用于视觉识别的视觉语言模型(VLM)能够有效地使用网络数据,并允许零样本预测,而无需特定于任务的微调,在广泛的识别任务中取得了巨大的成功。本报告从VLM的研究背景、研究意义、理论框架、技术方法、商业化大模型和未来的研究方向等几个方面对VLM进行了调研,并将不同的算法进行了比较总结。
一、研究背景:
许多视觉识别研究在深度神经网络(DNNs)训练中依赖大量的人工标注数据,并且通常为每个单独的视觉识别任务训练一个独立的DNN,这种方式繁琐且耗时。Vision-Language Models(VLM)的出现为解决这些挑战带来了希望。通过从互联网上大量的图像-文本对中学习到丰富的视觉-语言关联,就能够在只使用一个单一VLM模型的情况下实现对各种视觉任务的zero-shot预测,并且取得很好的效果。近年来,关于VLM的论文一直呈上升趋势,如下图所示。


二、研究意义:
视觉识别范式的发展可以广泛地分为以下五个阶段:
- Traditional Machine Learning and Prediction:使用手工设计的特征和传统机器学习算法进行训练和预测,需要大量的人工参与和专业知识。
- Deep Learning from Scratch and Prediction:使用深度神经网络(DNN)进行端到端的训练和预测。和第一阶段相比,该范式使用DNN代替了人工设计的特征,实现了计算机视觉任务的巨大跨越。不过这方法需要大量的标注数据,并且容易出现过拟合问题。
- Supervised Pre-training, Fine-tuning and Prediction:使用大规模标注数据进行监督式预训练,然后在特定任务上微调并进行预测。和第二阶段相比,该范式在用于特定任务时,可以通过微调的方式来更好地利用有限的标注数据。如下图(a)。
- Unsupervised Pre-training, Fine-tuning and Prediction:使用无标注数据进行无监督式预训练,然后在特定任务上微调并进行预测。相比于第三阶段的监督式方法,更好地利用未标注数据。如下图(b)。
- VLM Pre-training and Zero-shot Prediction:使用视觉-语言相关性进行大规模无监督式预训练,并且可以在各种视觉识别任务中进行零样本预测。和第四阶段相比,这种方法不需要针对特定任务进行微调即可取得出色的效果。如下图(c)。

这五个阶段的对比如下表所示:
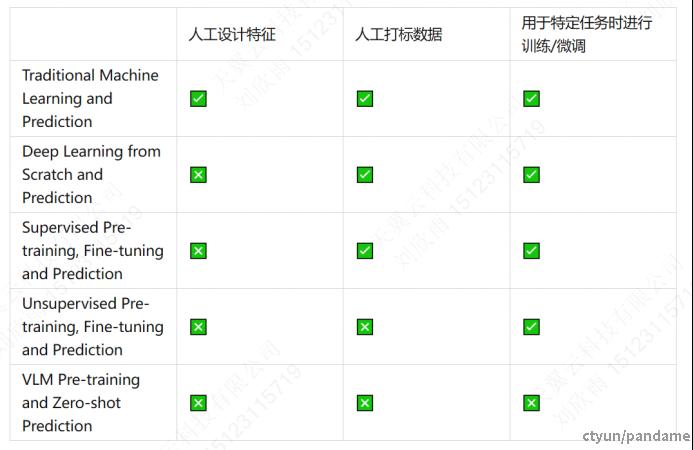
各个范式的演进过程就是一步一步地减少中间环节依赖(如人工设计特征、大量人工打标数据、用于特定任务时进行训练/微调)的过程,也是模型的泛化性逐渐提升的过程。VLM Pre-training and Zero-shot Prediction 的范式使得模型训练时不需要人工设计特征,也不需要海量的打标数据,并且在用于下游任务时不需要针对特定任务进行微调,直接zero-shot就能取得不错的效果。能实现这一效果的关键就在于强大的预训练VLMs。
三、理论框架:
视觉模型理论架构的形成:从Transformer到ViT,再到MAE。
以Transformer的提出时间为分界线,在Transformer提出之后,大模型的基础模型架构基本形成。原因有二:一是注意力机制代替卷积神经网络称为主流基础模型组件,这有利于模型向更大的参数量扩展;二是Transformer有着兼容多模态信息的天生优势特性,丰富了大模型的应用场景。下图是Transformer的网络架构。

ViT是Transformer在CV领域的拓展。在ViT之后,人们看到了使用统一模型处理多模态信息的有效解决方案,多模态信息的处理保证了大模型的应用场景丰富性。下图是Transformer的网络架构。

MAE是一种ViT的训练方式,它的本质是一种自监督学习方法。MAE提出的意义是ViT这种需要海量数据投喂的大规模网络模型,如何有效率地、在模型继续增长的前提下数据需求也会增长的情况下,能可行地完成训练任务。下图是Transformer的网络架构。

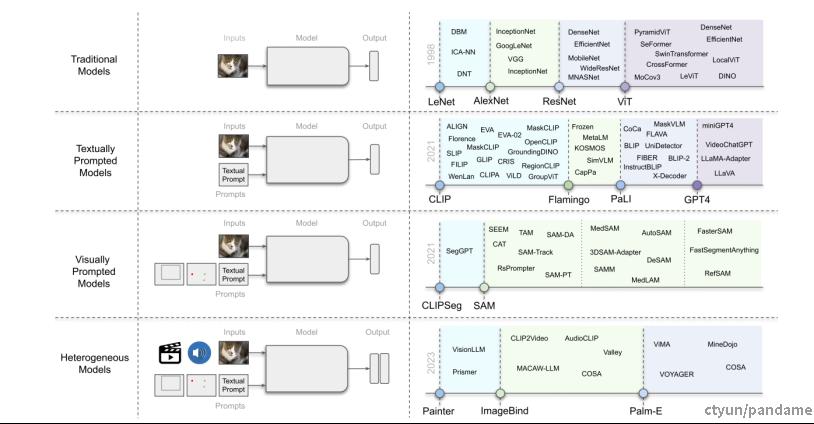
计算机视觉基础模型的发展如下图所示,(左)展示了计算机视觉模型的进展,(右)用虚线显示了这些模型的演变。