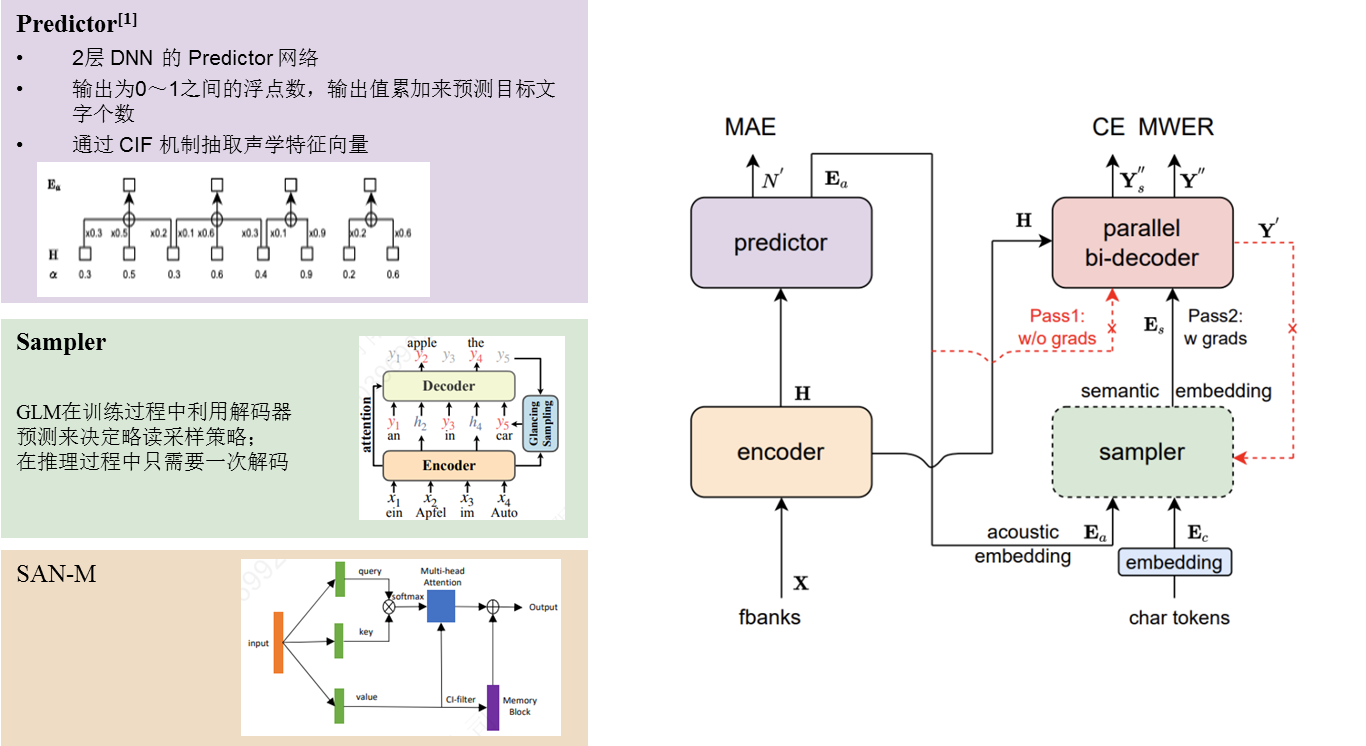
1. Encoder:Memory Equipped Self-Attention(SAN-M), Self-Attention, Conformer
2. Predictor :基于 CIF 来预测语音中目标文字个数以及抽取目标文字对应的声学特征向量
3. Sampler:采用Glancing LM,将声学特征向量与目标文字向量变换成含有语义信息的特征向量,配合双向的 Decoder 来增强模型对于上下文的建模能力
4. Decoder:单/双向SAN-M
5. Loss:MAE+CE+MWER
部分实验结果对比

参考资料:
1. arxiv.org/pdf/2207.02971.pdf
2. blog.csdn.net/weixin_48827824/article/details/131477394
3. arxiv.org/ftp/arxiv/papers/2111/2111.03940.pdf
4. arxiv.org/pdf/1606.08415.pdf
5. arxiv.org/pdf/2210.00077.pdfhformer
6. arxiv.org/pdf/2109.01163.pdf
7. zhuanlan.zhihu.com/p/598746994
8. arxiv.org/pdf/2206.00888.pdf
9. arxiv.org/pdf/2206.08317.pdf
10.mp.weixin.qq.com/s/xQ87isj5_wxWiQs4qUXtVw
11.arxiv.org/pdf/1905.11235.pdf
12.arxiv.org/pdf/2006.01713.pdf
13.aclanthology.org/2021.acl-long.155.pdf
14.github.com/wenet-e2e/wenet/tree/main/examples/aishell
