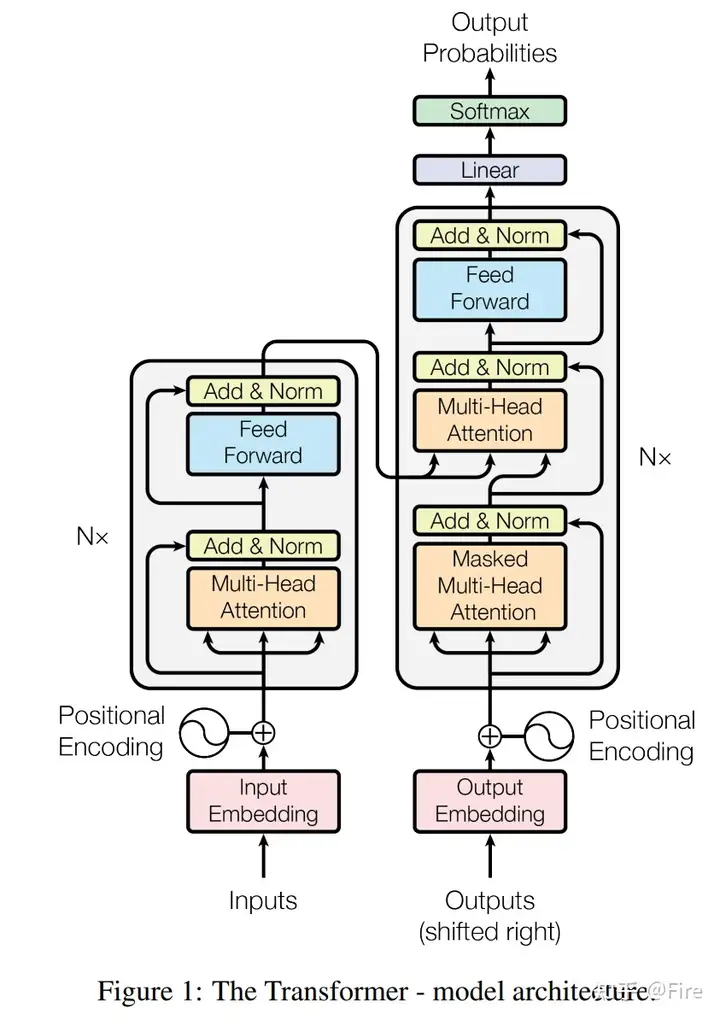
# 生成序列的填充掩码:将序列中的填充部分标记为0,非填充部分标记为1defget_pad_mask(seq,pad_idx):# (batch_size, seq_len)变为(batch_size, 1, seq_len)return(seq!=pad_idx).unsqueeze(-2)# 生成后续信息掩码,屏蔽序列中当前位置之后的信息defget_subsequent_mask(seq):''' For masking out the subsequent info. '''sz_b,len_s=seq.size()# torch.triu上三角矩阵,diagonal=1表示生成的上三角矩阵,保留主对角线上方一条对角线及以上的元素subsequent_mask=(1-torch.triu(torch.ones((1,len_s,len_s),device=seq.device),diagonal=1)).bool()returnsubsequent_mask
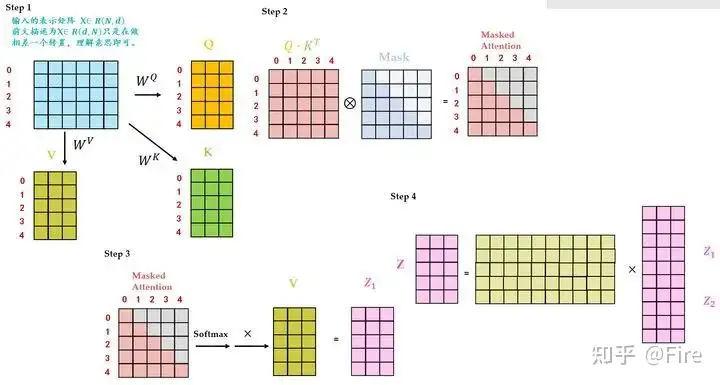
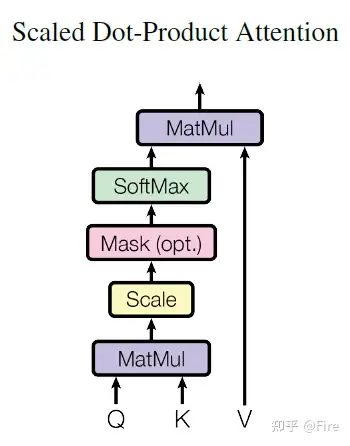
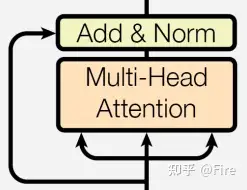
importnumpyasnpimporttorch.nnasnnimporttorch.nn.functionalasFfromtransformer.ModulesimportScaledDotProductAttention__author__="Yu-Hsiang Huang"classMultiHeadAttention(nn.Module):''' Multi-Head Attention module '''# n_head(注意力头的数量),d_model(输入向量的维度),d_k(每个头的查询向量维度),d_v(每个头的键值向量维度)def__init__(self,n_head,d_model,d_k,d_v,dropout=0.1):super().__init__()self.n_head=n_headself.d_k=d_kself.d_v=d_v# 将输入向量映射到多个头的查询、键和值向量self.w_qs=nn.Linear(d_model,n_head*d_k,bias=False)self.w_ks=nn.Linear(d_model,n_head*d_k,bias=False)self.w_vs=nn.Linear(d_model,n_head*d_v,bias=False)# 将多个头的值向量合并为最终的输出向量self.fc=nn.Linear(n_head*d_v,d_model,bias=False)self.attention=ScaledDotProductAttention(temperature=d_k**0.5)self.dropout=nn.Dropout(dropout)self.layer_norm=nn.LayerNorm(d_model,eps=1e-6)defforward(self,q,k,v,mask=None):d_k,d_v,n_head=self.d_k,self.d_v,self.n_headsz_b,len_q,len_k,len_v=q.size(0),q.size(1),k.size(1),v.size(1)# 保存输入的残差值residual=q# Pass through the pre-attention projection: b x lq x (n*dv)# Separate different heads: b x lq x n x dvq=self.w_qs(q).view(sz_b,len_q,n_head,d_k)k=self.w_ks(k).view(sz_b,len_k,n_head,d_k)v=self.w_vs(v).view(sz_b,len_v,n_head,d_v)# Transpose for attention dot product: b x n x lq x dvq,k,v=q.transpose(1,2),k.transpose(1,2),v.transpose(1,2)ifmaskisnotNone:mask=mask.unsqueeze(1)# For head axis broadcasting.q,attn=self.attention(q,k,v,mask=mask)# Transpose to move the head dimension back: b x lq x n x dv# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)# contiguous()使内存布局连续q=q.transpose(1,2).contiguous().view(sz_b,len_q,-1)q=self.dropout(self.fc(q))q+=residualq=self.layer_norm(q)returnq,attn
classPositionwiseFeedForward(nn.Module):''' A two-feed-forward-layer module '''def__init__(self,d_in,d_hid,dropout=0.1):super().__init__()# position-wise:对输入张量的每个位置(维度)都应用相同的操作,d_hid:隐藏层维度,d_in:输入张量维度self.w_1=nn.Linear(d_in,d_hid)# position-wiseself.w_2=nn.Linear(d_hid,d_in)# position-wiseself.layer_norm=nn.LayerNorm(d_in,eps=1e-6)self.dropout=nn.Dropout(dropout)defforward(self,x):# x: b x lq x dvresidual=x# 使用 ReLU 激活函数进行非线性变换x=self.w_2(F.relu(self.w_1(x)))# 应用 Dropout 正则化以减少过拟合风险x=self.dropout(x)x+=residualx=self.layer_norm(x)returnx
''' Define the Layers '''importtorch.nnasnnimporttorchfromtransformer.SubLayersimportMultiHeadAttention,PositionwiseFeedForward__author__="Yu-Hsiang Huang"classEncoderLayer(nn.Module):''' Compose with two layers '''def__init__(self,d_model,d_inner,n_head,d_k,d_v,dropout=0.1):super(EncoderLayer,self).__init__()self.slf_attn=MultiHeadAttention(n_head,d_model,d_k,d_v,dropout=dropout)self.pos_ffn=PositionwiseFeedForward(d_model,d_inner,dropout=dropout)defforward(self,enc_input,slf_attn_mask=None):enc_output,enc_slf_attn=self.slf_attn(enc_input,enc_input,enc_input,mask=slf_attn_mask)enc_output=self.pos_ffn(enc_output)returnenc_output,enc_slf_attn
原理:
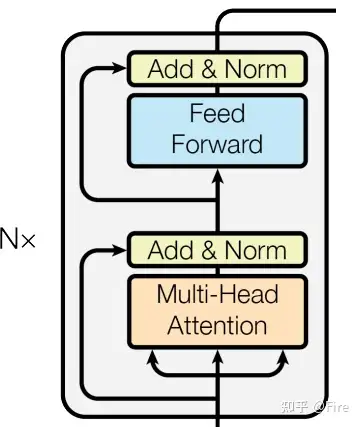
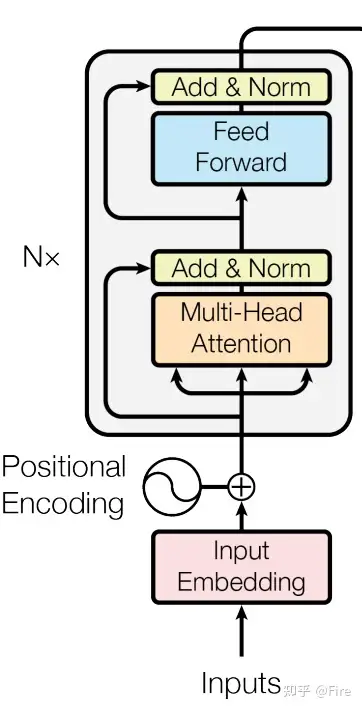
Encoder
代码文件:transformer/Models.py
代码:
classEncoder(nn.Module):''' A encoder model with self attention mechanism. '''def__init__(self,n_src_vocab,d_word_vec,n_layers,n_head,d_k,d_v,d_model,d_inner,pad_idx,dropout=0.1,n_position=200,scale_emb=False):super().__init__()# n_src_vocab: 输入数据的词汇表大小;d_word_vec: 词嵌入向量的维度;n_position: 输入序列最大长度;pad_idx: 填充符号的索引self.src_word_emb=nn.Embedding(n_src_vocab,d_word_vec,padding_idx=pad_idx)self.position_enc=PositionalEncoding(d_word_vec,n_position=n_position)self.dropout=nn.Dropout(p=dropout)# n_layers: 编码器中的层数;n_head: 注意力头的数量;d_k: Q, K 向量的维度;d_v: V 向量的维度;d_model: 模型的隐藏层维度;d_inner: 前馈网络隐藏层的维度;scale_emb: 是否在词嵌入向量上应用缩放因子self.layer_stack=nn.ModuleList([EncoderLayer(d_model,d_inner,n_head,d_k,d_v,dropout=dropout)for_inrange(n_layers)])self.layer_norm=nn.LayerNorm(d_model,eps=1e-6)self.scale_emb=scale_embself.d_model=d_modeldefforward(self,src_seq,src_mask,return_attns=False):enc_slf_attn_list=[]# -- Forward# 对输入序列 src_seq 应用词嵌入和位置编码enc_output=self.src_word_emb(src_seq)# 如果 scale_emb 为 True,则在词嵌入向量上应用缩放因子。ifself.scale_emb:enc_output*=self.d_model**0.5# 对经过词嵌入和位置编码的向量进行 Dropout 和归一化enc_output=self.dropout(self.position_enc(enc_output))enc_output=self.layer_norm(enc_output)# 依次对每个 EncoderLayer 进行前向传播,并将每个 EncoderLayer 的自注意力矩阵添加到 enc_slf_attn_list 中forenc_layerinself.layer_stack:enc_output,enc_slf_attn=enc_layer(enc_output,slf_attn_mask=src_mask)enc_slf_attn_list+=[enc_slf_attn]ifreturn_attnselse[]# 如果 return_attns 为 True,则返回编码器输出和所有自注意力矩阵,否则只返回编码器输出ifreturn_attns:returnenc_output,enc_slf_attn_listreturnenc_output,
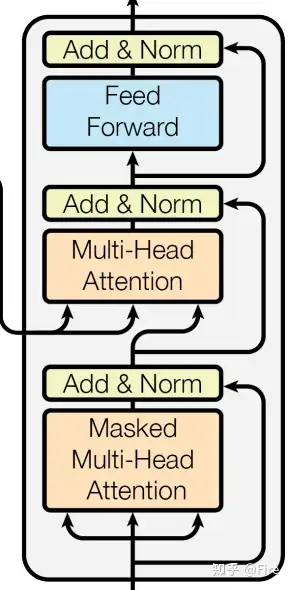
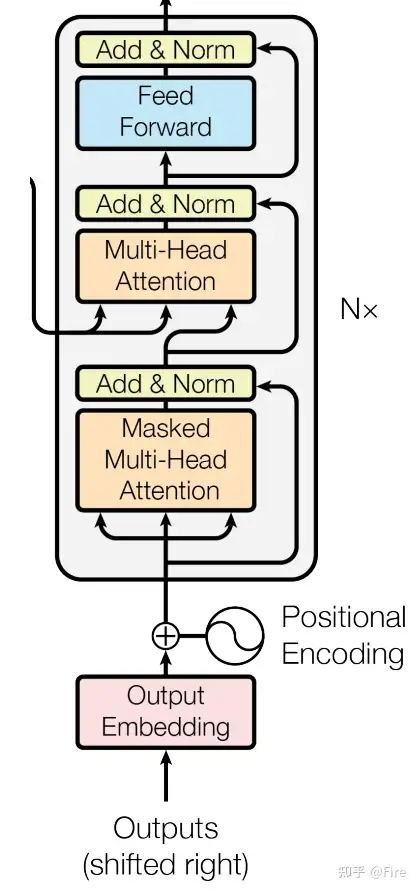
classTransformer(nn.Module):# 带有注意力机制的序列到序列模型''' A sequence to sequence model with attention mechanism. '''# trg_emb_prj_weight_sharing和 emb_src_trg_weight_sharing 分别表示是否共享目标语言词嵌入和线性映射权重,scale_emb_or_prj 表示在共享时是否需要对词嵌入或线性映射进行缩放操作。def__init__(self,n_src_vocab,n_trg_vocab,src_pad_idx,trg_pad_idx,d_word_vec=512,d_model=512,d_inner=2048,n_layers=6,n_head=8,d_k=64,d_v=64,dropout=0.1,n_position=200,trg_emb_prj_weight_sharing=True,emb_src_trg_weight_sharing=True,scale_emb_or_prj='prj'):super().__init__()self.src_pad_idx,self.trg_pad_idx=src_pad_idx,trg_pad_idx# In section 3.4 of paper "Attention Is All You Need", there is such detail:# "In our model, we share the same weight matrix between the two# embedding layers and the pre-softmax linear transformation...# In the embedding layers, we multiply those weights by \sqrt{d_model}".# 控制Transformer模型的参数设置,决定了在使用共享权重的情况下,如何对嵌入层和线性变换进行参数缩放。# Options here:# 在嵌入层中,将每个单词嵌入向量的维度乘以\sqrt{d_model},从而扩大向量的表示范围;d_model是模型中隐藏层的维度。# 'emb': multiply \sqrt{d_model} to embedding output# 对于线性变换,将每个单词嵌入向量的维度除以\sqrt{d_model},从而缩小输出的范围;# 'prj': multiply (\sqrt{d_model} ^ -1) to linear projection output# 'none': no multiplicationassertscale_emb_or_prjin['emb','prj','none']# 如果 trg_emb_prj_weight_sharing 为真,则 scale_emb 将会根据 scale_emb_or_prj 的取值来决定是否对词嵌入层进行缩放;self.scale_prj 则是根据 scale_emb_or_prj 的取值来决定是否对线性映射层进行缩放。scale_emb=(scale_emb_or_prj=='emb')iftrg_emb_prj_weight_sharingelseFalseself.scale_prj=(scale_emb_or_prj=='prj')iftrg_emb_prj_weight_sharingelseFalseself.d_model=d_modelself.encoder=Encoder(n_src_vocab=n_src_vocab,n_position=n_position,d_word_vec=d_word_vec,d_model=d_model,d_inner=d_inner,n_layers=n_layers,n_head=n_head,d_k=d_k,d_v=d_v,pad_idx=src_pad_idx,dropout=dropout,scale_emb=scale_emb)self.decoder=Decoder(n_trg_vocab=n_trg_vocab,n_position=n_position,d_word_vec=d_word_vec,d_model=d_model,d_inner=d_inner,n_layers=n_layers,n_head=n_head,d_k=d_k,d_v=d_v,pad_idx=trg_pad_idx,dropout=dropout,scale_emb=scale_emb)# 通过线性映射层将解码器输出映射到目标语言词汇表大小self.trg_word_prj=nn.Linear(d_model,n_trg_vocab,bias=False)# self.parameters()返回模型所有参数forpinself.parameters():# 对于每一个参数 p,通过判断其维度大小是否大于 1,来确定是否需要进行初始化操作。# 一般来说,只有权重矩阵等具有多个元素的参数才需要进行初始化。ifp.dim()>1:# Xavier Uniform 初始化。它的目的是根据输入和输出维度来初始化参数的取值范围,使得网络层在前向传播和反向传播时能够更好地保持梯度稳定,避免梯度消失或爆炸的问题。# Xavier Uniform 初始化会将参数 p 中的数值从一个均匀分布中采样,采样范围的上下界根据输入和输出维度进行计算。这样可以确保参数的初始化值既不过大也不过小,有利于模型的训练和优化过程。nn.init.xavier_uniform_(p)# 要使用残差连接,需要保证各个模块的输入和输出维度一致,以便进行加法运算。# 确保模型中各个模块输出的维度与 d_model 相等,以便正确地使用残差连接。如果维度不一致,就会抛出异常信息,提醒开发者修改模型设计assertd_model==d_word_vec, \
'To facilitate the residual connections, \
the dimensions of all module outputs shall be the same.'# 实现目标词嵌入层(target word embedding)和最后一个全连接层(dense layer)之间的权重共享iftrg_emb_prj_weight_sharing:# Share the weight between target word embedding & last dense layer# 将目标词嵌入层的权重设置为解码器(decoder)中目标词嵌入层的权重self.trg_word_prj.weight=self.decoder.trg_word_emb.weight# 源语言和目标语言词嵌入层之间的权重共享ifemb_src_trg_weight_sharing:# 将编码器(encoder)中源语言词嵌入层的权重设置为解码器中目标语言词嵌入层的权重self.encoder.src_word_emb.weight=self.decoder.trg_word_emb.weightdefforward(self,src_seq,trg_seq):src_mask=get_pad_mask(src_seq,self.src_pad_idx)trg_mask=get_pad_mask(trg_seq,self.trg_pad_idx)&get_subsequent_mask(trg_seq)enc_output,*_=self.encoder(src_seq,src_mask)dec_output,*_=self.decoder(trg_seq,trg_mask,enc_output,src_mask)seq_logit=self.trg_word_prj(dec_output)ifself.scale_prj:seq_logit*=self.d_model**-0.5# seq_logit 的形状为 (batch_size, seq_len, vocab_size),其中 batch_size 表示批量大小,seq_len 表示序列长度,vocab_size 表示词汇表大小# 调用 view 函数对 seq_logit 进行形状变换,将其变成一个二维的张量。第一维表示所有序列的总数,也就是 batch_size * seq_len;第二维表示每个序列可能的输出单词数量,即 vocab_size。returnseq_logit.view(-1,seq_logit.size(2))
# 生成序列的填充掩码:将序列中的填充部分标记为0,非填充部分标记为1defget_pad_mask(seq,pad_idx):# (batch_size, seq_len)变为(batch_size, 1, seq_len)return(seq!=pad_idx).unsqueeze(-2)# 生成后续信息掩码,屏蔽序列中当前位置之后的信息defget_subsequent_mask(seq):''' For masking out the subsequent info. '''sz_b,len_s=seq.size()# torch.triu上三角矩阵,diagonal=1表示生成的上三角矩阵,保留主对角线上方一条对角线及以上的元素subsequent_mask=(1-torch.triu(torch.ones((1,len_s,len_s),device=seq.device),diagonal=1)).bool()returnsubsequent_mask
importnumpyasnpimporttorch.nnasnnimporttorch.nn.functionalasFfromtransformer.ModulesimportScaledDotProductAttention__author__="Yu-Hsiang Huang"classMultiHeadAttention(nn.Module):''' Multi-Head Attention module '''# n_head(注意力头的数量),d_model(输入向量的维度),d_k(每个头的查询向量维度),d_v(每个头的键值向量维度)def__init__(self,n_head,d_model,d_k,d_v,dropout=0.1):super().__init__()self.n_head=n_headself.d_k=d_kself.d_v=d_v# 将输入向量映射到多个头的查询、键和值向量self.w_qs=nn.Linear(d_model,n_head*d_k,bias=False)self.w_ks=nn.Linear(d_model,n_head*d_k,bias=False)self.w_vs=nn.Linear(d_model,n_head*d_v,bias=False)# 将多个头的值向量合并为最终的输出向量self.fc=nn.Linear(n_head*d_v,d_model,bias=False)self.attention=ScaledDotProductAttention(temperature=d_k**0.5)self.dropout=nn.Dropout(dropout)self.layer_norm=nn.LayerNorm(d_model,eps=1e-6)defforward(self,q,k,v,mask=None):d_k,d_v,n_head=self.d_k,self.d_v,self.n_headsz_b,len_q,len_k,len_v=q.size(0),q.size(1),k.size(1),v.size(1)# 保存输入的残差值residual=q# Pass through the pre-attention projection: b x lq x (n*dv)# Separate different heads: b x lq x n x dvq=self.w_qs(q).view(sz_b,len_q,n_head,d_k)k=self.w_ks(k).view(sz_b,len_k,n_head,d_k)v=self.w_vs(v).view(sz_b,len_v,n_head,d_v)# Transpose for attention dot product: b x n x lq x dvq,k,v=q.transpose(1,2),k.transpose(1,2),v.transpose(1,2)ifmaskisnotNone:mask=mask.unsqueeze(1)# For head axis broadcasting.q,attn=self.attention(q,k,v,mask=mask)# Transpose to move the head dimension back: b x lq x n x dv# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)# contiguous()使内存布局连续q=q.transpose(1,2).contiguous().view(sz_b,len_q,-1)q=self.dropout(self.fc(q))q+=residualq=self.layer_norm(q)returnq,attn
classPositionwiseFeedForward(nn.Module):''' A two-feed-forward-layer module '''def__init__(self,d_in,d_hid,dropout=0.1):super().__init__()# position-wise:对输入张量的每个位置(维度)都应用相同的操作,d_hid:隐藏层维度,d_in:输入张量维度self.w_1=nn.Linear(d_in,d_hid)# position-wiseself.w_2=nn.Linear(d_hid,d_in)# position-wiseself.layer_norm=nn.LayerNorm(d_in,eps=1e-6)self.dropout=nn.Dropout(dropout)defforward(self,x):# x: b x lq x dvresidual=x# 使用 ReLU 激活函数进行非线性变换x=self.w_2(F.relu(self.w_1(x)))# 应用 Dropout 正则化以减少过拟合风险x=self.dropout(x)x+=residualx=self.layer_norm(x)returnx
''' Define the Layers '''importtorch.nnasnnimporttorchfromtransformer.SubLayersimportMultiHeadAttention,PositionwiseFeedForward__author__="Yu-Hsiang Huang"classEncoderLayer(nn.Module):''' Compose with two layers '''def__init__(self,d_model,d_inner,n_head,d_k,d_v,dropout=0.1):super(EncoderLayer,self).__init__()self.slf_attn=MultiHeadAttention(n_head,d_model,d_k,d_v,dropout=dropout)self.pos_ffn=PositionwiseFeedForward(d_model,d_inner,dropout=dropout)defforward(self,enc_input,slf_attn_mask=None):enc_output,enc_slf_attn=self.slf_attn(enc_input,enc_input,enc_input,mask=slf_attn_mask)enc_output=self.pos_ffn(enc_output)returnenc_output,enc_slf_attn
原理:
Encoder
代码文件:transformer/Models.py
代码:
classEncoder(nn.Module):''' A encoder model with self attention mechanism. '''def__init__(self,n_src_vocab,d_word_vec,n_layers,n_head,d_k,d_v,d_model,d_inner,pad_idx,dropout=0.1,n_position=200,scale_emb=False):super().__init__()# n_src_vocab: 输入数据的词汇表大小;d_word_vec: 词嵌入向量的维度;n_position: 输入序列最大长度;pad_idx: 填充符号的索引self.src_word_emb=nn.Embedding(n_src_vocab,d_word_vec,padding_idx=pad_idx)self.position_enc=PositionalEncoding(d_word_vec,n_position=n_position)self.dropout=nn.Dropout(p=dropout)# n_layers: 编码器中的层数;n_head: 注意力头的数量;d_k: Q, K 向量的维度;d_v: V 向量的维度;d_model: 模型的隐藏层维度;d_inner: 前馈网络隐藏层的维度;scale_emb: 是否在词嵌入向量上应用缩放因子self.layer_stack=nn.ModuleList([EncoderLayer(d_model,d_inner,n_head,d_k,d_v,dropout=dropout)for_inrange(n_layers)])self.layer_norm=nn.LayerNorm(d_model,eps=1e-6)self.scale_emb=scale_embself.d_model=d_modeldefforward(self,src_seq,src_mask,return_attns=False):enc_slf_attn_list=[]# -- Forward# 对输入序列 src_seq 应用词嵌入和位置编码enc_output=self.src_word_emb(src_seq)# 如果 scale_emb 为 True,则在词嵌入向量上应用缩放因子。ifself.scale_emb:enc_output*=self.d_model**0.5# 对经过词嵌入和位置编码的向量进行 Dropout 和归一化enc_output=self.dropout(self.position_enc(enc_output))enc_output=self.layer_norm(enc_output)# 依次对每个 EncoderLayer 进行前向传播,并将每个 EncoderLayer 的自注意力矩阵添加到 enc_slf_attn_list 中forenc_layerinself.layer_stack:enc_output,enc_slf_attn=enc_layer(enc_output,slf_attn_mask=src_mask)enc_slf_attn_list+=[enc_slf_attn]ifreturn_attnselse[]# 如果 return_attns 为 True,则返回编码器输出和所有自注意力矩阵,否则只返回编码器输出ifreturn_attns:returnenc_output,enc_slf_attn_listreturnenc_output,
classTransformer(nn.Module):# 带有注意力机制的序列到序列模型''' A sequence to sequence model with attention mechanism. '''# trg_emb_prj_weight_sharing和 emb_src_trg_weight_sharing 分别表示是否共享目标语言词嵌入和线性映射权重,scale_emb_or_prj 表示在共享时是否需要对词嵌入或线性映射进行缩放操作。def__init__(self,n_src_vocab,n_trg_vocab,src_pad_idx,trg_pad_idx,d_word_vec=512,d_model=512,d_inner=2048,n_layers=6,n_head=8,d_k=64,d_v=64,dropout=0.1,n_position=200,trg_emb_prj_weight_sharing=True,emb_src_trg_weight_sharing=True,scale_emb_or_prj='prj'):super().__init__()self.src_pad_idx,self.trg_pad_idx=src_pad_idx,trg_pad_idx# In section 3.4 of paper "Attention Is All You Need", there is such detail:# "In our model, we share the same weight matrix between the two# embedding layers and the pre-softmax linear transformation...# In the embedding layers, we multiply those weights by \sqrt{d_model}".# 控制Transformer模型的参数设置,决定了在使用共享权重的情况下,如何对嵌入层和线性变换进行参数缩放。# Options here:# 在嵌入层中,将每个单词嵌入向量的维度乘以\sqrt{d_model},从而扩大向量的表示范围;d_model是模型中隐藏层的维度。# 'emb': multiply \sqrt{d_model} to embedding output# 对于线性变换,将每个单词嵌入向量的维度除以\sqrt{d_model},从而缩小输出的范围;# 'prj': multiply (\sqrt{d_model} ^ -1) to linear projection output# 'none': no multiplicationassertscale_emb_or_prjin['emb','prj','none']# 如果 trg_emb_prj_weight_sharing 为真,则 scale_emb 将会根据 scale_emb_or_prj 的取值来决定是否对词嵌入层进行缩放;self.scale_prj 则是根据 scale_emb_or_prj 的取值来决定是否对线性映射层进行缩放。scale_emb=(scale_emb_or_prj=='emb')iftrg_emb_prj_weight_sharingelseFalseself.scale_prj=(scale_emb_or_prj=='prj')iftrg_emb_prj_weight_sharingelseFalseself.d_model=d_modelself.encoder=Encoder(n_src_vocab=n_src_vocab,n_position=n_position,d_word_vec=d_word_vec,d_model=d_model,d_inner=d_inner,n_layers=n_layers,n_head=n_head,d_k=d_k,d_v=d_v,pad_idx=src_pad_idx,dropout=dropout,scale_emb=scale_emb)self.decoder=Decoder(n_trg_vocab=n_trg_vocab,n_position=n_position,d_word_vec=d_word_vec,d_model=d_model,d_inner=d_inner,n_layers=n_layers,n_head=n_head,d_k=d_k,d_v=d_v,pad_idx=trg_pad_idx,dropout=dropout,scale_emb=scale_emb)# 通过线性映射层将解码器输出映射到目标语言词汇表大小self.trg_word_prj=nn.Linear(d_model,n_trg_vocab,bias=False)# self.parameters()返回模型所有参数forpinself.parameters():# 对于每一个参数 p,通过判断其维度大小是否大于 1,来确定是否需要进行初始化操作。# 一般来说,只有权重矩阵等具有多个元素的参数才需要进行初始化。ifp.dim()>1:# Xavier Uniform 初始化。它的目的是根据输入和输出维度来初始化参数的取值范围,使得网络层在前向传播和反向传播时能够更好地保持梯度稳定,避免梯度消失或爆炸的问题。# Xavier Uniform 初始化会将参数 p 中的数值从一个均匀分布中采样,采样范围的上下界根据输入和输出维度进行计算。这样可以确保参数的初始化值既不过大也不过小,有利于模型的训练和优化过程。nn.init.xavier_uniform_(p)# 要使用残差连接,需要保证各个模块的输入和输出维度一致,以便进行加法运算。# 确保模型中各个模块输出的维度与 d_model 相等,以便正确地使用残差连接。如果维度不一致,就会抛出异常信息,提醒开发者修改模型设计assertd_model==d_word_vec, \
'To facilitate the residual connections, \
the dimensions of all module outputs shall be the same.'# 实现目标词嵌入层(target word embedding)和最后一个全连接层(dense layer)之间的权重共享iftrg_emb_prj_weight_sharing:# Share the weight between target word embedding & last dense layer# 将目标词嵌入层的权重设置为解码器(decoder)中目标词嵌入层的权重self.trg_word_prj.weight=self.decoder.trg_word_emb.weight# 源语言和目标语言词嵌入层之间的权重共享ifemb_src_trg_weight_sharing:# 将编码器(encoder)中源语言词嵌入层的权重设置为解码器中目标语言词嵌入层的权重self.encoder.src_word_emb.weight=self.decoder.trg_word_emb.weightdefforward(self,src_seq,trg_seq):src_mask=get_pad_mask(src_seq,self.src_pad_idx)trg_mask=get_pad_mask(trg_seq,self.trg_pad_idx)&get_subsequent_mask(trg_seq)enc_output,*_=self.encoder(src_seq,src_mask)dec_output,*_=self.decoder(trg_seq,trg_mask,enc_output,src_mask)seq_logit=self.trg_word_prj(dec_output)ifself.scale_prj:seq_logit*=self.d_model**-0.5# seq_logit 的形状为 (batch_size, seq_len, vocab_size),其中 batch_size 表示批量大小,seq_len 表示序列长度,vocab_size 表示词汇表大小# 调用 view 函数对 seq_logit 进行形状变换,将其变成一个二维的张量。第一维表示所有序列的总数,也就是 batch_size * seq_len;第二维表示每个序列可能的输出单词数量,即 vocab_size。returnseq_logit.view(-1,seq_logit.size(2))