


什么是 Rebalance 机制?
Rebalance 本质上是一种协议,规定了一个 Consumer Group 下的所有 Consumer 如何达成一致,来分配订阅 Topic 的每个分区。
当集群中有新成员加入,或者某些主题增加了分区之后,消费者是怎么进行重新分配消费的?这里就涉及到重平衡(Rebalance)的概念。
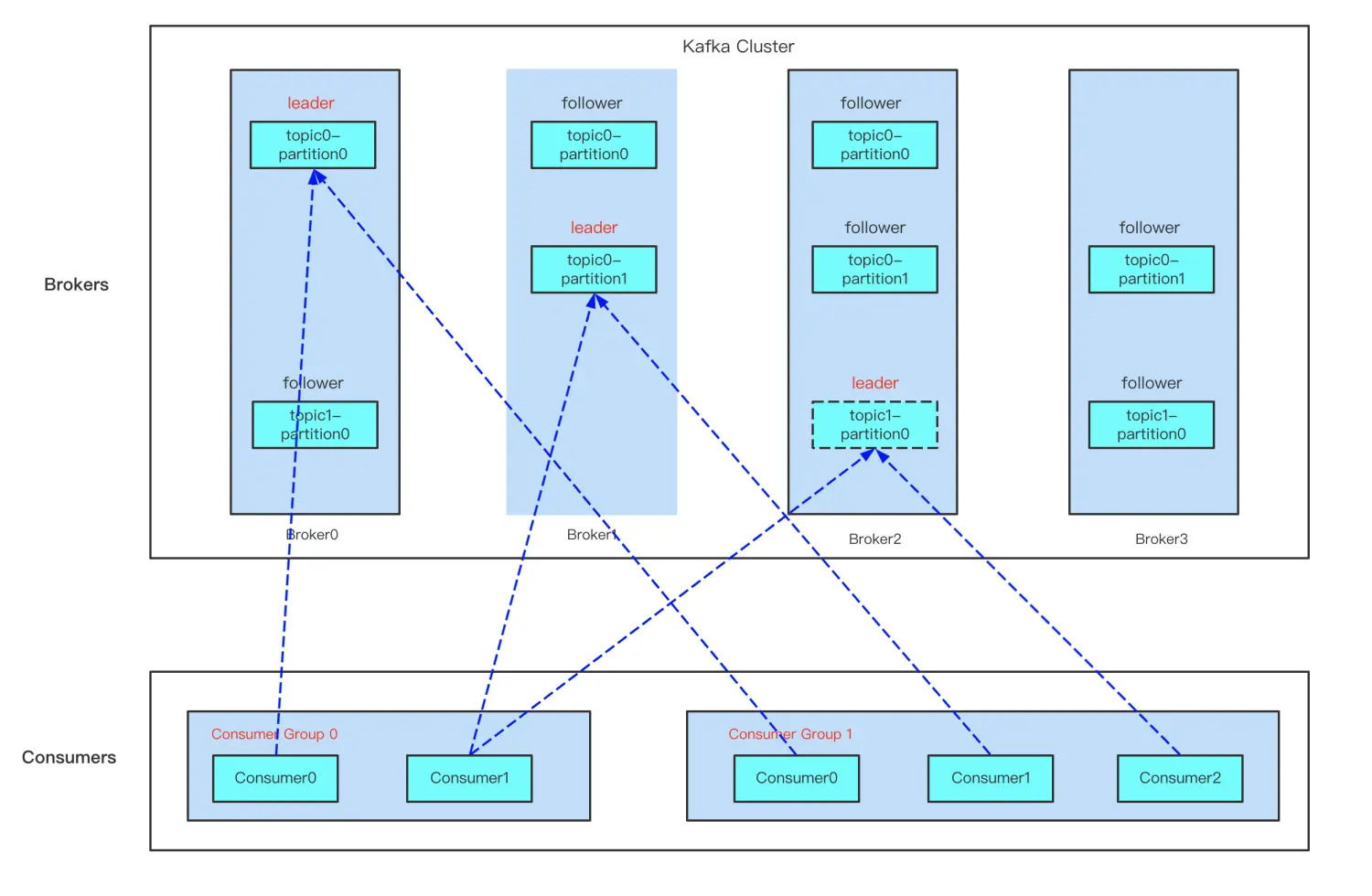
从图中可以找到消费组模型的几个概念:
- 同一个消费组,一个分区只能被一个消费者订阅消费,但一个消费者可订阅多个分区,也就是说每条消息只会被同一个消费组的某一个消费者消费,确保不会被重复消费;
- 一个分区可被不同消费组订阅,这里有种特殊情况,假如每个消费组只有一个消费者,这样分区就会广播到所有消费者上,实现广播模式消费。
要想实现以上消费组模型,那么就要实现当外部环境变化时,比如主题新增了分区,消费组有新成员加入等情况,实现动态调整以维持以上模型,那么这个工作就会交给 Kafka 重平衡(Rebalance)机制去处理。
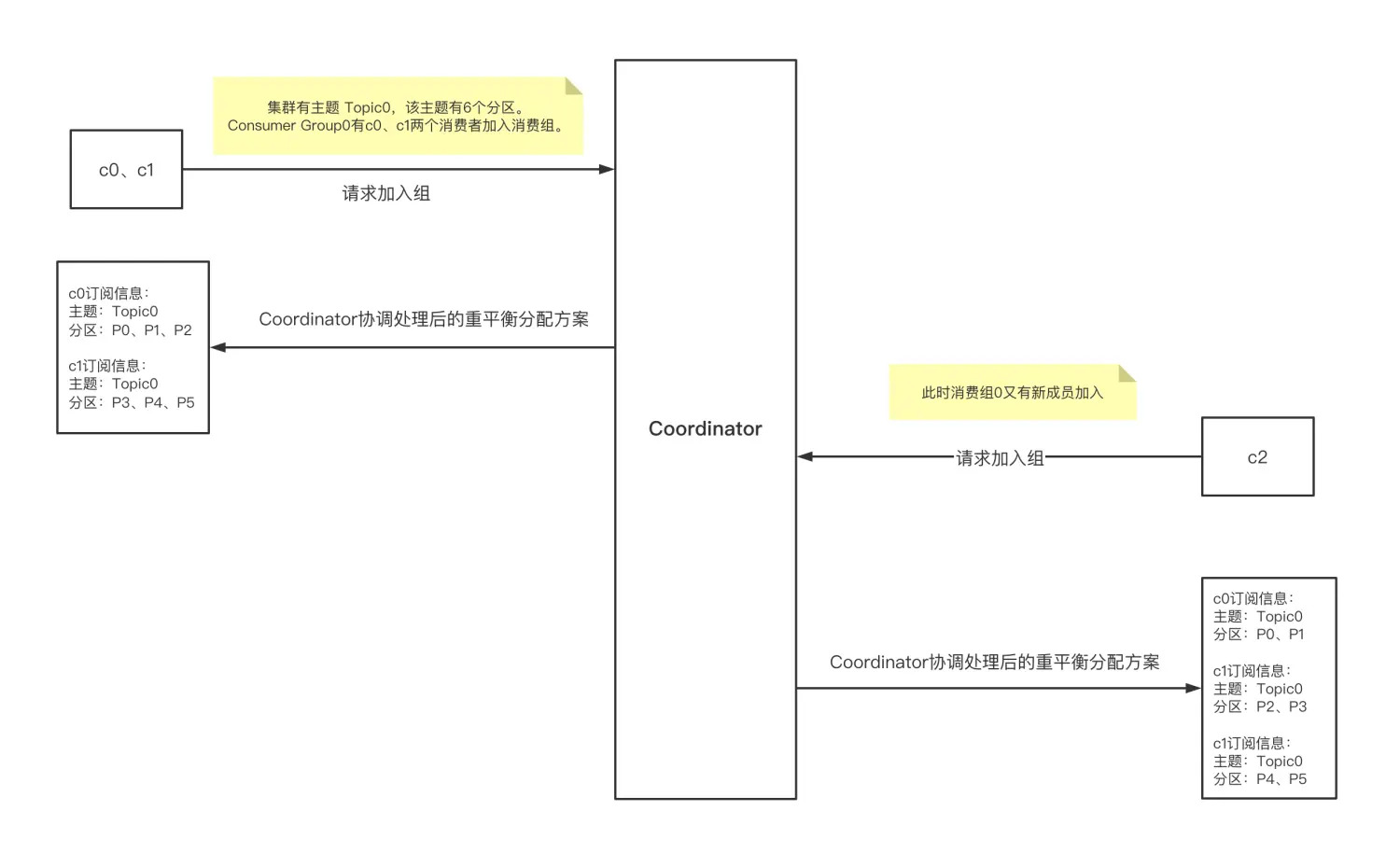
从图中可看出,Kafka 重平衡是外部触发导致的,下面来看下触发 Kafka 重平衡的时机有哪些。
触发 Rebalance 机制的时机
- 有新的 Consumer 加入 Consumer Group
- 有 Consumer 宕机下线。Consumer 并不一定需要真正下线,例如遇到长时间的 GC、网络延迟导致消费者长时间未向 GroupCoordinator 发送 HeartbeatRequest 时,GroupCoordinator 会认为 Consumer 下线。
- 有 Consumer 主动退出 Consumer Group(发送 LeaveGroupRequest 请求)。比如客户端调用了 unsubscribe() 方法取消对某些主题的订阅。
- Consumer 消费超时,没有在指定时间内提交 offset 偏移量。
- Consumer Group 所对应的 GroupCoordinator 节点发生了变更。
- Consumer Group 所订阅的任一主题或者主题的分区数量发生变化。
Group 状态变更
消费端
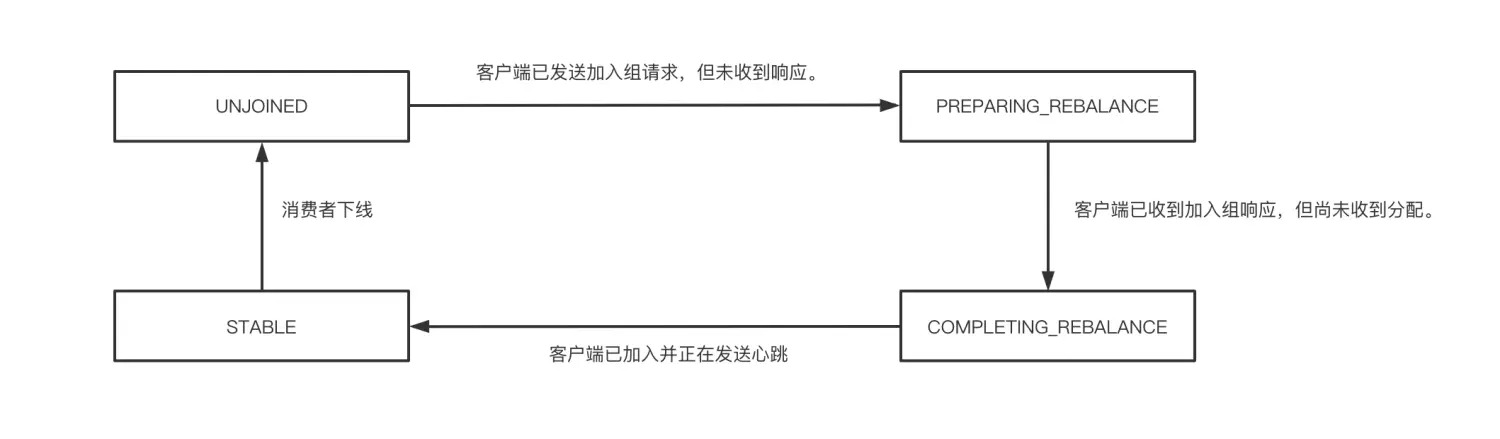
在 Consumer 侧的门面 ConsumerCoordinator,它继承了 AbstractCoordinator 抽象类。在协调器 AbstractCoordinator 中的内部类 MemberState 中我们可以看到协调器的四种状态,分别是未注册、重分配后没收到响应、重分配后收到响应但还没有收到分配、稳定状态。
服务端
对于 Kafka 服务端的 GroupCoordinator 则有五种状态 Empty、PreparingRebalance、CompletingRebalance、Stable、Dead。他们的状态转换如下图所示:
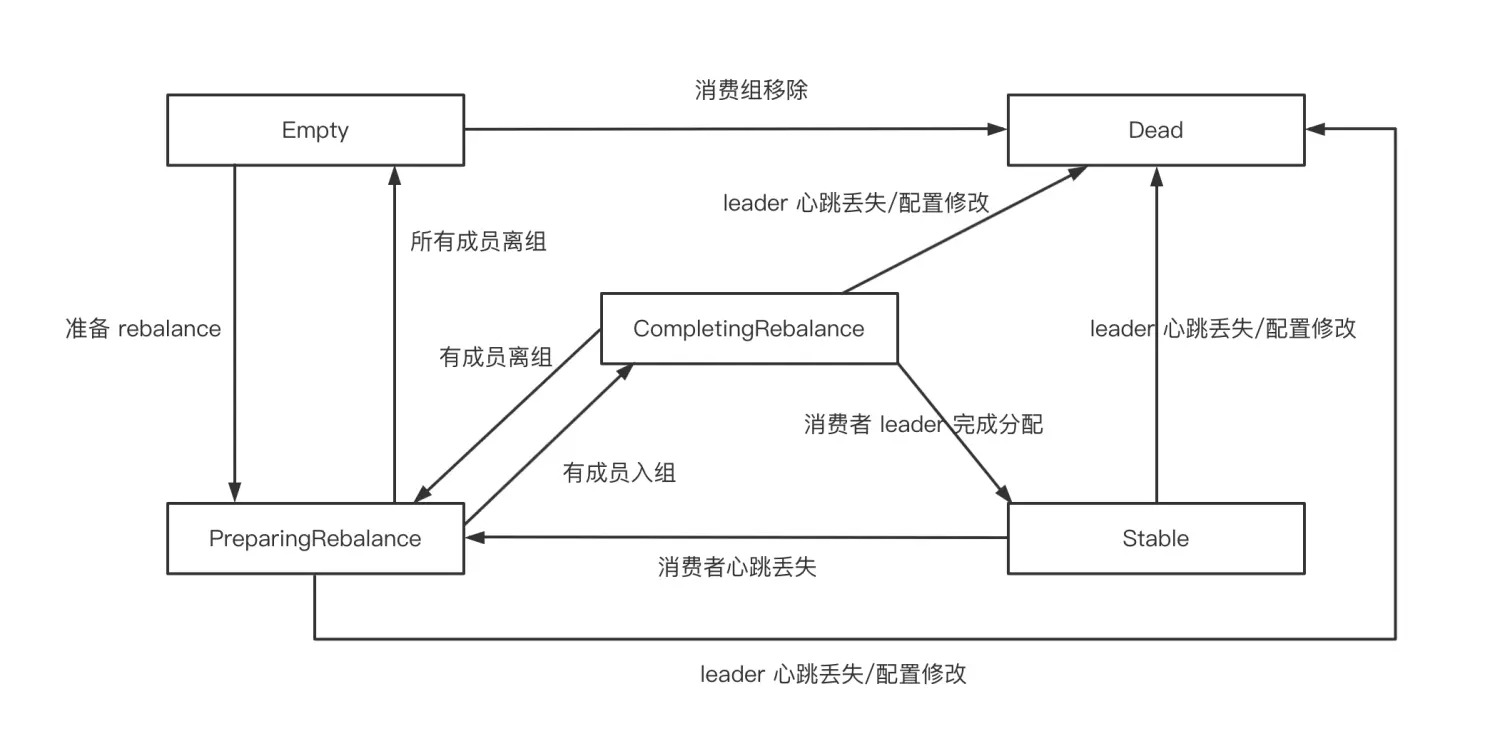
- 一个消费者组最开始是 Empty
- 重平衡开启后,会置于 PreparingRebalance 等待成员加入。
- 之后变更到 CompletingRebalance 等待分配方案
- 最后流转到 Stable 完成 Rebalance
- 当有成员变动时,消费者组状态从 Stable 变为 PreparingRebalance。
- 此时所有现存成员需要重新申请加入组
- 当所有组成员都退出组后,消费者组状态为 Empty。
- 消费者组处于 Empty 状态,Kafka 会定期自动删除过期 offset。
旧版消费者客户端的问题
ConsumerCoordinator 与 GroupCoordinator 的概念是针对 Kafka 0.9.0 版本后的消费者客户端而言的,我们 暂且把 Kafka 0.9.0 版本之前的消费者客户端称为旧版消费者客户端。旧版消费者客户端是使用 Zookeeper 的监听器(Watcher)来实现这些功能的。
每个消费组 <group> 在 Zookeeper 中维护了一个 /consumers/<group>/ids 路径,在此路径下使用临时节点记录隶属于此消费组的消费者的唯一标识 consumerldString , consumerldString 由消费者启动时创建。消费者的唯一标识由 consumer.id+主机名+时间戳+UUID的部分信息 构成,其中 consumer.id 是旧版消费者客户端中的配置,相当于新版客户端中的 client.id。比如某个消费者的唯一标识为 consumerld_localhost-1510734527562-64b377f5,那么其中 consumerld 为指定的 consumer.id, localhost 为计算机的主机名,1510734527562代表时间戳,而 64b377f5 表示 UUID 的部分信息。
下图与 /consumers/<group>/ids 同级的还有两个节点:owners 和 offsets
/consumers/<group>/owners路径下记录了分区和消费者的对应关系/consumers/<group>/offsets路径下记录了此消费组在分区中对应的消费位移
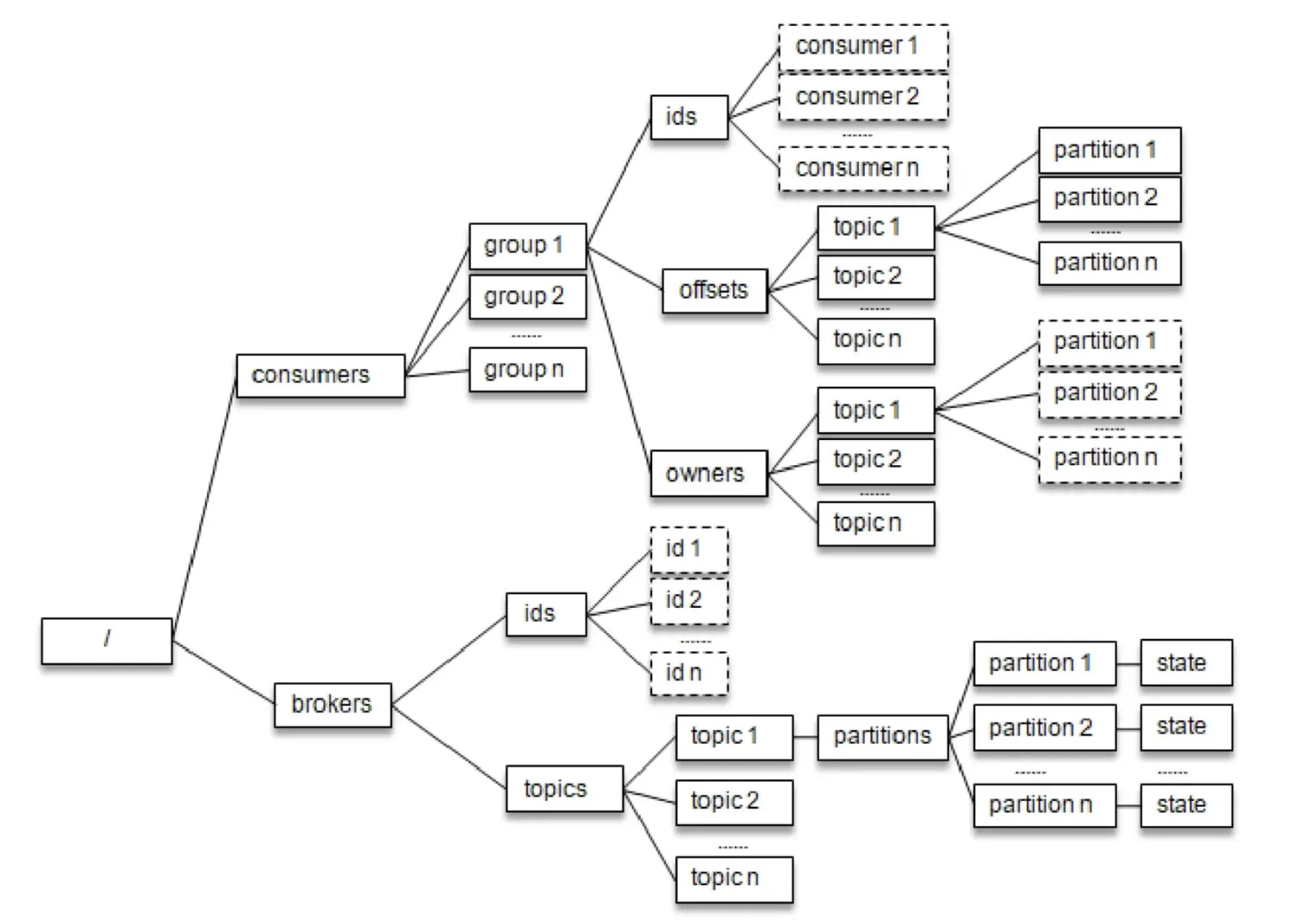
每个 broker、主题和分区在 Zookeeper 中也都对应一个路径:
/brokers/ids/<id>记录了 host、port 及分配在此 broker 上的主题分区列表;/brokers/topics/<topic>记录了每个分区的 leader 副本、ISR 集合等信息。/brokers/topics/<topic>/partitions/<partition>/state记录了当前 leader 副本、leader epoch 等信息。
每个消费者在启动时都会在 /consumers/<group>/ids 和 /brokers/ids 路径上注册一个监听器。当 /consumers/<group>/ids 路径下的子节点发生变化时,表示消费组中的消 费者发生了变化;当 /brokers/ids 路径下的子节点发生变化时,表示 broker 出现了增减。这样通过 Zookeeper 所提供的 Watcher,每个消费者就可以监听消费组和 Kafka 集群的状态了。
这种方式下每个消费者对 Zookeeper 的相关路径分别进行监听,当触发再均衡操作时,一个消费组下的所有消费者会同时进行再均衡操作,而消费者之间并不知道彼此操作的结果,这样可能导致 Kafka 工作在一个不正确的状态。与此同时,这种严重依赖于 Zookeeper 集群的做法还有两个比较严重的问题。
羊群效应(Herd Effect):所谓的羊群效应是指 Zookeeper 中一个被监听的节点变化,大量的 Watcher 通知被发送到客户端,导致在通知期间的其他操作延迟,也有可能发生类似死锁的情况。脑裂问题(Split Brain):消费者进行再均衡操作时每个消费者都与 Zookeeper 进行通信以判断消费者或 broker 变化的情况,由于 Zookeeper 本身的特性,可能导致在同一时刻各个消费者获取的状态不一致,这样会导致异常问题发生。
Rebalance 机制的原理
Kafka 0.9.0 版本后的消费者客户端对此进行了重新设计,将全部消费组分成多个子集,每个消费组的
子集在服务端对应一个 GroupCoordinator 对其进行管理,GroupCoordinator 是 Kafka 服务端中用于管理消费组的组件。而消费者客户端中的 ConsumerCoordinator 组件负责与 GroupCoordinator 进行交互。
- Rebalance 完整流程需要 Consumer & Coordinator 共同完成
- Consumer 端 Rebalance 步骤
- 加入组:对应 JoinGroup 请求
- 等待 Leader Consumer 分配方案:对应 SyncGroup 请求
- 当组内成员加入组时,Consumer 向协调者发送 JoinGroup 请求。
- 每个 Consumer 会上报自己订阅的 topic
- Coordinator 收集到所有 JoinGroup 请求后,从这些成员中选择一个担任消费者组的 Leader
- 通常第一个发送 JoinGroup 请求的自动成为 Leader
- Leader Consumer 的任务是收集所有成员的 topic,根据信息制定具体的 partition consumer 分配方案。
- 选出 Leader 后,协调者把所有 topic 信息封装到 JoinGroup Response 中,发送给 Leader。
- Leader Consumer 做出统一分配方案,进入到 SyncGroup 请求。
- Leader Consumer 向协调者发送 SyncGroup,将分配方案发给协调者。
- 其他成员也会发出 SyncGroup 请求
-
协调者以 SyncGroup Response 的方式将方案下发给所有成员
- 所有成员成功接收到分配方案,消费者组进入 Stable 状态,开始正常消费。
Broker 端重平衡场景
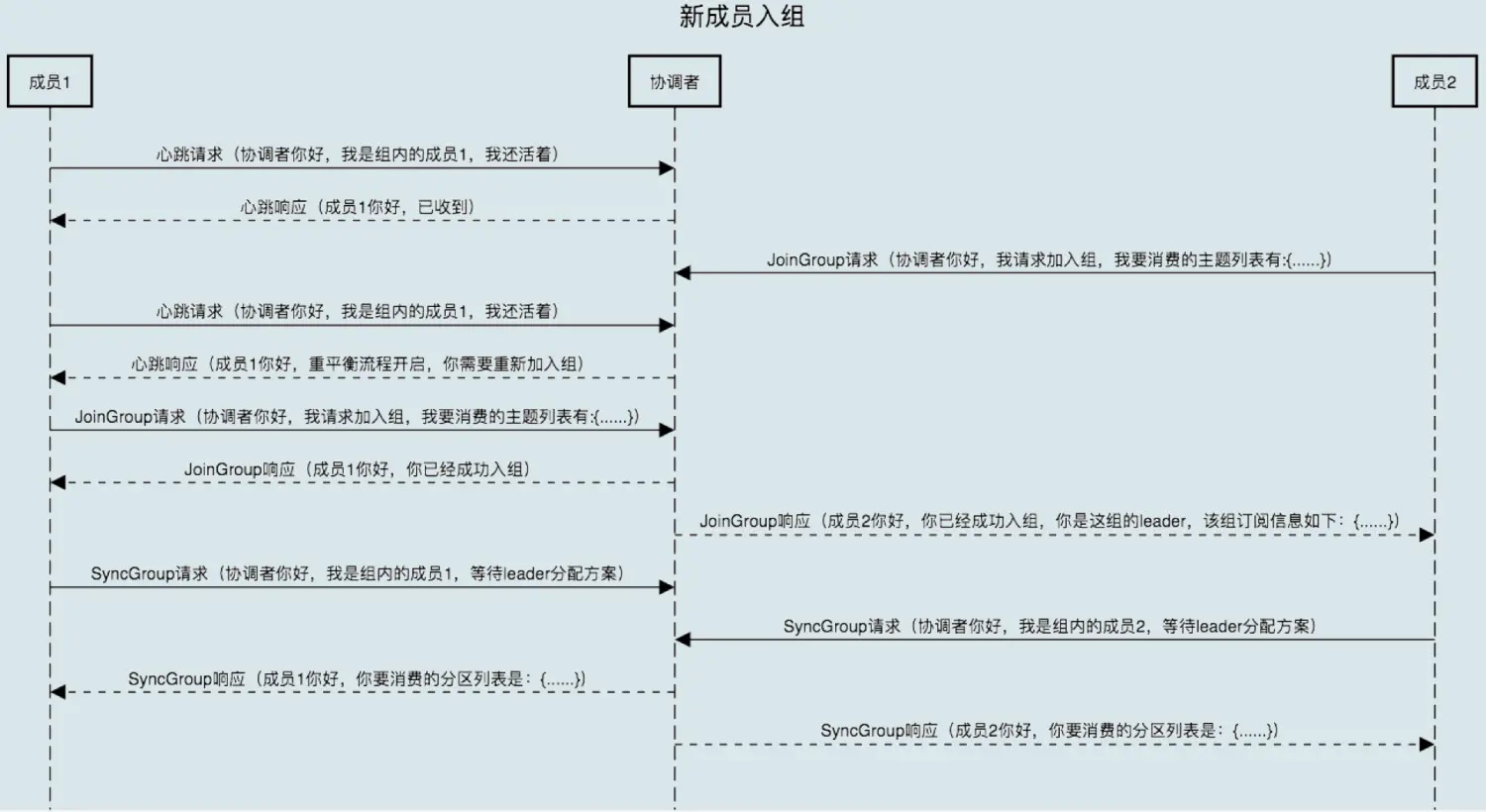
新成员加入
- 消费者组处于 Stable 之后有新成员加入
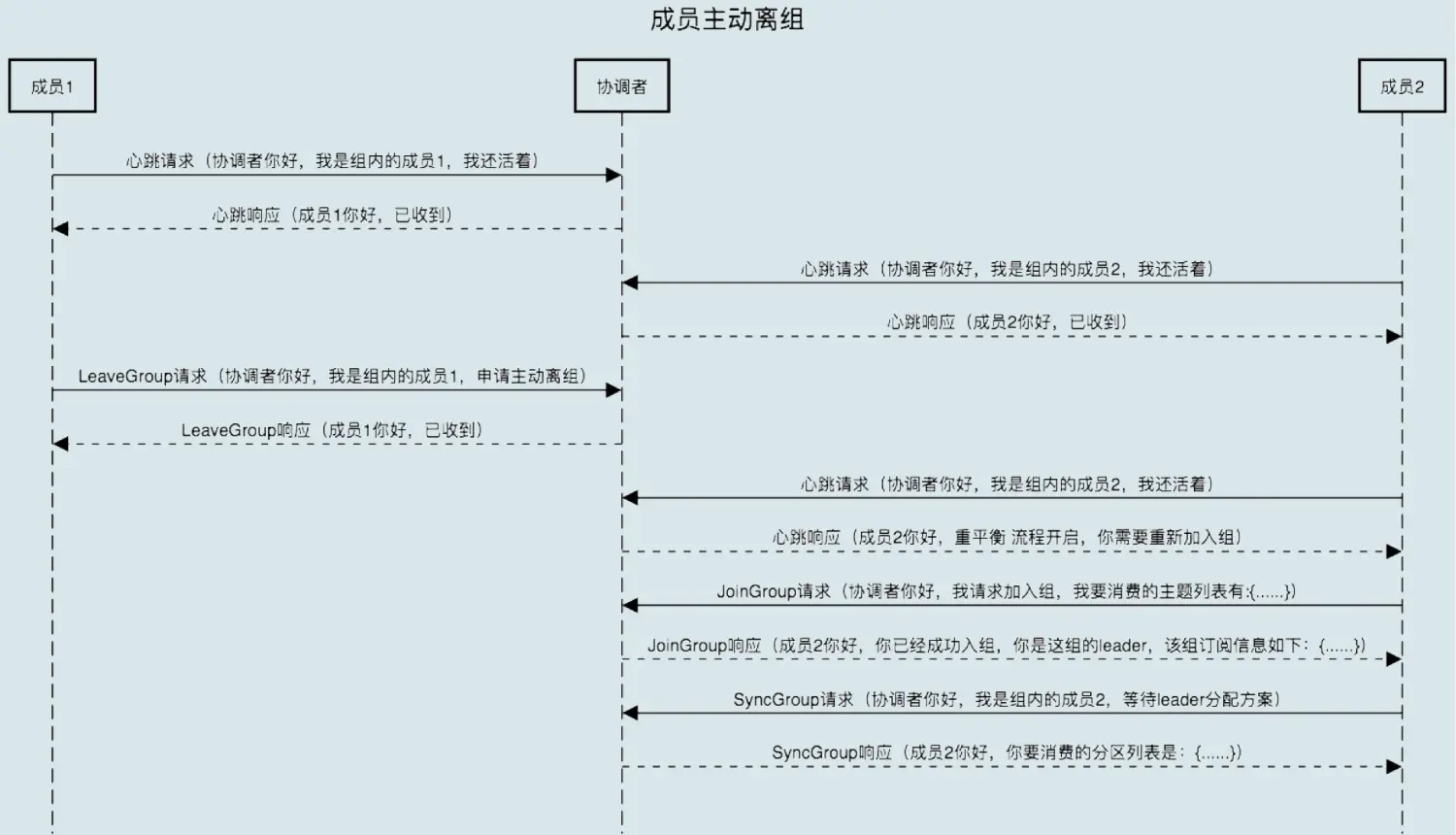
组成员主动离开
- 主动离开:Consumer Instance 通过调用 close() 方法通知协调者退出
- 该场景涉及第三个请求:LeaveGroup 请求
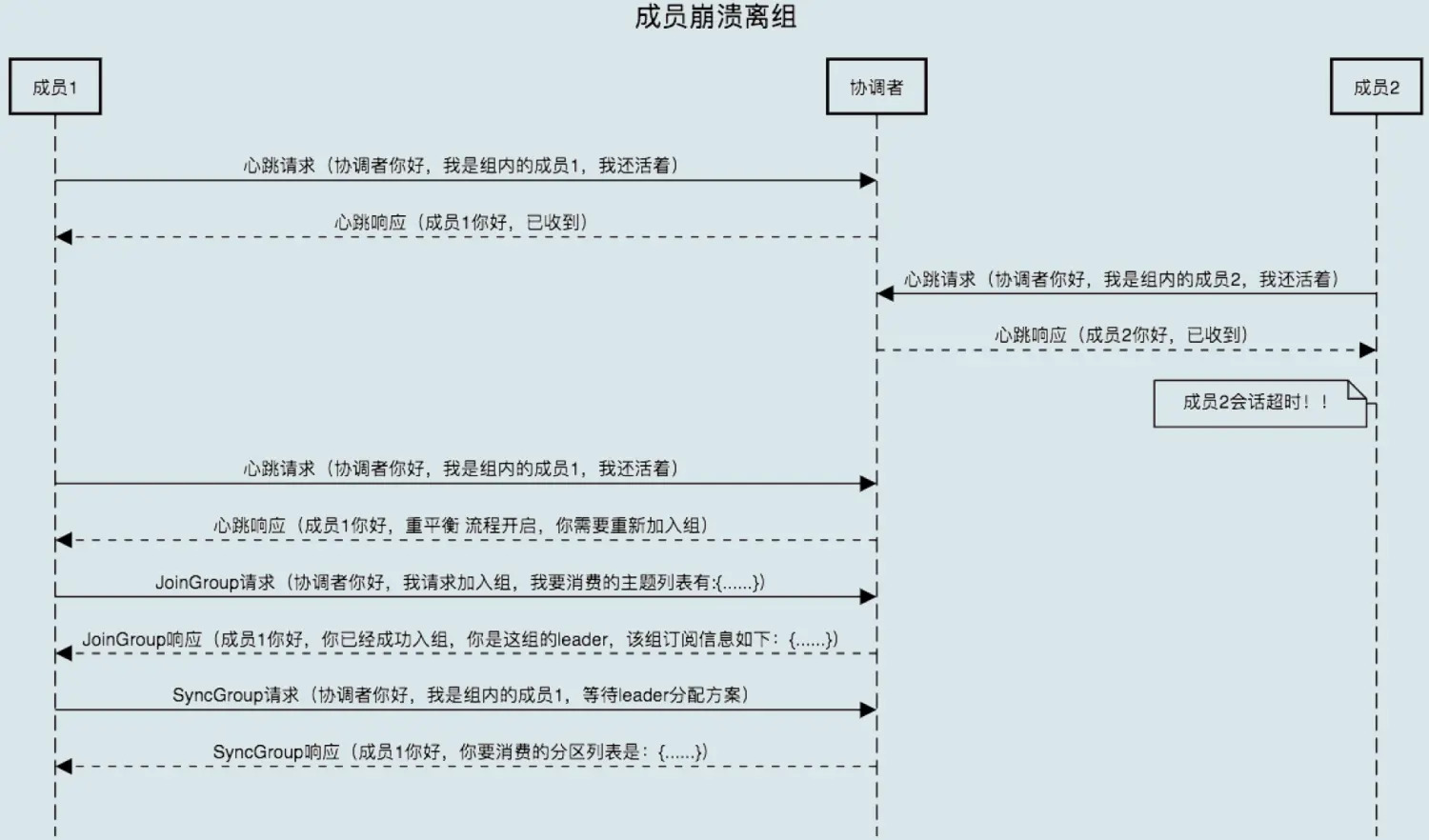
组成员崩溃离开
- 协调者需要等待一段时间才能感知
- 这个时间段由 Consumer 端参数 sessionn.timeout.ms 控制
- Kafka 不会超过上述参数时间感知崩溃
- 处理流程相同
Rebalance 时组成员提交 offset
- Rebalance 开启时,协调者会给予成员一段缓冲时间,要求每个成员在这段时间内快速上报自己的 offset。
- 再开启正常的 JoinGroup/SyncGroup 请求
