


数据集成面临的挑战
在数字化时代,大数据已成为企业和组织的重要资产。数据集成作为大数据生态系统中的关键一环,负责将分散在不同数据源的数据进行整合、清洗、转换和加载,以支持决策制定、业务流程优化和创新。然而,随着数据量的爆炸性增长和数据类型的多样化,数据集成面临着前所未有的挑战。
1. 数据源多样
数据可能来自不同的系统和平台,如关系型数据库、非关系型数据库、文件系统、消息队列等,不同数据源可能具有不同的数据结构和格式,增加了数据整合的复杂性。比如 Oracle有很多版本,而且每个版本之间是不兼容的,每个版本你都要去考虑怎么去适配,这个工作量是很大的。
2. 数据质量问题
数据质量是数据集成的核心问题之一。源数据可能存在缺失值、错误数据、数据重复等问题,这些问题会影响到数据分析和决策的准确性。
3. 数据的隐私和安全
在数据集成过程中,需要保护数据的隐私和安全。数据源可能涉及到敏感信息,如个人身份信息、电话、财务数据等,必须确保数据在传输过程中的安全性。
4. 数据处理能力
随着数据来源的多样化,数据量呈现爆炸式增长,这对数据存储和处理能力提出了更高要求。现有的数据同步工具往往需要大量的计算资源或JDBC连接资源来完成海量小表的实时同步,这加重了企业的负担。随着企业数据量越来越大,在处理大量数据时,对数据集成的实时性要求和稳定性挑战越来越大。
5. 数据一致性
如何保证数据的精确一致性,以及在出现问题时如何快速回滚?数据集成工具缺乏过程监控,可能会导致数据质量下降、集成效率低下以及问题难以及时解决。这些都是数据同步中面临的痛点问题。
应对策略
1. 采用支持多数据源和多格式的数据集成技术,以及灵活的数据处理框架,以适应不同的数据源和结构。
基于SeaTunnel支持100+种数据源,支持离线同步、实时同步、全增量同步等场景。
基于Flink CDC允许实时捕获数据库的变更数据(即插入、更新和删除操作),并将这些变更实时地传输到其他系统,如数据仓库、数据湖或消息队列,提供高吞吐量和低延迟的流处理能力。
设计合理的数据映射和转换规则,以适应不同数据源的整合需求。
2. 在数据集成之前,进行数据清洗和预处理,以提高数据质量。定期进行数据质量评估,建立数据质量监控机制。
在进行数据同步之前,对源数据进行清洗和预处理,包括删除去重复数据、纠正数据错误等数据质量管理措施。
支持数据质量校验,实现数据准确性一致性校验,包括字段非空、文件非空、数据量、字段数量、字段长度、字段格式、取值范围、重复校验、异常字符、编码格式、数据量级异常等。
3. 采用加密技术和访问控制机制,保护数据安全。
对敏感数据进行加密传输和存储,确保数据在传输过程中的安全性。
实施严格的访问控制机制,提供审计日志,以便及时发现和防范安全威胁。
4. 通过分布式架构、流处理框架和数据压缩技术,提高数据传输和处理效率。
采用分布式架构和并行处理技术,将数据分发到多个计算节点进行处理、多任务并行,从而提高系统的处理能力,支持横向扩展。
流处理框架:通过高吞吐量、低延迟的流处理框架,提供实时捕获和处理数据变更的能力。
采用数据压缩技术,减少数据的存储空间和传输带宽,提高数据的传输和处理效率。
5. 实现Exactly-Once(精确一次语义),保证数据一致性
在数据集成和流处理领域,实现Exactly-Once(精确一次语义)是确保数据一致性的关键特性。这意味着系统能够保证每个事件无论在任何情况下都只被处理一次,即使在发生故障的情况下也是如此。这对于维护数据的准确性和完整性至关重要。
同时实施端到端的监控和日志记录,以便在出现问题时能够追踪和定位。
数据集成技术方案介绍
SeaTunnel介绍
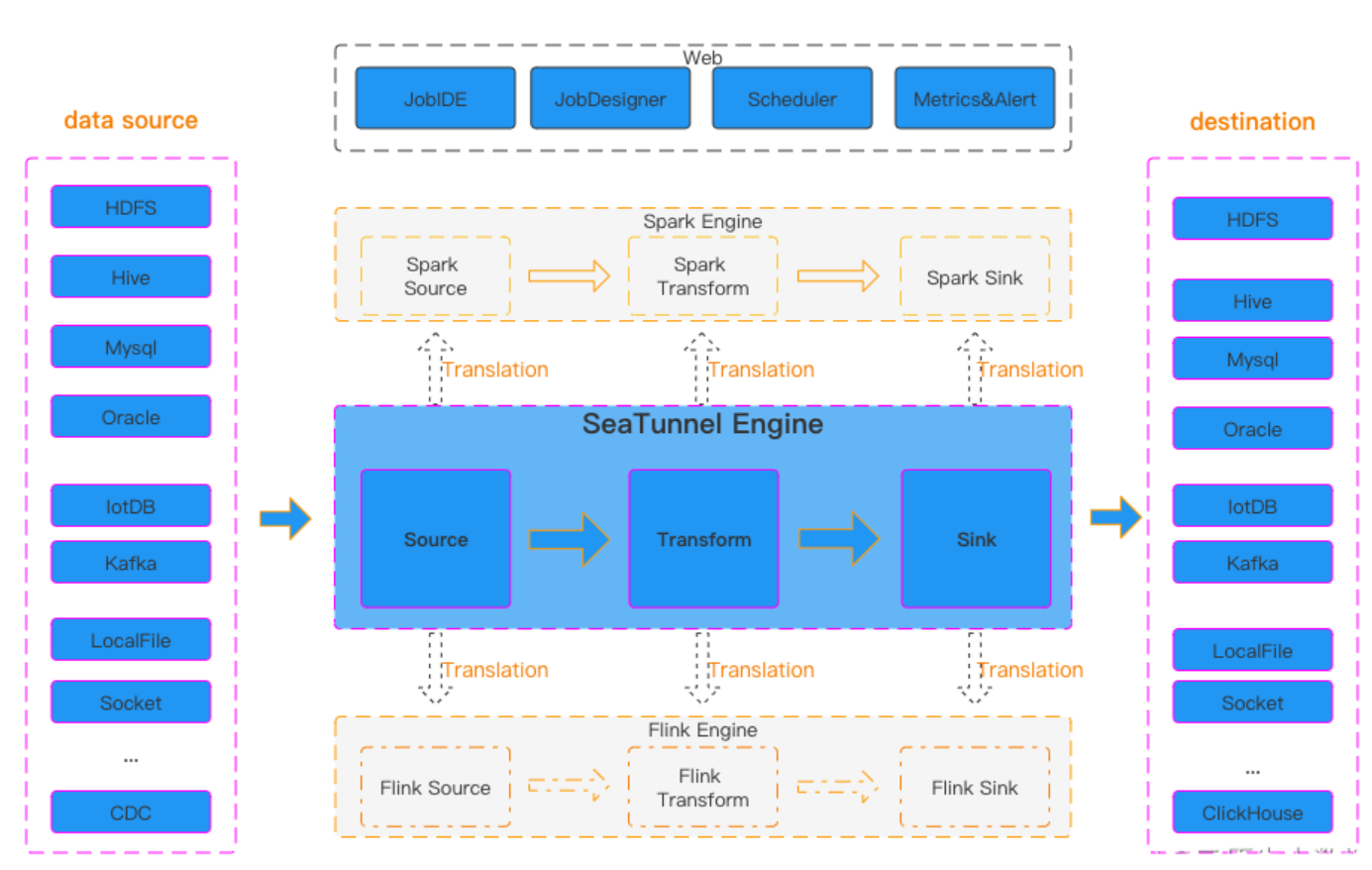
Apache SeaTunnel是一个分布式、高性能、易扩展、用于海量数据(离线 &实时)同步和转化的数据集成平台,每天可稳定高效地同步数百亿数据,并具有已用于生产近 100家公司。
丰富且可扩展的连接器
SeaTunnel提供了一个不依赖于特定执行引擎的连接器API,允许用户轻松开发自己的连接器并将其集成到SeaTunnel项目中。
支持多种数据源:SeaTunnel支持上百种数据源,包括数据库、云服务和SaaS平台,能够处理海量数据的实时CDC和批量同步。
多引擎支持
SeaTunnel默认使用SeaTunnel引擎进行数据同步,同时也支持使用Apache Flink或Apache Spark作为连接器的执行引擎,以适应企业现有的技术组件。
高吞吐量和低延迟
SeaTunnel支持并行读写,提供稳定可靠的高吞吐量和低延迟的数据同步能力。
完善的实时监控
SeaTunnel支持对数据同步过程中每一步的详细监控信息,让用户轻松了解同步任务的读写数据量、数据大小、QPS等信息。
支持分布式快照算法
SeaTunnel支持分布式快照算法,保证数据一致性。
JDBC多路复用和数据库日志多表解析
SeaTunnel支持多表或整个数据库同步,解决了JDBC过度连接的问题;支持多表或全数据库的日志读取和解析,解决了CDC多表同步场景需要处理日志重复读取和解析的问题。
易于使用
SeaTunnel提供了简单易用的界面,支持编码和画布设计两种作业开发方法,SeaTunnel web项目提供了作业、调度、运行和监控功能的可视化管理。
Flink CDC介绍
Flink CDC是一个基于流的数据集成工具,旨在为用户提供一套功能更加全面的编程接口。 该工具使得用户能够以 YAML 配置文件的形式,优雅地定义其 ETL流程,并协助用户自动化生成定制化的 Flink 算子并且提交 Flink 作业。 Flink CDC 在任务提交过程中进行了优化,并且增加了一些高级特性,如表结构变更自动同步、数据转换、整库同步以及 精确一次语义。Flink CDC深度集成并由Apache Flink驱动,可以高效实现海量数据的实时集成。它支持全增量一体化、无锁读取、并行读取等高级特性。
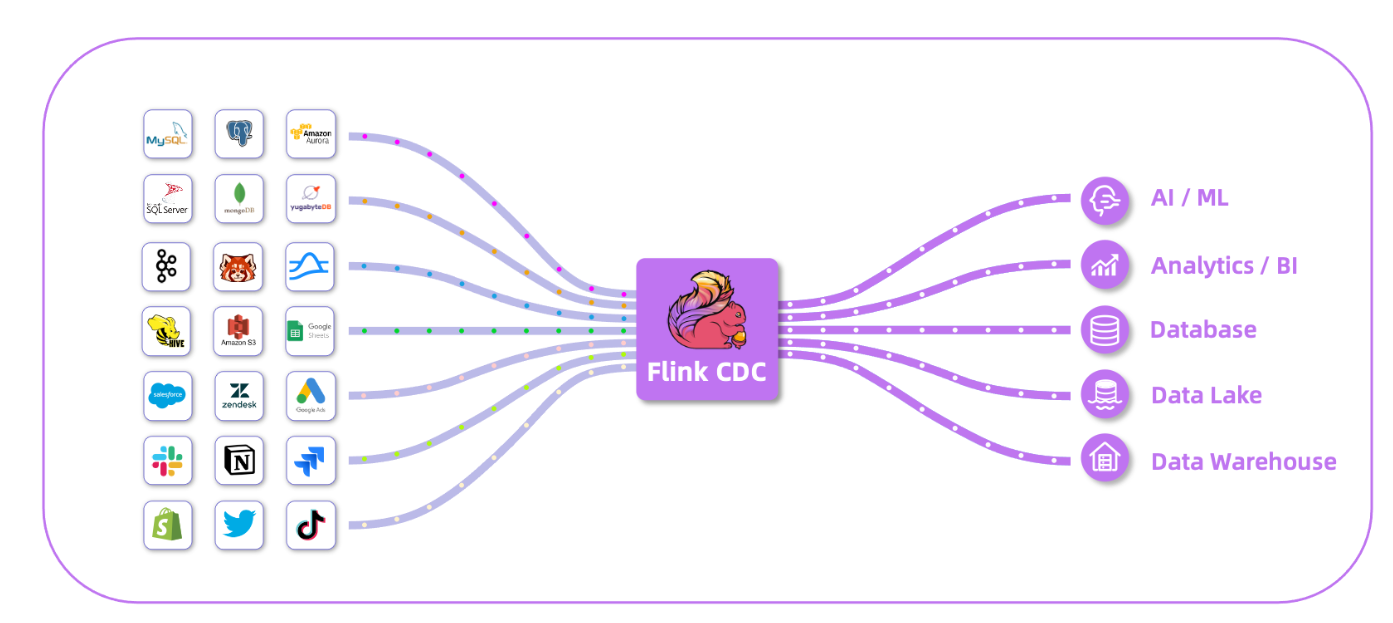
端到端的数据集成框架
为用户提供易于构建作业的API,支持在Source和Sink中处理多个表。
具备表结构变更自动同步的能力
能够自动创建下游表,使用基于上游表推断出的表结构,并在变更数据捕获期间将上游DDL应用到下游系统。
流式处理
Flink CDC作业默认以流式模式运行,提供亚秒级的端到端延迟,在实时binlog同步场景中有效确保了下游业务的数据新鲜度。
数据转换
Flink CDC将支持ETL的数据转换操作,包括列投影、计算列、过滤表达式和经典的标量函数。
整库同步
通过配置捕获的数据库列表和表列表,Flink CDC支持在一个作业中同步源数据库实例的所有表。
精确一次语义
Flink CDC支持读取数据库历史数据,并在即使作业失败后继续以精确一次处理读取CDC事件。
Flink CDC和 Seatunnel 都是用于处理实时数据流的强大工具。将它们结合起来,可以创建一个强大的实时数据集成平台。即可使用Flink CDC实时处理的优势,兼具Seatunnel灵活易用的特性,它能够处理大规模的数据流,提供实时的数据分析和可视化,同时保持系统的稳定性和安全性。
