


1、任务型多轮对话系统概述
任务型多轮对话系统是人工智能领域的一个重要分支,主要是通过自然语言处理技术,实现人机之间的有效沟通。这类系统广泛应用于客户服务、智能助手、智能家居控制等多个场景。
任务型多轮对话系统是指能够理解用户意图,通过多轮交互完成任务的对话系统。与简单的问答系统不同,任务型系统需要处理复杂的对话流程,包括但不限于意图识别、状态跟踪、对话管理、自然语言生成等。
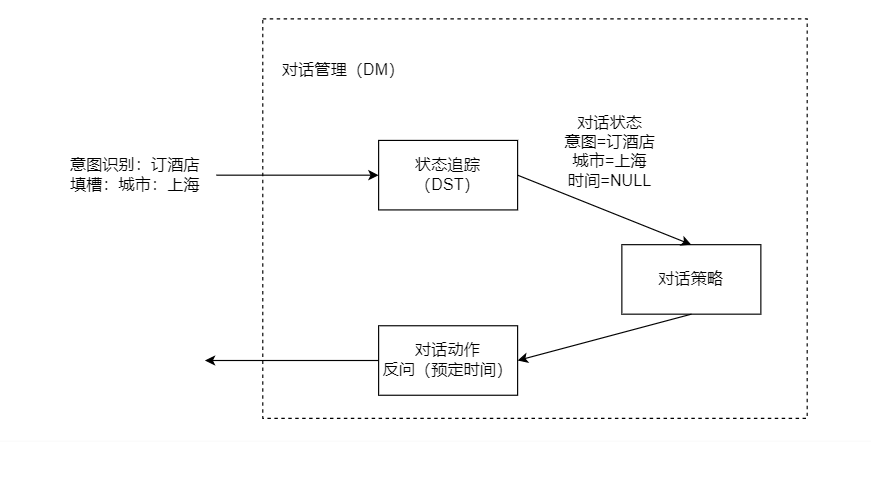
图1 任务式对话
2、关键技术
2.1 意图识别(Intent Recognition)
意图识别是任务型多轮对话系统中最基础也是最关键的步骤之一。它涉及到从用户输入的自然语言文本中解析出用户的意图,即用户想要系统执行的具体任务或回答的具体问题。这一过程对于后续的对话管理和信息处理至关重要,因为它决定了系统如何响应用户的需求。
1)意图识别的复杂性
用户输入的自然语言往往包含多种意图,有时这些意图可能相互交织,甚至含糊不清。因此,意图识别不仅仅是简单的关键词匹配,它需要深入理解语言的语义和上下文。例如,用户可能说:“我需要订一张从北京到上海的机票”,这里的意图是“订票”,但同时包含了出发地、目的地、出发时间等具体信息。
2)意图识别的实现方式,意图识别通常通过以下几种方式实现:
(1) 基于规则的方法:通过预定义的规则和模式来识别意图,这种方法简单明了,但难以应对复杂的语言变化。
(2)机器学习方法:使用分类算法,如决策树、随机森林等,根据训练数据学习意图的模式。
(3)深度学习方法:利用神经网络,特别是Transformer架构,例如BERT、GPT等,来捕捉语言的深层特征。
2.2 实体抽取(Entity Extraction)
在理解用户意图的同时,系统还需要识别对话中的关键信息进行语义槽填写,如时间、地点、人物等。这通常通过命名实体识别(NER)技术来实现。这些信息对于理解用户的意图、执行相应的任务或提供准确的回答至关重要。实体抽取的过程通常被称为语义槽填充(Semantic Slot Filling),因为它涉及到在对话的上下文中填充与用户意图相关的具体信息。
在实现命名实体识别(NER)任务时,常用的技术方法主要包括以下几种:
(1) 基于规则的方法:早期的NER系统常依赖于手工编写的规则,这些规则基于词汇特征、词性、上下文模式等来匹配和识别命名实体。虽然这种方法在特定领域内可能有效,但难以泛化到新数据和新类型的实体上。
(2) 统计模型:例如CRF模型,考虑了整个输入序列的信息,能更好地利用上下文特征进行标注决策。
(3) 深度学习模型:
BERT:BERT通过深度双向上下文预训练,为NER任务提供了强大的语境理解能力。通过微调BERT模型,可以在各种NER数据集上达到当时最佳性能。
Span-based Models:不同于传统的序列标注,这类模型直接预测实体的起始和结束位置,或通过全局指针网络(Global Pointer)等机制抽取实体跨度,代表性模型如BERT+MRC(阅读理解)方法,适用于解决实体嵌套和重叠问题。
2.3 对话状态跟踪(Dialogue State Tracking)
对话状态跟踪(Dialogue State Tracking,简称DST)是任务型多轮对话系统中的一个核心组件,它负责在对话过程中实时监控和更新对话的状态。对话状态通常包括用户的意图、已识别的实体、对话历史等信息。通过精确的状态跟踪,系统能够更好地理解用户的连续意图,提供连贯和准确的服务。
(1) 维持对话连贯性:在多轮对话中,系统需要记住之前的交互内容,以便在后续的对话中提供一致的回应。
(2) 提高响应准确性:通过跟踪对话状态,系统可以更准确地理解用户当前的需求和意图,从而提供更精确的服务。
(3) 优化用户体验:良好的状态跟踪能够减少用户的重复表述,提高用户满意度。
(4) 支持复杂任务:对于需要多步骤完成的任务,状态跟踪能够帮助系统管理任务的执行流程。
2. 4 对话管理(Dialogue Management)
对话管理是对话系统的核心,负责协调各个组件的工作,控制对话流程。它通常包括一个规则引擎或一个基于机器学习的决策系统,用于决定下一步的对话策略。
它的主要职责是确保用户与系统的交互流畅、自然且高效,这涉及到了解用户意图、维护对话上下文、选择合适的系统响应以及适时引导对话方向等多方面功能的整合与优化。具体来说,对话管理不仅需要处理用户的即时输入,理解其背后的意图和情感,还要结合之前对话的历史信息,维持一个连贯的对话状态。这一过程高度依赖于一个强大而灵活的规则引擎,该引擎内置了一系列精心设计的逻辑规则,能够根据预定义的场景和用户行为模式,快速做出响应决策。例如,当检测到用户提出一个问题时,规则引擎会指引系统寻找最相关的答案或采取进一步的询问来澄清需求。
2.5 自然语言生成(Natural Language Generation)
为了生成自然、流畅的回复,系统需要使用自然语言生成技术。它是人工智能领域的一个关键技术,它致力于创造能够自动生成人类可读文本的系统。这项技术不仅仅局限于简单的文本构造,而是涵盖了从结构化数据到非结构化语言的转换过程,使机器能够以自然、连贯的方式表达复杂的思想和信息。具体来说,NLG的应用可分为几个层次:
模板生成:这是最基础的形式,通过预定义的模板填充变量来生成文本。例如,天气预报应用可能有一个模板“今天{city}的天气是{weather},气温{temp}度”,只需将具体的地点、天气状况和温度填入即可生成消息。
基于规则的生成:在此方法中,系统遵循一系列明确的语法规则和逻辑来构造句子。虽然比模板生成更灵活,但维护这些规则集可能会变得相当复杂且难以覆盖所有语言情境。
基于深度学习的生成方法:近年来,随着深度学习技术的发展,尤其是Transformer等模型的出现,NLG达到了新的高度。这些模型通过学习大量文本数据,能够自动生成多样化的、上下文相关的回复,如ChatGPT和GPT系列模型。它们在对话系统、新闻摘要、故事创作等多个领域展现出了惊人的创造力和适应性。
2.6 知识库与外部资源
对话系统常常需要访问知识库或外部资源来提供准确的信息或执行特定的任务。有效的知识库管理和资源整合对于提升系统性能至关重要。
2.7 大模型在任务新对话中的作用
目前研究机构、工业界也开始研究大模型在任务型对话系统中的应用,提升对话系统的智能化水平和用户体验。以下是大模型在任务型对话系统中应用的几个关键方面:
自然语言理解(NLU):大模型能够更准确地理解用户输入的意图和上下文,通过其强大的语义理解能力,精确识别用户需求,比如订单查询、服务预约或信息检索等具体任务。
对话管理(DM):虽然传统上对话管理更多依赖于规则或基于状态机的设计,大模型可以辅助或直接参与对话流程的决策,动态生成对话策略,使对话更加流畅和自然,甚至能处理复杂的多轮对话场景。
自然语言生成(NLG):大模型擅长生成连贯、自然且贴近人类语言习惯的回复,不仅限于固定模板的回答,还能根据上下文创造多样化的、个性化的回复内容,增强对话的真实感和互动性以及人文关怀。
结论
任务型多轮对话系统是人工智能领域的一个重要研究方向,其关键技术包括意图识别、实体抽取、对话状态跟踪、对话管理、自然语言生成等。随着技术的进步,未来的对话系统将更加智能、自然,同时大模型等新技术也会不断推动任务式对话系统有更好的体验。
