


在当前计算机发展趋势下,单台服务器的存储能力、计算性能越来越强悍。目前在datanode节点,可支持挂载更多的磁盘,为了避免出现慢磁盘而影响整个datanode服务的性能,考虑对每个磁盘的IO事件监测统计,发现有慢磁盘时就在datanode选盘的过程中,排除这个慢磁盘,以此提升服务的稳定性。下图是磁盘监测统计、慢磁盘过滤的架构:

DataNode 磁盘的IO操作被统计收集到DataNodeVolumeMetrics中,DataNodeDiskMetrics会启动一个周期性线程来获取每个IO类型的耗时均值,通过探测异常的方法获取到超过阈值的磁盘,在异常磁盘的列表中再选出TOP N 放入slowDiskToExclude中,后续执行chooseVolume时,就会过滤slowDiskToExclude中磁盘。
下面讲解下write操作的统计:

new 一个ProfilingFileIoEvents: isEnabled 由dfs.datanode.fileio.profiling.sampling.percentage 决定,>0 就启用IoEvent收集
sampleRangerMax:决定了抽样概率 ---- 随机值 < (int) ((double) fileIOSamplingPercentage / 100 * Integer.MAX_VALUE)
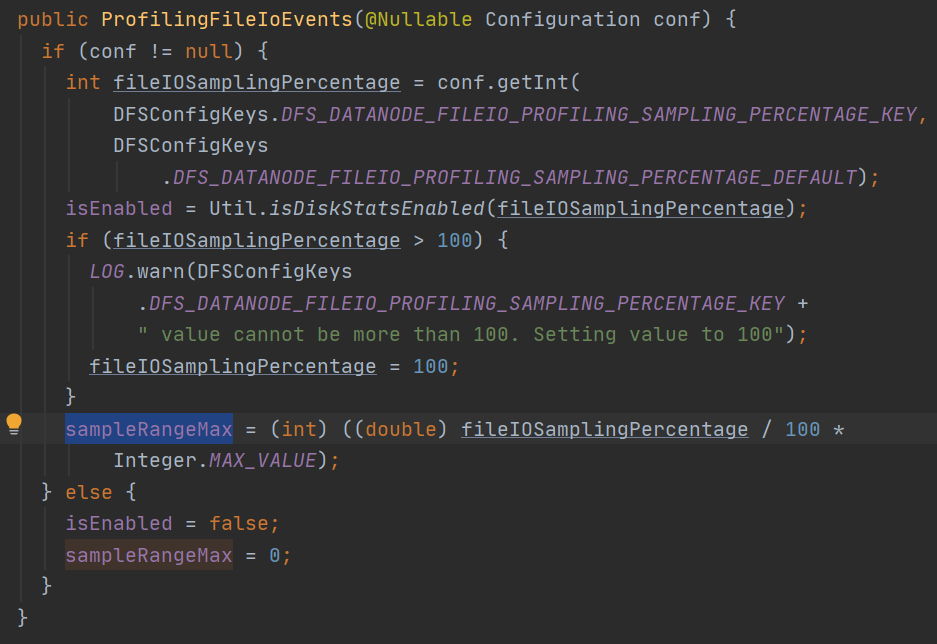
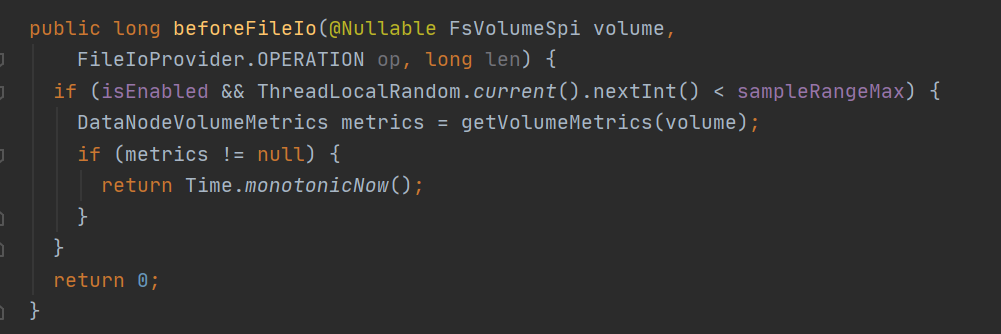
beforeFileIo: 这里注意随机值 ThreadLocalRandom.current().nextInt() 包含了负数,应该替换为(HDFS-17471) ThreadLocalRandom.current().nextInt(Integer.MAX_VALUE)
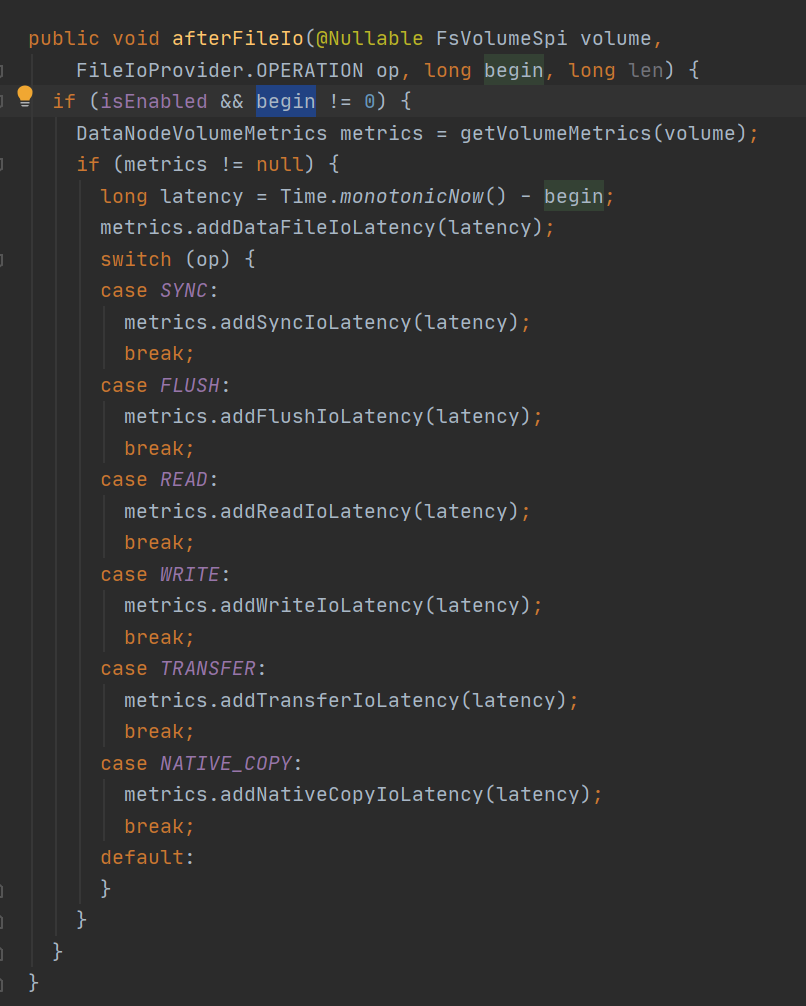
afterFileIo: 根据OP类型存入指标数据
这里切入下DataNodeVolumeMetrics.addWriteIoLatency
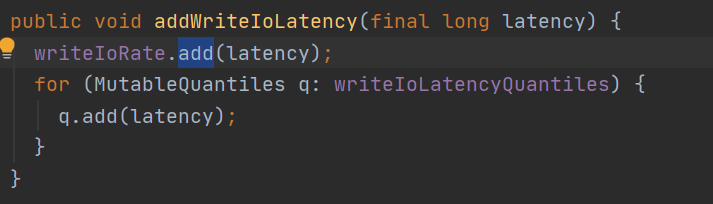
向writeIoRate<MutableRate> 添加延时数据 latency
MutableRate: 执行add添加数据
1、intervalStat<SampleStat> 执行add 加入数据
2、设置最小最大值
3、设置状态为已改变
DataNodeVolumeMetrics.getWriteIoMean 就是获取intervalStat的均值:

下面是各种IO事件对应的OP类型:
| WRITE:写到缓冲区 FLUSH:刷写缓冲区数据到底层输出流 SYNC:缓冲区内容写入到基础流,底层文件系统也同步 READ:读取数据 TRANSFER:将数据从 FileChannel 传输到 SocketOutputStream NATIVE_COPY:拷贝block data、meta文件到其他位置 META:OPEN、EXISTS、LIST、DELETE、MOVE、MKDIRS、FADVISE |
