


在MySQL的InnoDB引擎中,索引可以分为聚簇索引和非聚簇索引。非聚簇索引,包括复合索引、前缀索引、唯一索引等,是通过B+树的数据结构实现的。这些索引在一些文献中也被称为辅助索引或二级索引。
聚簇索引在InnoDB中是特殊的,因为表中的数据就是按照聚簇索引的顺序存储的。聚簇索引是按照每张表的主键构建的B+树,其叶子节点存储的就是整张表的行数据。因为数据只能按照一种顺序排序,所以每张表只能有一个聚簇索引。在InnoDB中,聚簇索引默认就是主键索引。
如果表没有主键,InnoDB会按照以下规则创建聚簇索引:
- 如果没有主键,InnoDB会选择一个唯一且非空的索引列作为主键,用以创建聚簇索引。
- 如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。
需要注意的是,主键的选择会影响到性能。例如,如果主键是自增ID,由于聚簇索引的特性,相应的数据也会相邻地存储在磁盘上,这样写入性能会比较高。而如果主键是UUID,频繁的插入操作会使得InnoDB需要频繁地移动磁盘块,从而降低写入性能。
先来一张带主键的表,如下所示,pId是主键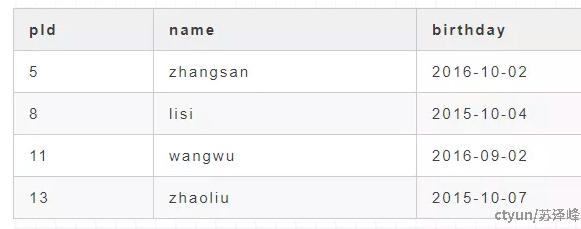
表的索引结构图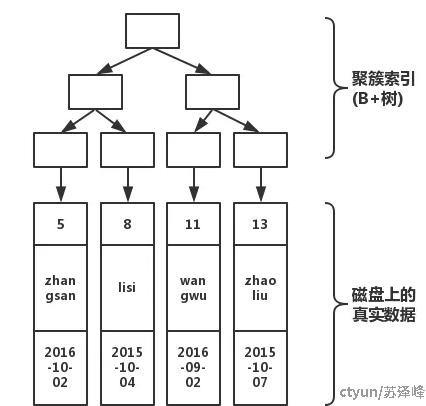
上半部分是由主键形成的B+树,下半部分就是磁盘上真实的数据
执行语句,select * from table where pId='11',索引过程如下
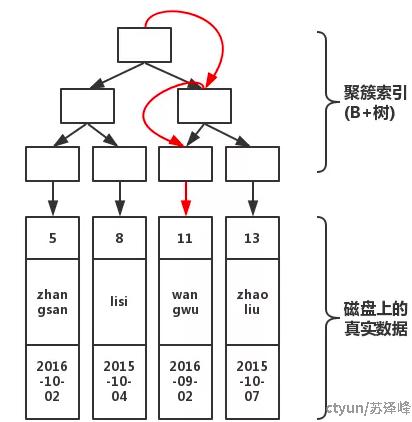
从B+树的根节点开始,通过三次查找就可以找到真实的数据。相比之下,如果不使用索引,那么就需要在磁盘上逐行扫描直到找到数据,这无疑会消耗更多的时间。因此,使用索引可以显著提高查询速度。
然而,虽然索引可以提高查询速度,但在写入数据时,需要维护B+树的结构,这会导致写入性能下降。每次在表中插入或更新数据时,都需要更新索引,这会消耗一定的时间和计算资源。因此,在设计数据库时,需要在查询性能和写入性能之间进行权衡。
接下来引入非聚簇索引,执行create index index_name on table(name);
索引结构如图
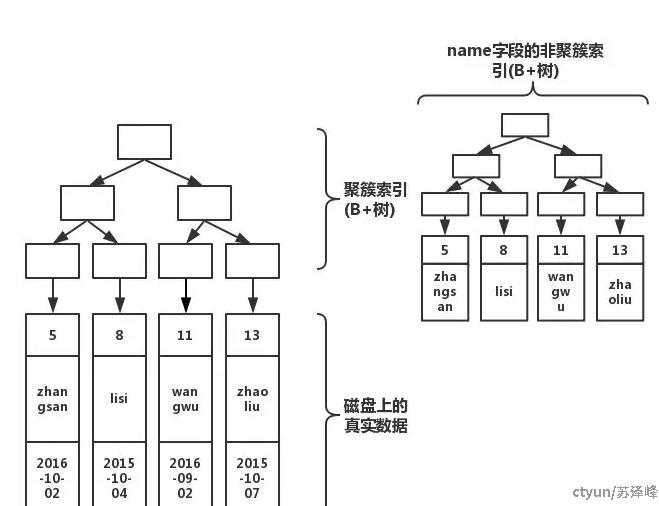
每当你在表上创建一个新的索引,系统会根据你的索引字段生成一棵新的B+树。因此,每添加一个索引,都会增加表的大小,并占用更多的磁盘存储空间。然而,值得注意的是,非聚簇索引的叶子节点并不是存储真实数据的地方。相反,它的叶子节点仍然是索引节点,存储的是索引字段的值以及对应的主键索引(也就是聚簇索引)。
执行查询,select * from table where name='lisi',索引流程如下,
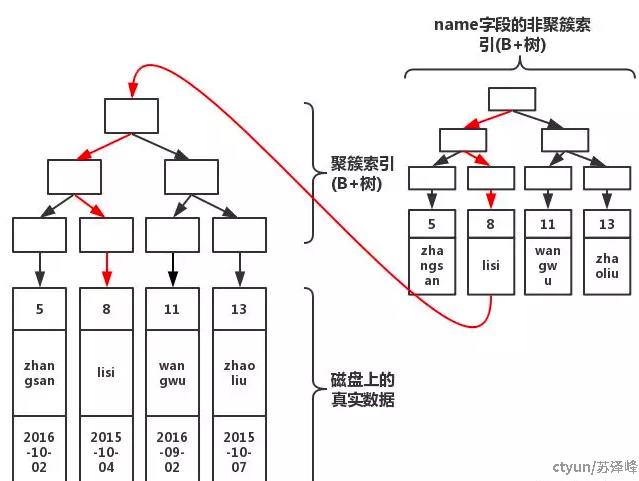
这就意味着,当我们通过非聚簇索引查询数据时,系统首先会在非聚簇索引的B+树中查找到对应的主键索引,然后再通过主键索引去聚簇索引的B+树中查找到真实的数据。这就是为什么非聚簇索引查询有时被称为“回表查询”的原因。
如果,此时我们执行:select name from table where name='lisi'
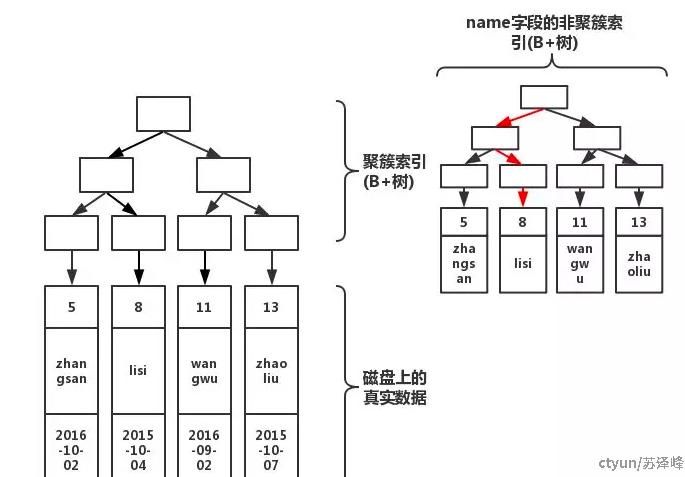
如果在非聚簇索引树上找到了想要的值,就不会去聚簇索引树上查询。
我们执行以下语句,索引结构又会发生什么变化
create index index_birthday on table(birthday);
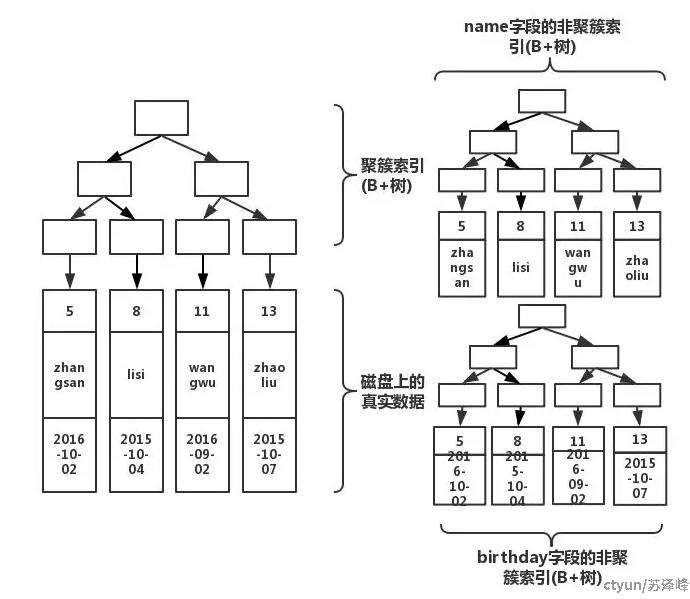
多加了一个索引,就会多生成一颗非聚簇索引树。在做插入操作的时候,需要多维护一颗树的变化。
因此,如果索引太多,插入性能就会下降。
