


概要
基于Llama 2的架构和tokenizer构建的一个1.1B的语言模型,使用了大约1trillion tokens,3 epochs。
作者声称虽然尺寸很小,但在一系列下游任务上表现出色。
核心内容
方法
预训练
混合了自然语言和代码数据
-
自然语言数据:SlimPajama
-
SlimPajama:一个大型开源预料,主要用于训练基于RedPajama得到语言模型,原始的RedPajama是一个开源的研究如何复现Llama预训练数据的预料
-
SlimPajama包含超过1.2 trillion tokens
-
SlimPajama从RedPajama经过清洗和去重得到
-
-
代码数据:Starcoderdata
-
Starcoderdata,这个数据集用于训练StarCoder,一个大型开源代码语言模型
-
大约由250 billion tokens组成,包含86种编程语言,除了代码,还包含GitHub的issues和涉及自然语言的文本-代码对
-
为了避免重复,移除了SlimPajama的GitHub子集,并仅仅从Startcoderdata采样
-
合并完这两个数据集后,大约有950 billion tokens来做预训练,训练了3个epoch,Scaling Data-Constrained Language Models观测到,相比使用唯一数据(?),重复训练4个epoch出现的性能损失最小。
使用了Llama的tokenizer处理这些数据
自然语言和代码的比例大约为7:3
模型架构
使用了Llama 2的模型架构,参数如下:
其他使用到的技术:
-
Positional Embedding:RoPE
-
RMSNorm
-
SwiGLU
-
Grouped-query Attention:有32个query attention头和4组key-value头
加速优化
这部分涉及的技术:
-
Fullly Sharded Data Parallel:用的是数据并行的方式进行的训练
-
Flash Attention
-
-
性能分析和其他模型对比:
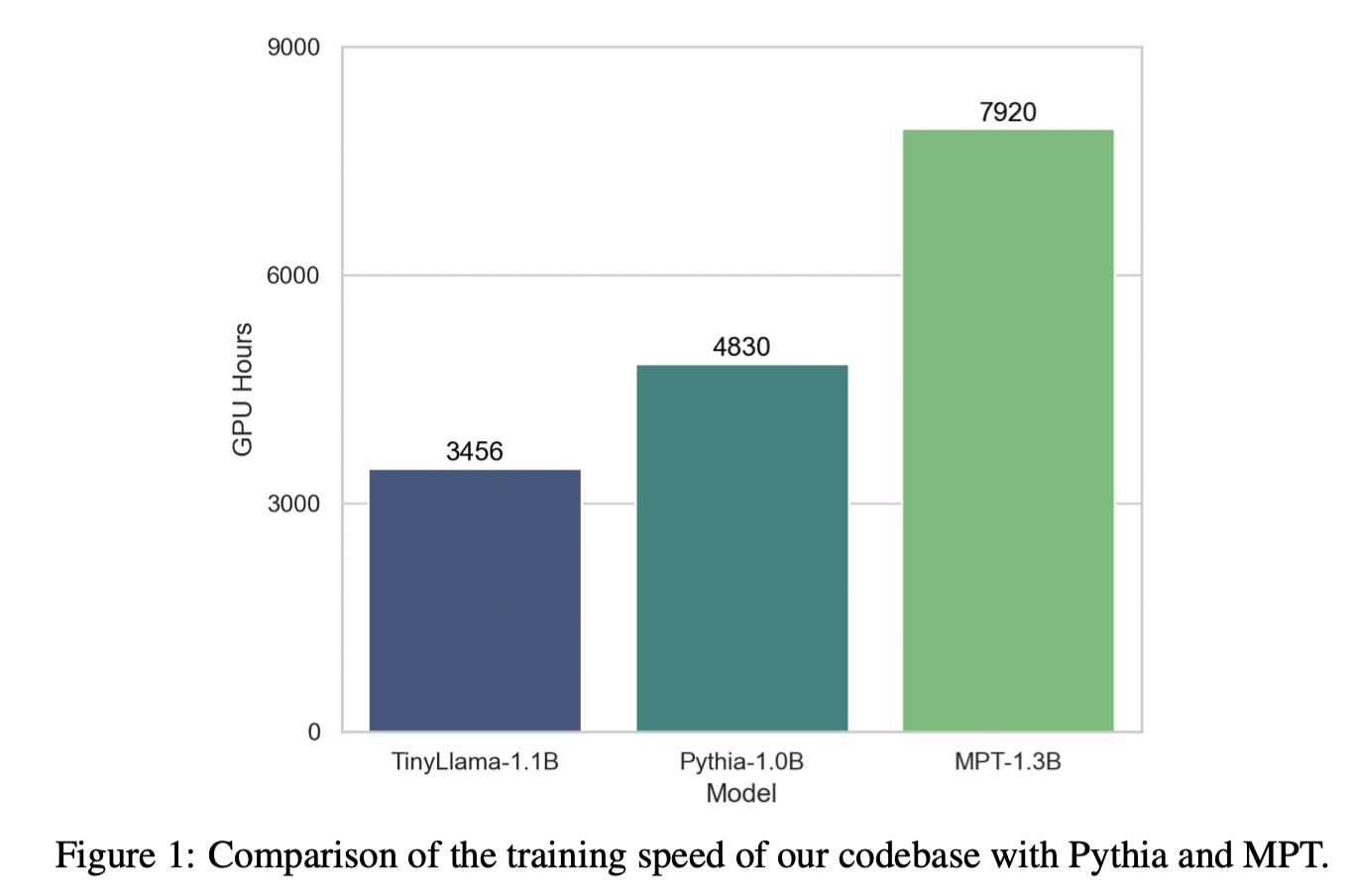
论文所提模型能够在A100-40G GPU上以24,000 tokens每秒每GPU的吞吐进行训练,与Pythia-1.0B和MPT-1.3B相比,展现了优越的训练速度。
TinyLlama-1.1B模型在300B tokens上仅需要3,456 A100 GPU时,Pythia需要4830,MPT需要7920
这个模型数据量:参数量比例为272: 1,超过200: 1,甚至超过下图中所示例的最大比例,按照Chinchalla的研究,这个比例数据严重偏多了;按照Chinchilla的研究,数据量: 模型参数量的最佳比例是20: 1 作者使用的是40G的A100,按照3456 GPU时推算,8卡需要预训练3456/8/24=18天,8卡是从代码里面看到的
从运算速度推算数据量:24000*8*3600*24*18=298,598,400,000,与作者所说的300B数据量接近,但这样相当于只训练了1个epoch,这点与论文中不符

结果
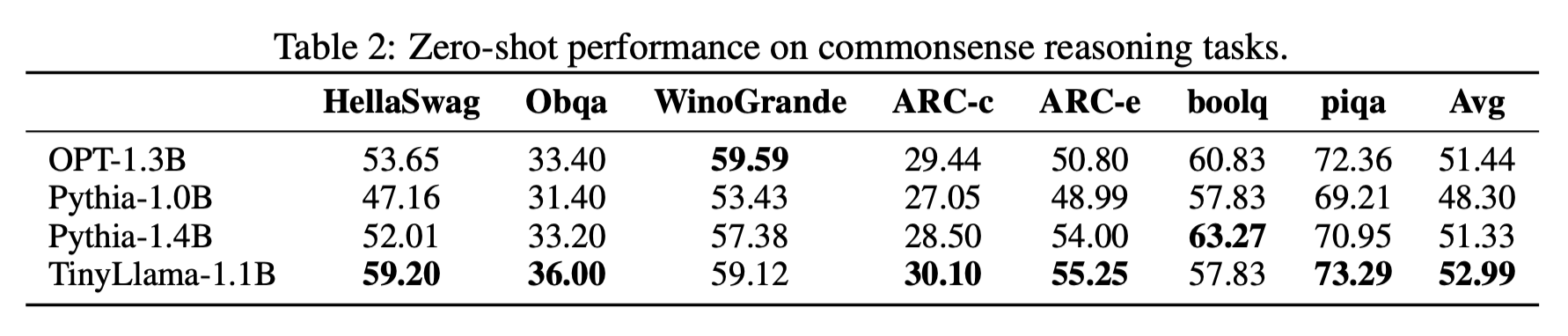
常识推理任务
训练过程中的性能进化记录
从图中可以看出,作者所监控的这些指标,随着训练的进行,指标都是在提升的

问题解决评估
-
MMLU:评估模型的世界知识和各种主题下的问题解决能力。使用5-shot方式评估
-
BIG-Bench Hard(BBH):包含23项挑战,主要评估模型的复杂指令追随能力。使用3-shot方式评估
-
Discrete Reasoning Over Paragraphs(DROP):阅读理解任务,主要评估模型的数学推理能力。使用3-shot的方式评估
-
HumanEval:评估模型的编程能力,使用zero-shot方式

