


背景
数据血缘关系在元数据管理中是非常重要的内容,典型应用如大数据平台通过SQL分析关系。
数据血缘回答了数据是“从哪里来,路上发生了什么”的问题,不仅能展示数据来龙去脉,还能定位异常数据影响范围。
数据血缘为字段关系提供了极大的可见性,能大大提高在数据/字段分析过程中追溯根本原因的能力,同时也能在修改更新数据时,通过依赖数据的影响性分析,可以快速定位出元数据修改会影响到哪些下游系统,哪些字段,从而减少系统升级改造带来的风险。
当系统进行升级改造时,能动态数据结构变更、删除及时告知下游系统。
字段血缘分析
基于分发订阅模式
很多复杂的业务系统,如视频系统的排播、运营系统,通常会设计一个数据总线来做字段变更消息的分发,需求方通过微服务来接收字段变更消息再做异步计算,计算逻辑分散在很多微服务中,字段间修改影响关系很难评估。运营也有诉求,修改字段同步告知关联字段影响及预期会修改的目标值。
以下为一个简化的总线分发-订阅型架构,后面分析都是基于此架构展开
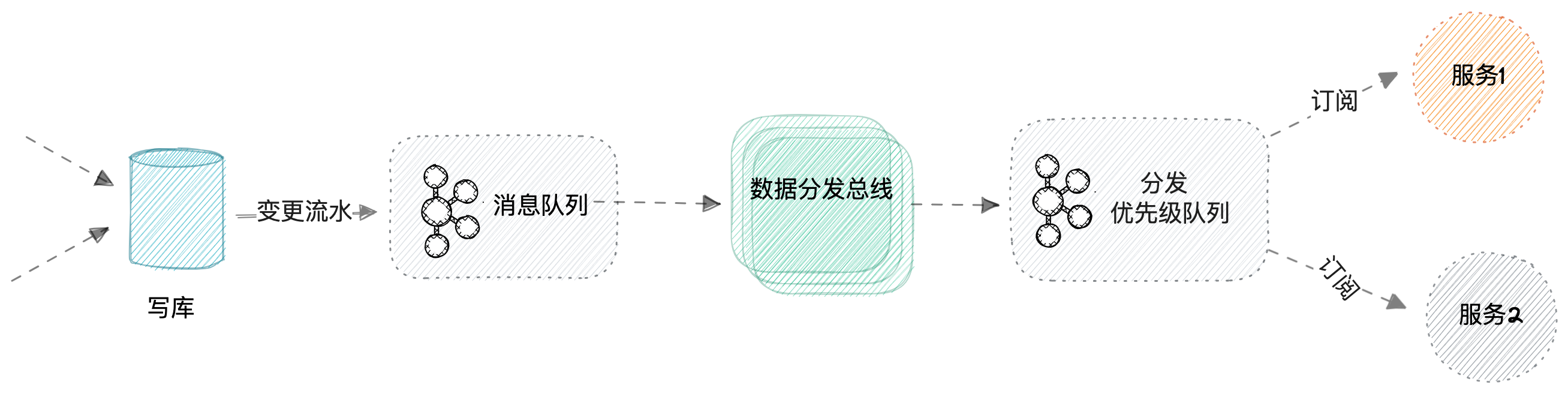
总线分发-订阅模式,一般是选择订阅字段列表,关注这些字段变化,同时选择要写入的字段列表,服务方控制好需求方申请的订阅、加工字段权限,输出的字段关系较为准确。
根据订阅-加工的字段列表,我们很容易输出如下关系:
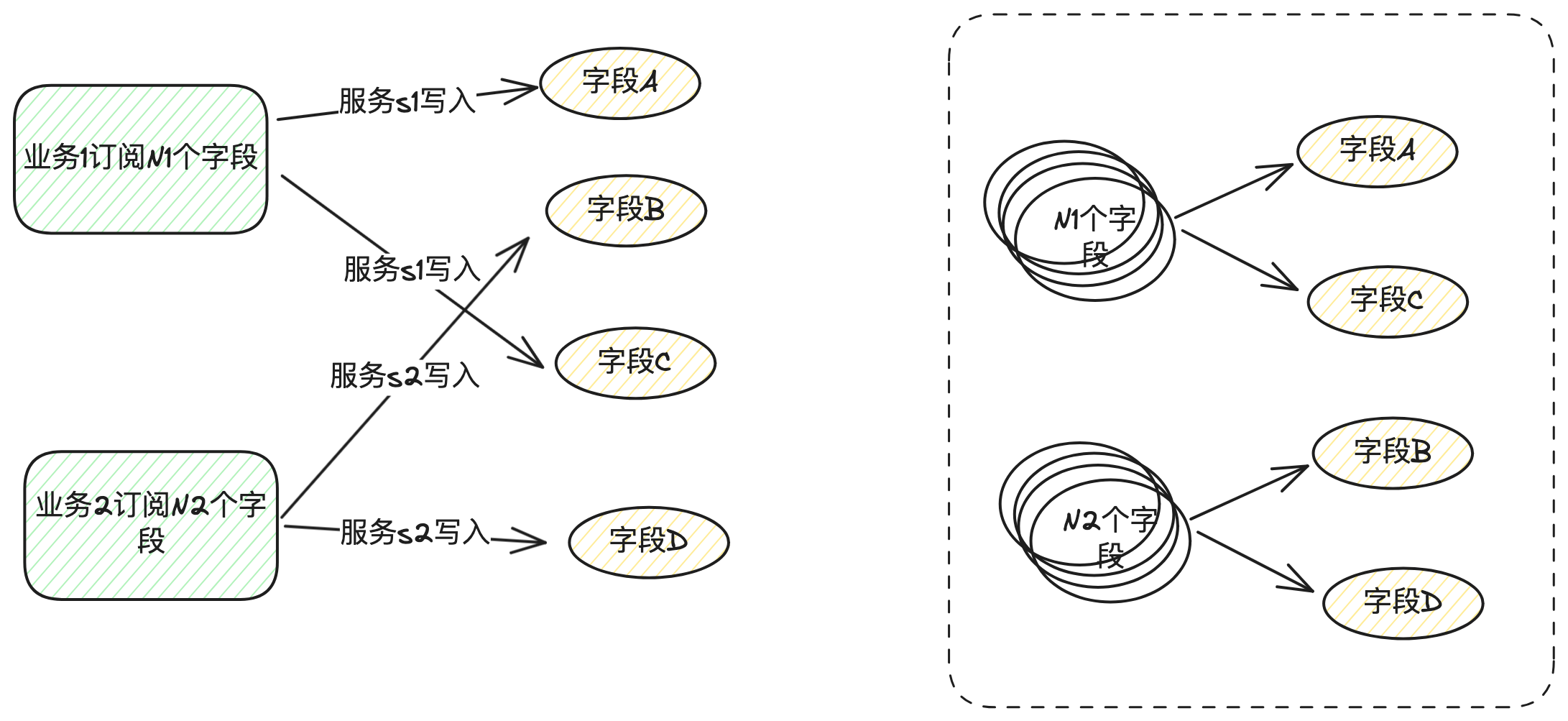
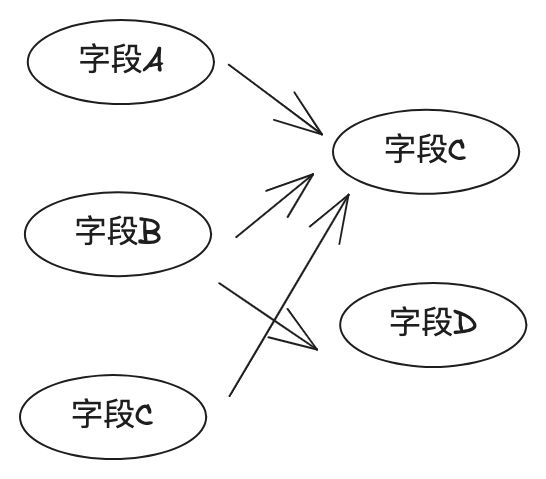
上图可以看出几个问题:
- 字段关系很发散,N对N的关系使得字段间血缘实用性大大减弱
- 订阅字段和加工字段是否存在实际关系?因为订阅-加工模式,是纯人工申请审批,并未做代码级别检查,实际使用时为了省事往往会申请一个大范围字眼权限,容易出现订阅了一堆字段,写入了一堆字段,都是一个通用服务来处理,这样会导致字段关系混乱,多次迭代后血缘关系基本不可用。
基于以上考虑,我们需要一种方法能约束订阅-加工字段的真实关系,同时能对N对N的关系做合理的剪枝。
基于trace链路
上面分发-订阅模式可以得出粗略的字段血缘关系,为了统计出较为真实的字段关系,我们可以依据trace
链路数据来做关系的验证和剪枝。(这里前提是微服务已经统一链路跟踪)
可以通过统计trace链路里的span信息,原理大体如下:
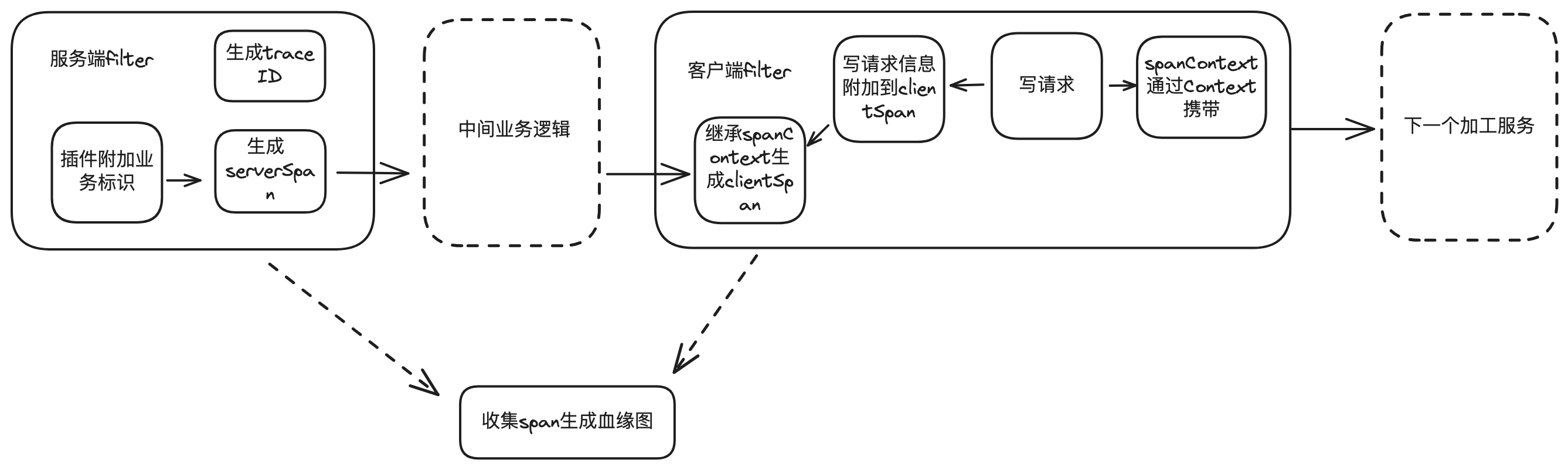
可以从span中提取对应的req,解析出字段,形成字段级血缘关系,经过加工处理,可以放入图数据库,方便查询多跳关系。
但是这里有个问题,如果数据总线服务会为每一个订阅者启动一个单独的 消息队列消费组,即同一条数据变更流水会被同一个服务的多个消费组收到并处理,产生多个 Server,这样span信息会无限膨胀,统计出关系变得十分困难。
但实际上,并非每一个消费组所产生的 Span 均为具有实际业务意义的。如上图中所示,其中有很多 Span 均为在消费组的处理逻辑中、按照订阅者配置的匹配逻辑进行过滤后直接返回。并未触发任何下游字段异步计算服务,亦未进行任何写操作。
我们可以增加 ServerSpan 级别属性来解决这个问题。
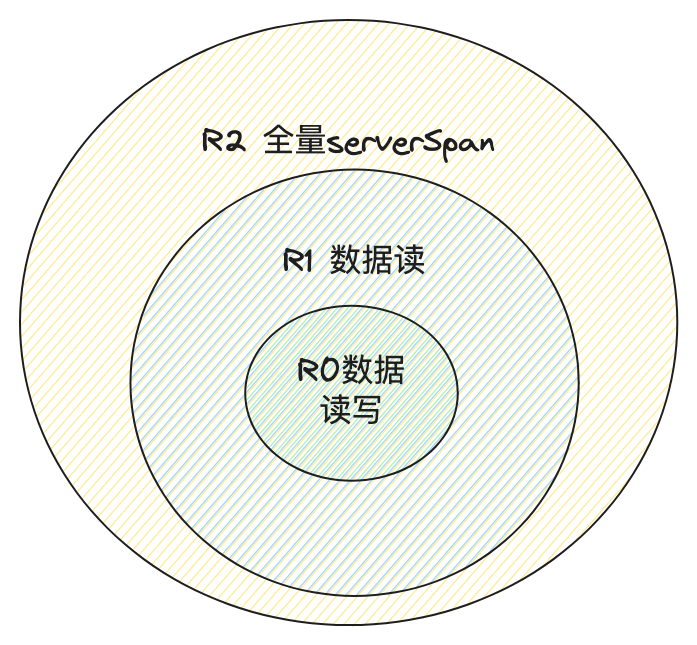
将全量 ServerSpan 分为如下三个级别 [Ring]:
Ring 2 — 全量未经过滤的 ServerSpan
Ring 1 — 仅含数据读,无数据写的 ServerSpan
Ring 0 — 含数据写的 ServerSpan
而上层 ServerSpan 的级别应为 [所有下层 ServerSpan + 本身进行的数据读写操作] 的最小值
经过有效过滤后,我们可以得到比第一步更精准的实际运行的字段血缘关系
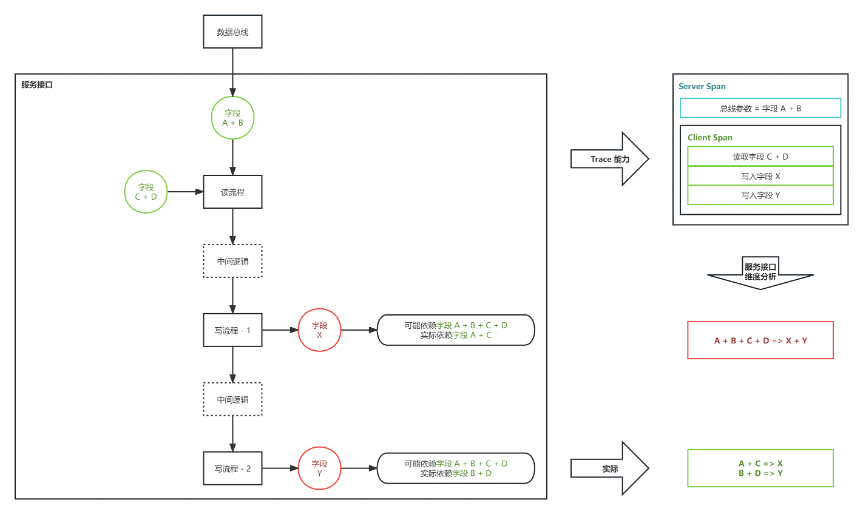
这里还有一个问题,根据目前的 Trace 链路数据,我们可以得知调用单个服务接口时,发生的所有外部服务调用以及存储读写操作,以及这些操作发生的时间顺序。然而现有的服务框架 + 编译后运行时数据采集的方式,无法程序化地完成对服务内部逻辑的梳理。
场景1:单次读操作对应多次写操作
场景2:读写操作交叉 / 冗余字段读取
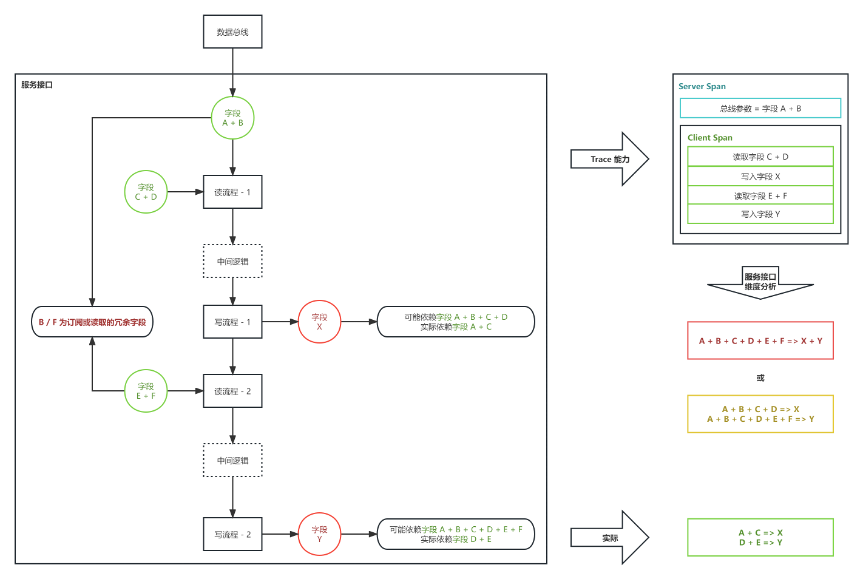
如上图所示,在现在trace 能力的基础下,若异步字段计算服务中存在单次读操作对应多次写操作、读写操作交叉、冗余字段读取等情况时,依赖服务接口粒度的 Trace 往往无法得到精确的字段依赖关系。
后续我们将继续探讨如何更进一步获取更精确的字段级血缘关系。
