


问题背景
在包含约三千个列的数据文件中,有30%的 CPU 资源用于数据解析。如果加速产品选择缓存所有数据对象,将需要约20GB的内存空间来存储1亿个对象。这个问题严重阻碍了更大规模使用Presto系统。
架构实现
首先,看看Presto的访问远程文件后都干了啥。Presto的工作节点从远程存储获取数据后,通常会经历以下流程:打开文件、解析文件、读取Footer 、读取数据块。
目前,Presto仅支持在工作节点上缓存数据块。那针对常见的列式存储格式,如ORC和Parquet。是否可以利用行组信息(ORC 的stripes,Parquet 的row groups),将数据拆分并行处理,取得效果呢?
答案是肯定的。
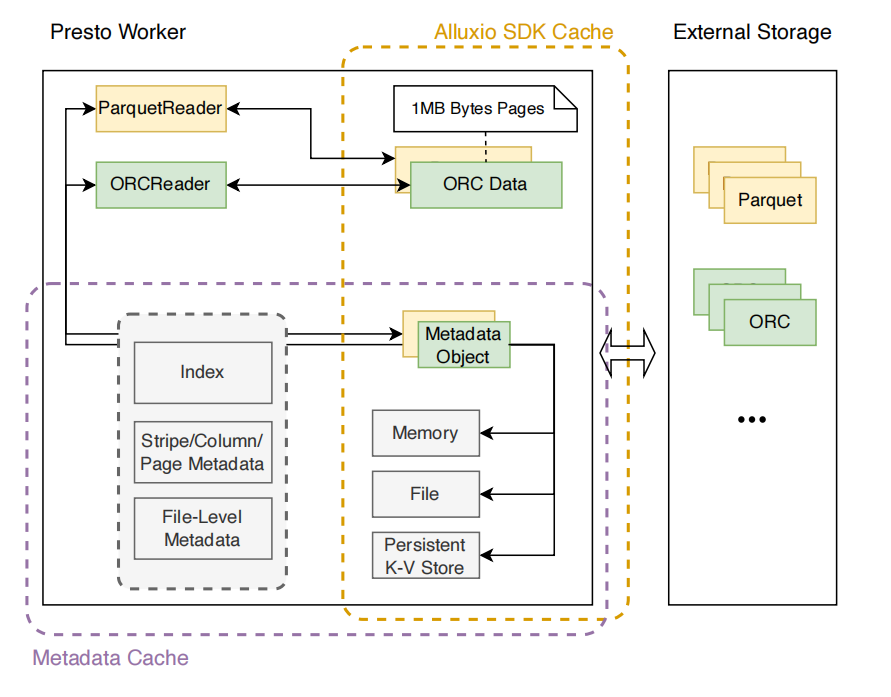
针对每个文件格式,presto都有一个Reader实现。如ParquetReader用于读取和解析Parquet的原始文件数据。这些原始数据缓存在Alluxio中。如果数据被压缩过,Reader还需解压缩后,再提取元数据信息和数据。具体实践中,支持两种缓存方法:缓存未压缩的元数据字节和缓存反序列化的元数据对象。缓存的元数据信息包含了strips、columns、pages、indexes和文件层的元数据。我们的实现中也支持多级缓存:内存、文件、持久KV层。
缓存未压缩的元数据字节
先看下图中的Write Path。当 Presto工作节点读取到列格式存储的文件时,它会解析和解压文件,以获取index, stripe、column、page元数据,以及文件的元数据。然后,工作节点将提取的元数据字节写入键值存储中。
再看Read Path。当收到 SQL 查询并且命中缓存的对象时,Presto Scanner将从键值存储中加载字节,并将其反序列化为内存中的元数据对象。然后,Presto 工作节点运行扫描和过滤操作,以完成预定的执行计划。
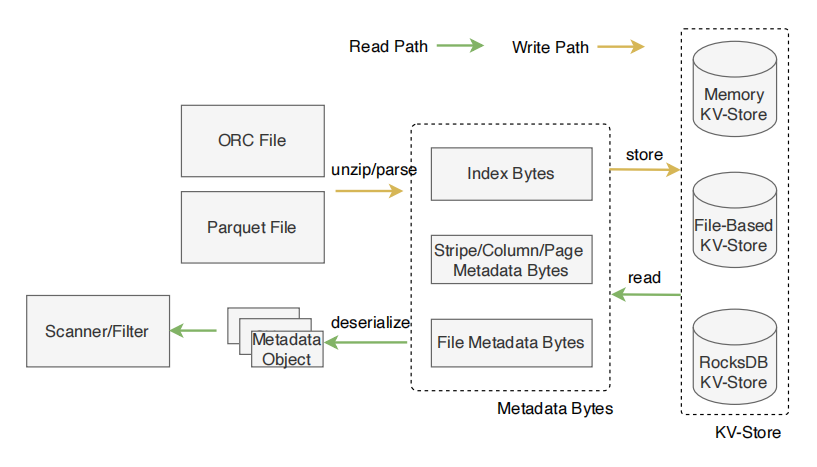
以ORC格式为例:
在ORC格式中多个行组成一个Stripe。每个Stripe包含Index、Data、Stripe Footer。Index存储这个Strip的统计值,包含最大值和最小值以及每列的行位置。Stripe Footer存储了流(列块)的目录信息。每个ORC文件有一个File Footer。这个File Footer记录了每个文件元数据,包括Stripe列表和每个Strip的行数量。Presto ORC Reader解压缩orc文件,提取元数据(Index、Data、Stripe Footer、File Footer)存储到KV存储中。在sql执行过程中,当缓存的元数据二进制被读取时,将从KV存储中读取,并反序列化为Metadata Object。上层通过调用getFooter、getIndex、getStripeFooter来处理数据。
缓存未压缩的Metadata Object
上面的步骤中想要拿到Metadata Object都得经过反序列化。如果这个缓存元数据二进制被多次读取,那每次都需要经过反序列化。这里可进一步改进,将反序列化的Metadata Object缓存起来。改进后的架构如下:
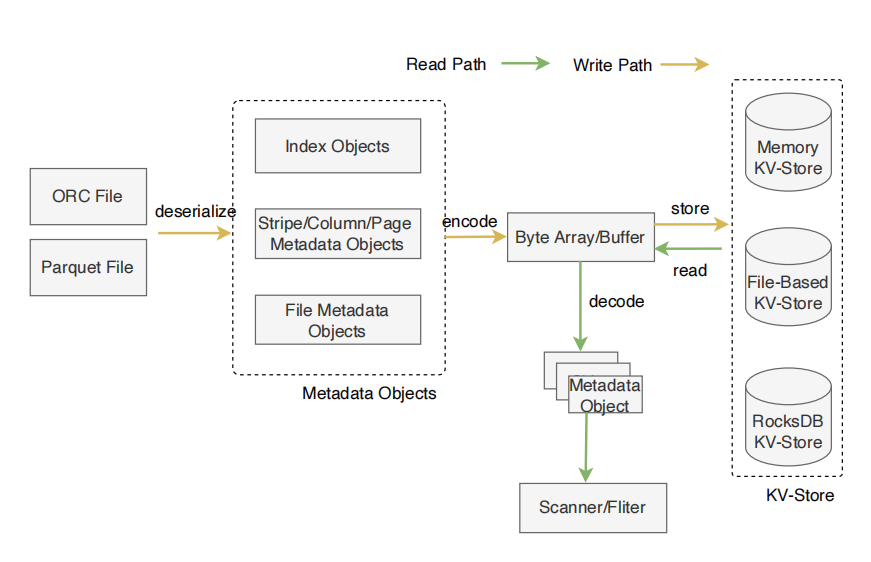
上图中将Metadata Object编码为Byte Buffer,我们使用了FlatBuffers方法。FlatBuffer是零拷贝的,并且编解码效率特别高。
性能评估
我们以TPC-DS的10条sql来评估使用上面两个方法后效果到底如何。测试中,我们使用了1个coordinator node和5个worker node。hdfs使用5个data node。
先看一下写的性能(越低越好)。
执行下面的sql时,我们清空缓存,全都是冷查询。
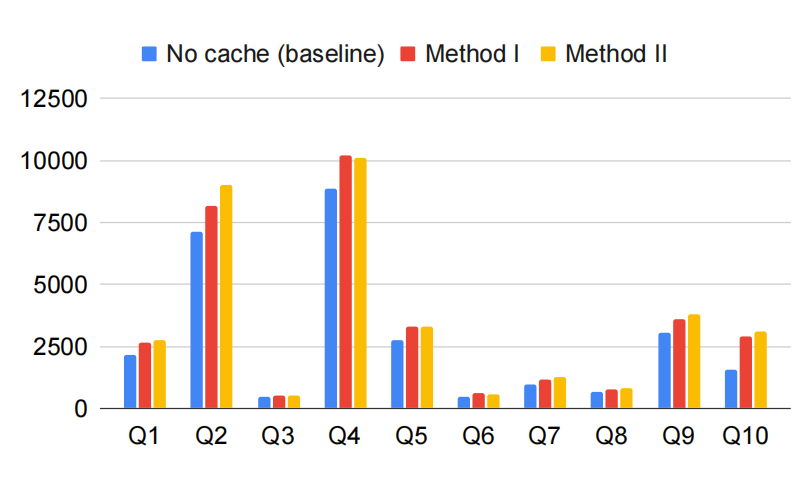
如上图所示:方法一相比基线高10%到20%左右,方法二相比基线高10%到30%之间。方法二由于有额外的编码工作,因此比方法一 CPU占用高。除此之外,我们看到针对Q10的查询,性能差距更大。这是因为Q10是6个表在计算,产生非常多的元数据写,导致性能变差。
再看一下读的性能(越低越好)。

当元数据被缓存后,上面的sql查询将触发缓存读操作。方法一相比基线降低10%到20%左右,方法二相比基线降低20%到40%之间。除此之外,我们看到Q9的查询,优化反而变差了,。分析sql后,我们注意到该查询包含超过10个Join操作,因此缓存占用了大量的内存,这进而导致在 Presto 任务调度上消耗更多的 CPU 时间。
从实验结论看,我们的优化能明显降低查询过程中,发生文件解析的CPU资源占用问题。
