


一、 目的和意义
1. 加深研发工程师对系统的理解,验证系统架构的容错能力
2. 提高运维工程师对故障的应急处理能力,实现故障告警、止损、定位、恢复的高效应对
3. 弥补测试工程师在传统测试方法下的空白,主动探索系统隐患问题
4. 提升产品经理了解在突发状况下产品的表现,提升产品的处理能力
二、 方法论
2.1 建立假设:
假设的建立是实验进行的基础,一切实验都是对假设进行证明或证伪。在混沌工程实验的场景下,假设通常反映的是系统可能存在的稳定性缺陷。这些假设的缺陷可以依据用户反馈、测试记录和对系统架构的理解来确立。假设的缺陷制定完成后,应逐个分析其出现概率、影响范围和严重程度来确立混沌工程实验的优先级。曾出现过并造成经济损失的假设缺陷通常是实验优先级最高的,这些有记录的故障很有可能会再次出现,而且也可能会在结构相似的链路上引发同类型的故障。
2.2 实验场景设计:
如需观测注入扰动对系统的影响,我们需要被测系统处于一个业务场景中正常工作的状态。实验场景的设计要避免过于简单,需包含多样的任务以确保足够的覆盖范围。如条件允许,可考虑使用生产环境作为实验用场景。为了降低生产环境实验的风险,通常的预防策略是采用金丝雀(Canary)版本(发布给少量用户的试用版本)或采用流量分支作为混沌工程实验场景,以确保最坏的情况下只有一小部分用户会受到影响。如在模拟或测试环境中进行实验,实验的场景需尽量接近实际业务中的真实场景,覆盖的用户操作应尽量全面。较为有效的方法是录制生产环境中的各种变量,如流量、服务请求频率等,然后在测试中重放,或用生产环境的模拟数据进行实验场景搭建。
2.3 系统评估指标设计:
实验设计时应确立实验过程中需收集的指标,以便评估注入扰动对系统造成的影响。这些指标可根据具体的实验对象、业务场景以及可用的监控手段确立,并尽量全面,需要在系统功能或性能受损时产生明显的变化。指标确立和收集时推荐采用的做法是:
a.关注指标平均值的同时对最优值和最差值进行收集。
b. 关注最终指标的同时对子任务指标或支撑指标进行收集。
c. 将一部分指标定为止损指标,当止损指标超出一定阈值则需终止实验,避免造成较大的损失。
三、 实验工具
目前主流的制造故障的开源工具主要有2个,阿里的Chaosblade工具和PingCAP的Chaos Mesh工具,ChaosMesh 工具主要解决的是容器化部署服务的故障注入,而Chaosblade能够注入的故障场景不仅限于容器化部署场景。
下面主要介绍Chaosblade工具的使用。
1.应用场景覆盖:
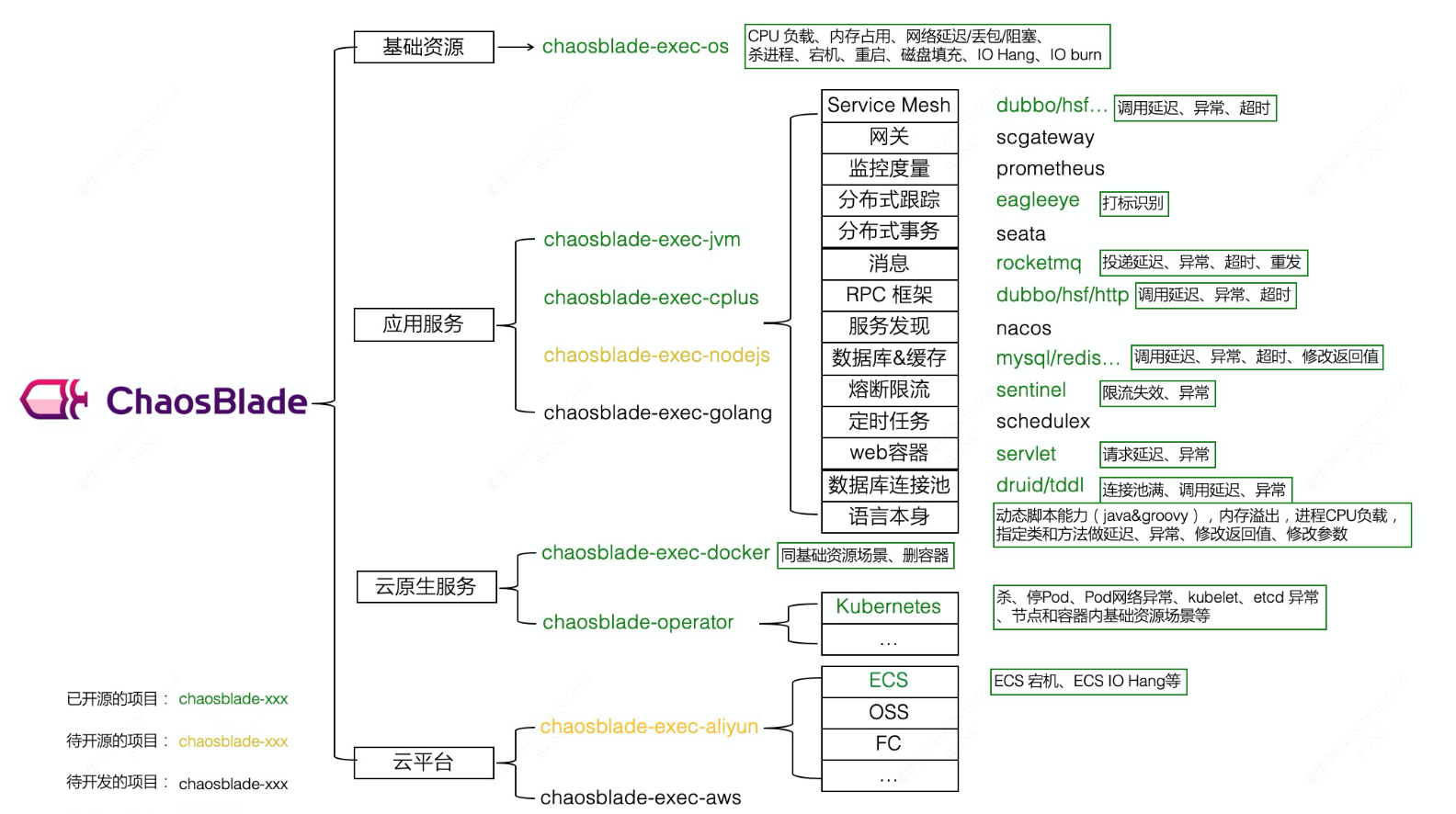
2. 工具使用
(1)在官网下载安装包,选择最新的1.7.3.tar.gz 解压即可
(2)如果需要针对k8s 部署的服务进行故障注入,需要安装chaosblade-operator (在官网下载安装包)
部署注意事项:需要提前在机器上安装helm工具,k8s中部署安装的空间可以自定义空间
kubectl create ns chaosblade
helm install chaosblade-operator --namespace chaosblade chaosblade-operator-1.7.3.tgz(3)随机pod不可用,使用参数--evict-count 1
blade create k8s pod-pod fail --labels 'app.kubernetes.io/name=demo' --evict-count 1 --kubeconfig /root/.kube/config --namespace back-end(4) 制造故障时务必记得加上故障生效时间:--timeout 300
(5) 其余命令可参考chaosblade操作手册
四、 实施步骤
1. 确定故障场景:可以从基础资源、云原生服务、业务服务几个角度设计项管的故障场景。
通常业务对第三方服务依赖处理能力较弱,或者被忽视,可以重点关注第三方服务依赖。
2. 环境选择:初次进行故障注入环境选择的原则是 测试=》预发环境=》灰度环境=》生产环境
3. 如果是在非生产环境进行故障注入演练,需要准备如下2类脚本:故障注入脚本及编排,业务服务自动化脚本。
4. 确定监控指标是否覆盖全面,报警机制是否完善
5. 确定响应人员是否到位,故障是否存在处理手册和相关预案。
