


DLROver简介:
DLRover 使大型 AI 模型的分布式训练变得简单、稳定、快速、绿色。它可以在分布式集群上自动训练深度学习模型。它帮助模型开发人员专注于模型架构,而无需关心硬件加速、分布式运行等任何工程内容。目前为 K8s/Ray 上的深度学习训练作业提供自动化运维。主要特点为
- 容错性:分布式训练在发生故障时可以继续运行。
- Flash Checkpoint:分布式训练可以在几秒内从内存检查点恢复故障。
- 自动扩展:分布式训练可以扩展/缩减资源,以提高稳定性、吞吐量和资源利用率。
Fault Tolerance:
容错功能可减少大规模训练作业的停机时间,DLRover 可以在进程失败时恢复训练,而无需停止训练作业。恢复 DLRover 训练的行动包括:
- 自动诊断故障原因。
- 由于软件错误,重新启动进程而不是节点。
- 重新启动由于硬件错误而发生故障的节点。
Flash Checkpoint:
通过 Flash Checkpoint,可在几秒钟内保存/加载检查点,训练可以频繁保存检查点,并减少发生故障时从最新检查点恢复训练的回滚步骤。 Flash检查点的特点是:
- 将检查点异步持久化到存储中。
- 一旦训练过程失败,将检查点持久化到存储中。
- 训练过程重新启动后,从主机内存加载检查点。
- 适用于 DDP、FSDP、DeepSpeed 和 Megatron-LM 的 API。
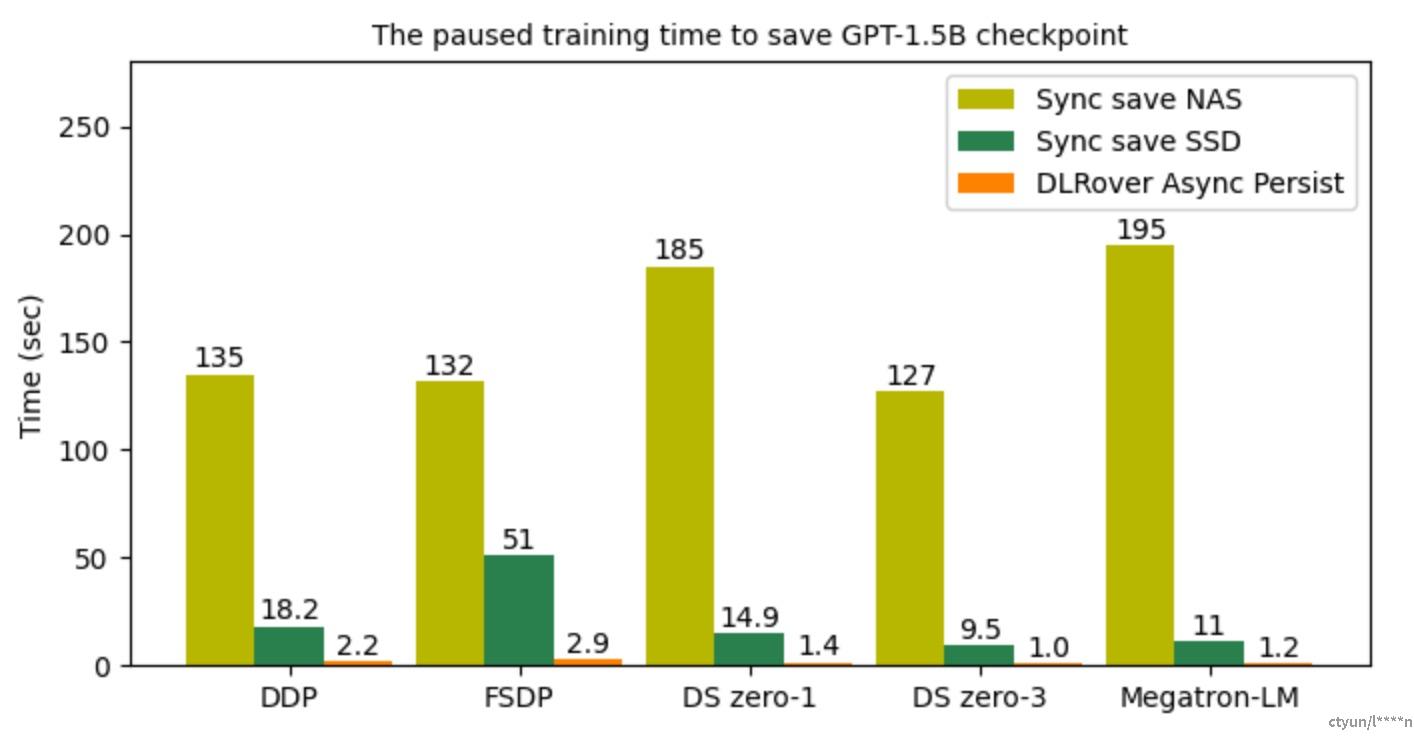
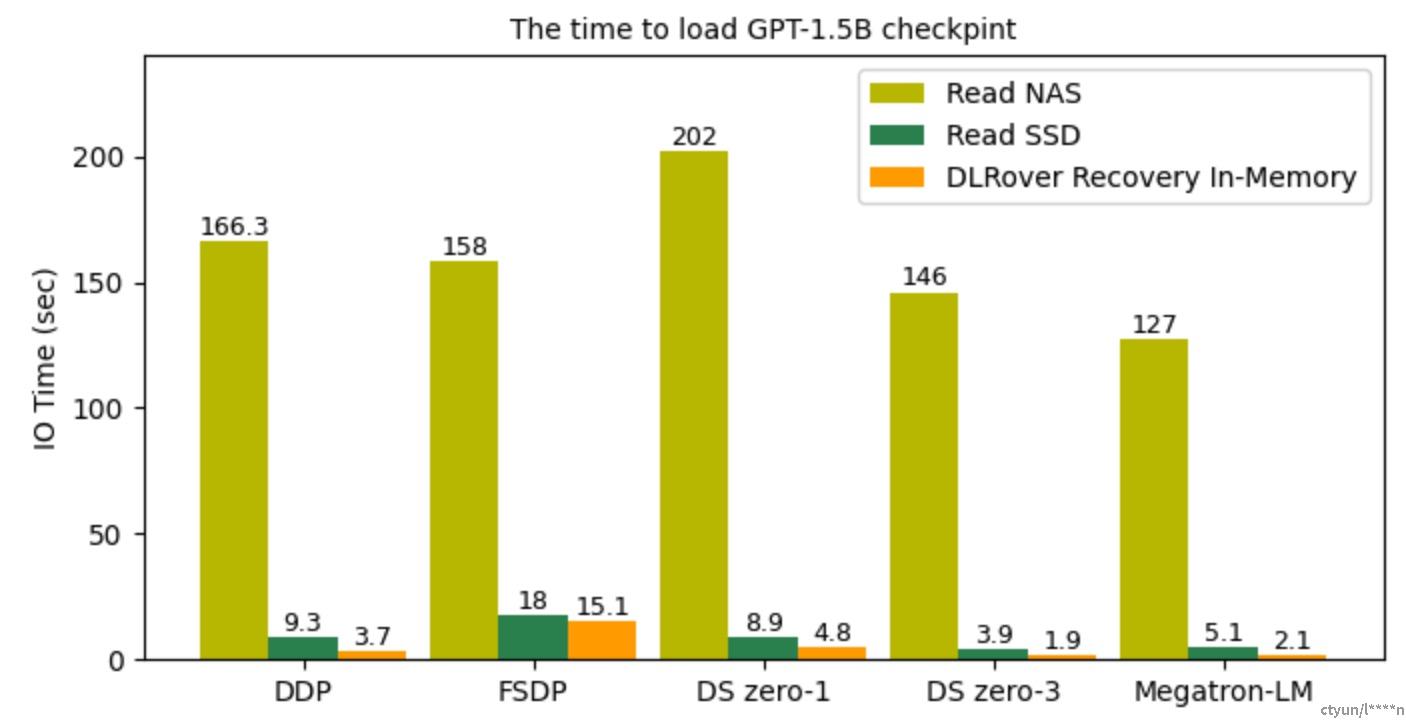
该图(图片来源dlrover github README.md)说明了恢复训练过程时不同深度学习框架读取检查点文件的 I/O 时间。借助 DLRover Flash Checkpoint,通过直接从共享内存加载检查点,可以在几秒内完成恢复,这比从 SSD 和 NAS 加载检查点要快得多。
Auto-Scaling:
自动扩展以提高训练性能和资源利用率,DLRover 在训练作业运行时自动扩展/缩减资源(用于参数服务器或工作线程)。通过监控节点的工作负载和吞吐量,DLRover可以诊断资源配置的瓶颈。常见的瓶颈有节点掉队、PS工作负载不均衡、节点CPU核数不足、节点数量不足等。 DLRover可以通过动态资源调整来提高训练性能。
为了提高训练吞吐量,用户更愿意为自己的作业配置超额资源,以避免资源不足带来的潜在风险。这通常会导致巨大的资源浪费。 DLRover Auto-Scaling可以根据模型训练的需求来分配资源,减少资源浪费。
