


1.redis cluster原理概念
1.1.cluster架构概念
redis cluster是redis的分布式解决方案,在3.0版本正式推出,如果公司的redis是2.x版本,就需要升级了
redis哨兵集群不足之处:
- 资源利用率低,只有一台主库对外提供服务
假如哨兵模式有3个节点,只有其中一个节点对外提供服务,其他两个节点都处于备份状态,这样就会造成资源的浪费,redis将数据都写在内存中,只有主节点工作,那么内存只有主节点上的那点内存,从节点上的内存也就造成了浪费 - 主库压力比较大,性能有瓶颈
只有主库在工作,所有的写都是主节点完成,这样就会造成主节点的压力比较大,从节点几乎没有压力 - 哨兵的不足之处就在于集群不是分布式存储,只是单节点去处理,如果集群时分布式存储,那么单点和压力的问题也就解决了
redis cluster适用场景:
- 当redis遇到单机、内存、并发、流量等瓶颈时,可以采用cluster架构方案达到负载均衡的目的
redis cluster之前的分布式方案:
- 客户端分区方案,优点分区逻辑可控,缺点是需要自己处理数据路由,高可用和故障转移等。
- 代理方案,优点是简化客户端分布式逻辑和升级维护便利,缺点加重架构部署和性能消耗。
redis cluster的数据分布方式: 所有分布式数据库首先要解决把整个数据库集安装分区规则映射到多个节点的问题,也就是把数据集划分到多个节点上,redis cluster采用哈希分片规则,这样就能保证每个节点存储的数据量大致相同
redis cluster原理:
redis cluster会将数据自动进行分片,然后通过hash算法均匀的存放在集群中的每个节点,cluster架构在每台机器上都有一个或多个主节点和从节点,当一个节点上的master挂掉,会自动将这台机器上的某个slave切换为master
cluster架构的redis集群,可以横向扩容,由于cluster是分布式架构,单个机器的内存是32G,那么10个节点就是320G内存的存储
cluster架构数据分片是由hash来进行分配的,均匀的分散在各个节点
cluster架构槽位概念:每个cluster集群都有16384个槽位,这个槽位就是用来存储hash分配的分片,每一个槽位都需要分配到位,有一个槽位没有分配,整个集群都将无法使用,每一个槽位都有一个序号,它们不是顺序存放的,而是在节点一上比如有10-20序列槽位,节点二上有60-70序列的槽位,这两个节点都是10个槽位,序号不一定要顺序,但是数量一定要差不多,允许2%的误差
cluster集群架构图
通过hash分配数据分片到不同的redis主机
在应用端配置redis cluster地址时需要将所有节点的ip和端口都添加上
使用cluster集群创建的key,在哪个节点上创建的只能是自身节点可以查到数据,其他节点看不到
1.2.redis cluster不合理的架构图
不太合理的架构图
cluster集群每个机器上都有多个master和slave,如果master节点的数据备份都在自己主机的slave上,那么当服务器1坏掉后,这个机器上的数据就丢失了,数据丢失整个应用就崩溃了
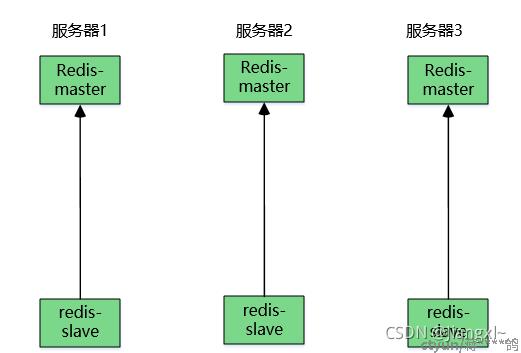
合理的架构图
每个节点slave都存放在别的主机,即使当前主机挂掉,另一台直接还原数据即可
1.3.部署一个cluster三主三从集群具体步骤
1.在三台主机上部署redis,分别启动两个不同端口的redis,一个主库一个从库
2.配置cluster集群自动发现,使得集群中各个主机都知道其他主机上的redis节点
3.配置集群hash分配槽位,有了槽位才可以存储数据
4.使用cluster replicate使多出来的三个主库变成从库,这样就实现了三主三从
1.4.环境准备
| IP | 主机名 | 端口号 | 节点 |
| 192.168.81.210 | redis-1 | 6380 | master |
| 192.168.81.210 | redis-1 | 6381 |
slave—>redis-2 |
| 192.168.81.220 | redis-2 | 6380 | master |
| 192.168.81.220 | redis-2 | 6381 |
slave—>redis-3 |
| 192.168.81.230 | redis-3 | 6380 | master |
| 192.168.81.230 | redis-3 | 6381 |
slave—>redis-1 |
2.部署redis cluster节点
搭建一个三主三从的redis cluster集群
配置文件中的bind也可以写成如下样子,自动识别bind地址
bind $(ifconfig | awk 'NR==2{print $2}')
配置文件含义
port 6380 //redis端口daemonize yes //后台启动logfile /data/redis_cluster/redis_6380/logs/redis_6380.log //日志路径pidfile /data/redis_cluster/redis_6380/pid/redis_6380.log //pid存放路径dbfilename "redis_6380.rdb" //数据文件名称dir /data/redis_cluster/redis_6380/data //数据文件存放目录cluster-enabled yes //开启集群模式cluster-config-file node_6380.conf //集群数据文件路径,保存集群信息的文件cluster-node-timeout 15000 //集群故障转移时间,多长时间无响应就切换
环境准备
| IP | 角色 | 端口号 |
| 192.168.81.210 | master | 6380 |
| 192.168.81.210 |
slave |
6381 |
| 192.168.81.220 | master | 6380 |
| 192.168.81.220 |
slave |
6381 |
| 192.168.81.230 | master | 6380 |
| 192.168.81.230 |
slave |
6381 |
2.1.redis-1配置
配置文件自动识别bind地址
1.创建节点配置文件路径[root@redis-1 ~]# mkdir -p /data/redis_cluster/redis_{6380,6381}/{conf,data,logs,pid}
2.准备两个配置文件一个6380,一个6381[root@redis-1 ~]# cat > /data/redis_cluster/redis_6380/conf/redis_6380.conf <<EOFbind $(ifconfig | awk 'NR==2{print $2}')port 6380 daemonize yeslogfile /data/redis_cluster/redis_6380/logs/redis_6380.logpidfile /data/redis_cluster/redis_6380/pid/redis_6380.logdbfilename "redis_6380.rdb"dir /data/redis_cluster/redis_6380/datacluster-enabled yescluster-config-file node_6380.confcluster-node-timeout 15000EOF[root@redis-1 ~]# cat > /data/redis_cluster/redis_6381/conf/redis_6381.conf <<EOFbind $(ifconfig | awk 'NR==2{print $2}')port 6381 daemonize yeslogfile /data/redis_cluster/redis_6381/logs/redis_6381.logpidfile /data/redis_cluster/redis_6381/pid/redis_6381.logdbfilename "redis_6381.rdb"dir /data/redis_cluster/redis_6381/datacluster-enabled yescluster-config-file node_6381.confcluster-node-timeout 15000EOF
3.启动rediscluster[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6380/conf/redis_6380.conf[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6381/conf/redis_6381.conf
4.查看进程和端口[root@redis-1 ~]# ps aux | grep redis[root@redis-1 ~]# netstat -lnpt | grep redis
2.2.redis-2配置
配置文件自动识别bind地址
[root@redis-2 ~]# mkdir -p /data/redis_cluster/redis_{6380,6381}/{conf,data,logs,pid}[root@redis-2 ~]# cat > /data/redis_cluster/redis_6380/conf/redis_6380.conf <<EOFbind $(ifconfig | awk 'NR==2{print $2}')port 6380 daemonize yeslogfile /data/redis_cluster/redis_6380/logs/redis_6380.logpidfile /data/redis_cluster/redis_6380/pid/redis_6380.logdbfilename "redis_6380.rdb"dir /data/redis_cluster/redis_6380/datacluster-enabled yescluster-config-file node_6380.confcluster-node-timeout 15000EOF[root@redis-2 ~]# cat > /data/redis_cluster/redis_6381/conf/redis_6381.conf <<EOFbind $(ifconfig | awk 'NR==2{print $2}')port 6381 daemonize yeslogfile /data/redis_cluster/redis_6381/logs/redis_6381.logpidfile /data/redis_cluster/redis_6381/pid/redis_6381.logdbfilename "redis_6381.rdb"dir /data/redis_cluster/redis_6381/datacluster-enabled yescluster-config-file node_6381.confcluster-node-timeout 15000EOF[root@redis-2 ~]# [root@redis-2 ~]# redis-server /data/redis_cluster/redis_6380/conf/redis_6380.conf[root@redis-2 ~]# redis-server /data/redis_cluster/redis_6381/conf/redis_6381.conf[root@redis-2 ~]# [root@redis-2 ~]# ps aux | grep redis[root@redis-2 ~]# netstat -lnpt | grep redis
2.3.redis-3配置
手动填写bind ip地址
[root@redis-3 ~]# mkdir -p /data/redis_cluster/redis_{6380,6381}/{conf,data,logs,pid}[root@redis-3 ~]# cat > /data/redis_cluster/redis_6380/conf/redis_6380.conf <<EOFbind 192.168.81.230port 6380 daemonize yeslogfile /data/redis_cluster/redis_6380/logs/redis_6380.logpidfile /data/redis_cluster/redis_6380/pid/redis_6380.logdbfilename "redis_6380.rdb"dir /data/redis_cluster/redis_6380/datacluster-enabled yescluster-config-file node_6380.confcluster-node-timeout 15000EOF[root@redis-3 ~]# cat > /data/redis_cluster/redis_6381/conf/redis_6381.conf <<EOFbind 192.168.81.230port 6381 daemonize yeslogfile /data/redis_cluster/redis_6381/logs/redis_6381.logpidfile /data/redis_cluster/redis_6381/pid/redis_6381.logdbfilename "redis_6381.rdb"dir /data/redis_cluster/redis_6381/datacluster-enabled yescluster-config-file node_6381.confcluster-node-timeout 15000EOF[root@redis-3 ~]# [root@redis-3 ~]# redis-server /data/redis_cluster/redis_6380/conf/redis_6380.conf[root@redis-3 ~]# redis-server /data/redis_cluster/redis_6381/conf/redis_6381.conf[root@redis-3 ~]# [root@redis-3 ~]# ps aux | grep redis[root@redis-3 ~]# netstat -lnpt | grep redis
2.4.查看redis cluster进程
每个节点启动了cluster后,进程名上会增加cluster
每个redis节点会开放两个端口,服务端口6380,集群通信端口16380(在服务端口基础上增加10000)
4.查看进程[root@redis-1 ~]# ps aux | grep redisavahi 6935 0.0 0.1 62272 2296 ? Ss 1月29 0:02 avahi-daemon: running [redis-1.local]root 31846 0.3 0.5 141068 10800 ? Ssl 1月30 10:13 redis-server 192.168.81.210:6379root 31859 0.3 0.4 136972 7744 ? Ssl 1月30 11:43 redis-sentinel 192.168.81.210:26379 [sentinel]root 78126 0.2 0.4 136972 7584 ? Ssl 14:40 0:00 redis-server 192.168.81.210:6380 [cluster]root 78130 0.4 0.4 136972 7588 ? Ssl 14:40 0:00 redis-server 192.168.81.210:6381 [cluster]root 78136 0.0 0.0 112728 988 pts/2 R 14:40 0:00 grep --color=auto redis[root@redis-1 ~]# netstat -lnpt | grep redistcp 0 0 192.168.81.210:26379 0.0.0.0:* LISTEN 31859/redis-sentine tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 31846/redis-server tcp 0 0 192.168.81.210:6379 0.0.0.0:* LISTEN 31846/redis-server tcp 0 0 192.168.81.210:6380 0.0.0.0:* LISTEN 78126/redis-server tcp 0 0 192.168.81.210:6381 0.0.0.0:* LISTEN 78130/redis-server tcp 0 0 192.168.81.210:16380 0.0.0.0:* LISTEN 78126/redis-server tcp 0 0 192.168.81.210:16381 0.0.0.0:* LISTEN 78130/redis-server
2.5.查看集群信息文件内容
集群模式的redis除了原有的配置文件之外又增加了一个集群配置文件,当集群内节点信息发生变化时,如添加节点,节点下线,故障转移等,节点都会自动保存集群状态到配置文件,redis自动维护集群配置文件,不需要手动修改防止节点重启时产生错乱
在集群启动后会生成一个数据文件,这个数据文件其实保存的就是集群的信息,在没有配置集群互相发现时,单个节点只保存自己的集群信息,文件中有节点id信息,每个节点的id都是唯一的
当配置了互相发现了配置文件中就会增加所有节点的信息
[root@redis-1 ~]# cat /data/redis_cluster/redis_6380/data/node_6380.conf b7748aedb5e51921db67c54e0c6263ed28043948 :0 myself,master - 0 0 0 connectedvars currentEpoch 0 lastVoteEpoch 0
[root@redis-1 ~]# cat /data/redis_cluster/redis_6381/data/node_6381.conf 1ec79d498ecf9f272373740e402398e4c69cacb2 :0 myself,master - 0 0 0 connectedvars currentEpoch 0 lastVoteEpoch 0
也可以登录redis进行查看
[root@redis-1 ~]# for i in {1..3}dofor j in {0..1}doecho "192.168.81.2${i}0---638${j}"redis-cli -h 192.168.81.2${i}0 -p 638${j} cluster nodesdonedone192.168.81.210---6380b7748aedb5e51921db67c54e0c6263ed28043948 :6380 myself,master - 0 0 0 connected192.168.81.210---63811ec79d498ecf9f272373740e402398e4c69cacb2 :6381 myself,master - 0 0 0 connected192.168.81.220---638087ea6206f3db1dbaa49522bed15aed6f3bf16e22 :6380 myself,master - 0 0 0 connected192.168.81.220---6381bedd9482b08a06b0678fba01bb1c24165e56636c :6381 myself,master - 0 0 0 connected192.168.81.230---6380759ad5659d449dc97066480e1b7efbc10b34461d :6380 myself,master - 0 0 0 connected192.168.81.230---6381a2c95db5d6f9f288e6768c8d00e90fb7631f3021 :6381 myself,master - 0 0 0 connected
3.配置cluster集群互相发现
3.1.互相发现概念
cluster集群互相发现只需要在一个节点上配置,所有节点都会接收到配置信息并自动加入到配置文件中
例如在redis-1的6380节点上增加了本机的6381端口和redis-2的6380端口,这时在redis-2上查看6380的配置里面就能看到6380节点和redis-1的6380以及6381节点信息,这时redis-3的两个节点还有本机的6381则还是一条,因为他们没有加入
在哪个节点添加的发现另一个节点的信息,那么当前这个节点就已经加入到了集群中
其实只要在集群的任意一个节点配置,集群的所有节点都会自动添加配置
下面演示一个在reids-1上添加几个节点,在redis-2上看是否自动配置
1.在redis-1的6380节点上增加本机的6381和redis-2的6380端口[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380192.168.81.210:6380> CLUSTER MEET 192.168.81.210 6381OK192.168.81.210:6380> CLUSTER MEET 192.168.81.220 6380OK
2.查看redis-2的6380集群配置文件[root@redis-2 ~]# cat /data/redis_cluster/redis_6380/data/node_6380.conf 1ec79d498ecf9f272373740e402398e4c69cacb2 192.168.81.210:6381 master - 0 1612169525469 1 connectedb7748aedb5e51921db67c54e0c6263ed28043948 192.168.81.210:6380 master - 0 1612169525369 0 connected87ea6206f3db1dbaa49522bed15aed6f3bf16e22 192.168.81.220:6380 myself,master - 0 0 2 connectedvars currentEpoch 2 lastVoteEpoch 0很明显的看出已经将redis-1的6380和6381以及redis-2本机的6380端口都加到了集群配置文件中
3.查看redis-2的6381节点集群配置文件[root@redis-2 ~]# cat /data/redis_cluster/redis_6381/data/node_6381.conf bedd9482b08a06b0678fba01bb1c24165e56636c :0 myself,master - 0 0 0 connectedvars currentEpoch 0 lastVoteEpoch 0
3.2.将集群的所有节点进行互相发现
在集群的任意一个节点配置就可以
1.配置互相发现[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380192.168.81.210:6380> CLUSTER MEET 192.168.81.210 6381OK192.168.81.210:6380> CLUSTER MEET 192.168.81.220 6380OK192.168.81.210:6380> CLUSTER MEET 192.168.81.220 6381OK192.168.81.210:6380> CLUSTER MEET 192.168.81.230 6380OK192.168.81.210:6380> CLUSTER MEET 192.168.81.230 6381OK
2.查看配置文件是否增加,所有节点的配置文件都会生成[root@redis-1 ~]# cat /data/redis_cluster/redis_6381/data/node_6381.conf 759ad5659d449dc97066480e1b7efbc10b34461d 192.168.81.230:6380 master - 0 1612169812886 4 connected1ec79d498ecf9f272373740e402398e4c69cacb2 192.168.81.210:6381 myself,master - 0 0 1 connected87ea6206f3db1dbaa49522bed15aed6f3bf16e22 192.168.81.220:6380 master - 0 1612169814797 2 connectedbedd9482b08a06b0678fba01bb1c24165e56636c 192.168.81.220:6381 master - 0 1612169815806 0 connecteda2c95db5d6f9f288e6768c8d00e90fb7631f3021 192.168.81.230:6381 master - 0 1612169815708 5 connectedb7748aedb5e51921db67c54e0c6263ed28043948 192.168.81.210:6380 master - 0 1612169816814 3 connectedvars currentEpoch 5 lastVoteEpoch 0
4.cluster集群分配操作
4.1.redis cluster通讯流程
集群内消息传递是同步的
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障灯状态信息,redis集群采用gossip协议,gossip协议工作原理就是节点彼此不断交换信息,一段时间后所有的节点偶会指定集群完整信息,这种方式类似于流言传播,因此只需要在一台节点配置集群信息所有节点都能收到信息
通信过程:
1.集群中的每一个节点都会单独开辟一个tcp通道用于节点之间彼此通信,通信端口在基础端口上增加10000
2.每个节点在固定周期内通过特定规则选择结构节点发送ping消息
3.接收到ping消息的节点用pong作为消息响应,集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点的信息,也可能知道部分节点信息,只要这些节点彼此可以正常通信,最终他们就会达成一致的状态,当节点出现故障,新节点加入,主从角色变化等,彼此之间不断发生ping/pong消息,最终达成同步的模板
通讯消息类型:gossip,信息交换,常见的消息分为ping、pong、meet、fail
通讯示意图
没有分配槽位时集群的状态,所有节点执行cluster info,cluster_state都是fail,fail状态表示集群不可用,没有分配槽位,cluster_slots都会显示0
4.2.手动配置集群槽位
每个cluster集群都有16384个槽位,我们有三台机器,想要手动分配平均就需要使用16384除3
redis-1 0-5461
redis-2 5462-10922
redis-3 10923-16383
分配槽位语法格式(交互式):CLUSTER ADDSLOTS 0 5461
分配槽位语法:redis-cli -h 192.168.81.210 -p 6380 cluster addslots {0…5461}
删除槽位分配语法格式: redis-cli -h 192.168.81.210 -p 6380 cluster delslots {5463…10921}
1.配置手动分配槽位[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 cluster addslots {0..5461}OK[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6380 cluster addslots {5462..10922}OK[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6380 cluster addslots {10923..16383}OK
2.查看集群状态,到目前为止集群已经是可用的了[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6380 cluster infocluster_state:okcluster_slots_assigned:16384cluster_slots_ok:16384cluster_slots_pfail:0cluster_slots_fail:0cluster_known_nodes:6cluster_size:3cluster_current_epoch:5cluster_my_epoch:2cluster_stats_messages_sent:170143cluster_stats_messages_received:170142
3.查看nodes文件内容[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6380 cluster nodesa2c95db5d6f9f288e6768c8d00e90fb7631f3021 192.168.81.230:6381 master - 0 1612251539412 5 connectedbedd9482b08a06b0678fba01bb1c24165e56636c 192.168.81.220:6381 master - 0 1612251538402 0 connected87ea6206f3db1dbaa49522bed15aed6f3bf16e22 192.168.81.220:6380 myself,master - 0 0 2 connected 5462-10922b7748aedb5e51921db67c54e0c6263ed28043948 192.168.81.210:6380 master - 0 1612251540418 3 connected 0-54611ec79d498ecf9f272373740e402398e4c69cacb2 192.168.81.210:6381 master - 0 1612251537394 1 connected759ad5659d449dc97066480e1b7efbc10b34461d 192.168.81.230:6380 master - 0 1612251536386 4 connected 10923-16383
4.3.创建key验证集群是否可用
不是所有的key都能插入,有的key插入的时候就提示说你应该去192.168.81.230上插入,这时手动到对应的主机上执行就可以插入,这是由于cluster集群槽位都是分布在不同节点的,每次新建一个key,都会通过hash算法均匀的在不同节点去创建
不同节点创建的key只由自己节点可以看到自己创建的数据
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380192.168.81.210:6380> set k1 v1(error) MOVED 12706 192.168.81.230:6380192.168.81.210:6380> set k2 v2OK192.168.81.210:6380> set k3 v3OK192.168.81.210:6380> set k4 v4(error) MOVED 8455 192.168.81.220:6380192.168.81.210:6380> set k5 v5(error) MOVED 12582 192.168.81.230:6380192.168.81.210:6380> set k6 v6OK
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6380192.168.81.230:6380> set k1 v1OK192.168.81.230:6380> set k5 v5OK
[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6380192.168.81.220:6380> set k4 v4OK
4.4.ASK路由解决key创建提示去别的主机创建
可以通过ASK路由解决创建key时提示去别的主机进行创建
ASK路由创建key时,如果可以在本机直接创建就会执行创建key的命令,如果不能再本机执行,他会根据提示的主机去对应主机上创建key
ASK路径的特性:每次通过hash在指定主机上创建了key后就会停留在这个主机上
只需要执行redis-cli时加上-c参数即可
[root@redis-1 ~]# redis-cli -c -h 192.168.81.210 -p 6380192.168.81.210:6380> set k8 v8-> Redirected to slot [8331] located at 192.168.81.220:6380OK192.168.81.220:6380> set k9 v9-> Redirected to slot [12458] located at 192.168.81.230:6380OK192.168.81.230:6380> set k10 v10OK192.168.81.230:6380> set k11 v11OK192.168.81.230:6380> set k12 v12-> Redirected to slot [2863] located at 192.168.81.210:6380OK192.168.81.210:6380> set k13 v13-> Redirected to slot [6926] located at 192.168.81.220:6380OK192.168.81.220:6380> set k14 v14-> Redirected to slot [11241] located at 192.168.81.230:6380OK
很清楚的展示了在哪台主机上创建
4.5.验证hash分配是否均匀
cluster架构是分布式的,创建的key会通过hash将数据均已的分布在每台主机的槽位上
1.插入一千条数据,查看三个节点是否分配均已插入的时候使用-c,自动在某个节点上插入数据[root@redis-1 ~]# for i in {1..1000}doredis-cli -c -h 192.168.81.210 -p 6380 set key_${i} value_${i}done
2.查看每个节点的数据量,可以看到非常均匀,误差只有一点点[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380192.168.81.210:6380> DBSIZE(integer) 339
[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6380192.168.81.220:6380> DBSIZE(integer) 339
[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6380192.168.81.230:6380> DBSIZE(integer) 336192.168.81.230:6380> exit
5.配置cluster集群三主三从高可用
实现步骤:
1.使用cluster replicate将主机的6381redis节点交叉成为别的主机6380节点的从库
2.查看集群状态即可
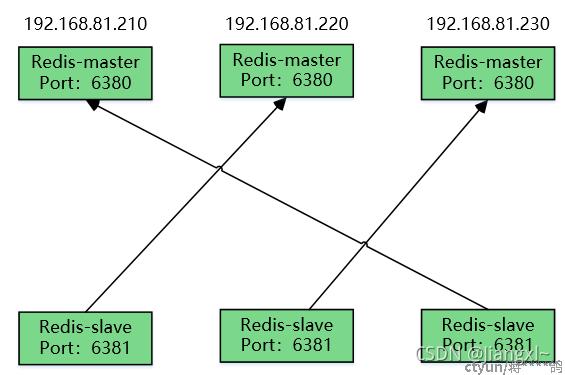
5.1.三主三从架构图
三主三从是redis cluster最常用的架构,每个从节点复制的都不是本机主库的数据,而是其他节点主库的数据,这样即使某一台主机坏掉了,从节点备份还是在其他机器上,这样就做到了高可用,三主三从架构允许最多坏一台主机
三主三从我们采用交叉复制架构类型,这样可以做到最多坏一台主机集群还是正常可以用的,如果每台主机的6381节点都是6380节点的备份,那么这台机器坏了,集群就不可用了,因此想要做到高可用,就采用交叉复制
交叉复制的架构,当主节点挂掉了,主节点备份的从节点就会自动成为主节点,当主节点上线后
每个节点的6380端口都是主库,6381端口都是从库
从节点对应的主节点关系:
redis-1的6381从节点对应的主节点是redis-2的6380主节点
redis-2的6381从节点对应的主节点是redis-3的6380主节点
redis-3的6381从节点对应的主节点是redis-1的6380主节点
5.2.将每一个节点都配置rdb持久化
在所有节点端口的配置文件中加上rdb持久化配置即可
vim /data/redis_cluster/redis_6380/conf/redis_6380.conf bind 192.168.81.210port 6380daemonize yeslogfile /data/redis_cluster/redis_6380/logs/redis_6380.logpidfile /data/redis_cluster/redis_6380/pid/redis_6380.logdbfilename "redis_6380.rdb"dir /data/redis_cluster/redis_6380/datacluster-enabled yescluster-config-file node_6380.confcluster-node-timeout 15000#持久化配置save 60 10000save 300 10save 900 1
重启redisredis-cli -h 192.168.81.210 -p 6380 shutdownredis-server /data/redis_cluster/redis_6380/conf/redis_6380.conf
5.3.配置三主三从
配置三主三从规范操作步骤
1.将集群信息粘到txt中,只保留下6380端口信息
2.配置命令在txt中准备好在复制到命令行
主节点我们已经有了,目前6个节点全是主节点,我们需要把所有主机的6381的主节点配置成从节点
从节点对应的主节点关系:
redis-1的6381从节点对应的主节点是redis-2的6380主节点
redis-2的6381从节点对应的主节点是redis-3的6380主节点
redis-3的6381从节点对应的主节点是redis-1的6380主节点
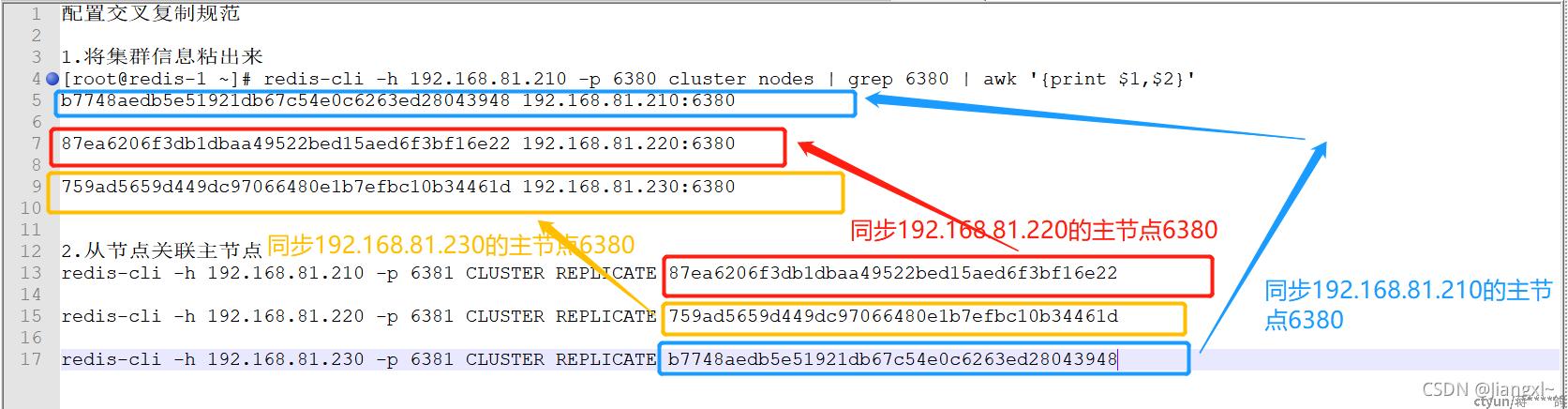
CLUSTER REPLICATE 是配置当前节点成为某个主节点的从节点,replicate命令其实就相当于执行了slaveof,同步了某一个主库,并且在日志中查看到的就是主从同步的过程
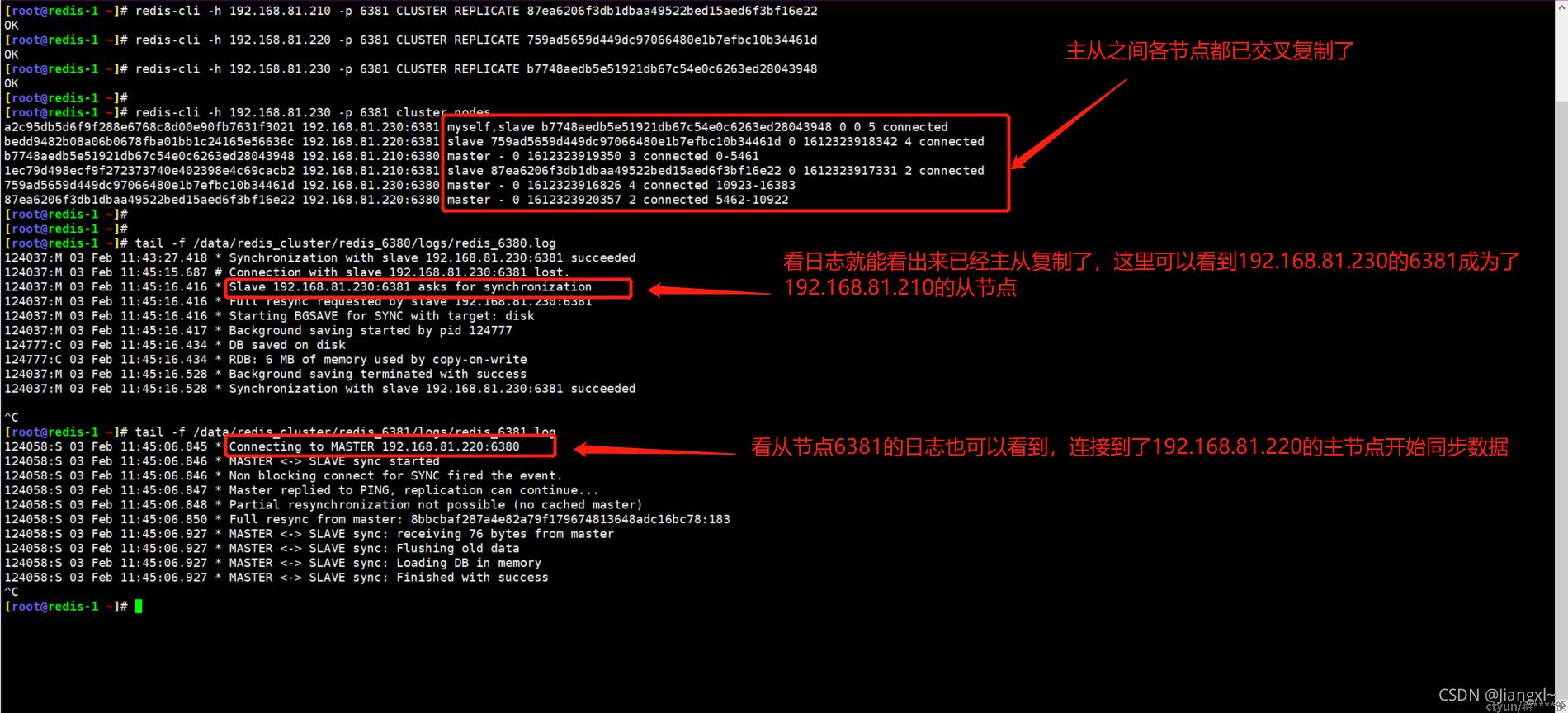
1.配置从节点连接主节点,交叉式复制[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6381 CLUSTER REPLICATE 87ea6206f3db1dbaa49522bed15aed6f3bf16e22OK[root@redis-1 ~]# redis-cli -h 192.168.81.220 -p 6381 CLUSTER REPLICATE 759ad5659d449dc97066480e1b7efbc10b34461dOK[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6381 CLUSTER REPLICATE b7748aedb5e51921db67c54e0c6263ed28043948OK
2.查看集群节点信息,发现已经是三主三从了[root@redis-1 ~]# redis-cli -h 192.168.81.230 -p 6381 cluster nodesa2c95db5d6f9f288e6768c8d00e90fb7631f3021 192.168.81.230:6381 myself,slave b7748aedb5e51921db67c54e0c6263ed28043948 0 0 5 connectedbedd9482b08a06b0678fba01bb1c24165e56636c 192.168.81.220:6381 slave 759ad5659d449dc97066480e1b7efbc10b34461d 0 1612323918342 4 connectedb7748aedb5e51921db67c54e0c6263ed28043948 192.168.81.210:6380 master - 0 1612323919350 3 connected 0-54611ec79d498ecf9f272373740e402398e4c69cacb2 192.168.81.210:6381 slave 87ea6206f3db1dbaa49522bed15aed6f3bf16e22 0 1612323917331 2 connected759ad5659d449dc97066480e1b7efbc10b34461d 192.168.81.230:6380 master - 0 1612323916826 4 connected 10923-1638387ea6206f3db1dbaa49522bed15aed6f3bf16e22 192.168.81.220:6380 master - 0 1612323920357 2 connected 5462-10922
配置完主从,可以看到集群中已经有slave节点了,并且也是交叉复制的
打开主库的日志可以看到哪个从库同步了主库的日志,打开从库的日志可以看到同步了哪个主库的日志
5.3.模拟故障转移
三主三从架构允许最多坏一台主机,模拟将redis-1机器的主库6380挂掉,查看集群间的故障迁移
思路:
1.将redis-1的6380主库关掉,查看集群状态信息是否将slave自动切换为master
2.当master上线后会变成一个节点的从库
3.将master通过cluster failover重新成为主库
5.1.模拟坏掉redis-1的主库并验证就能是否可用
1.挂掉redis-1的主库[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 shutdown
2.查看日志先是由于主库挂了状态变成fail,当从库变成主库后,状态再次变为ok[root@redis-1 ~]# tail -f /data/redis_cluster/redis_6381/logs/redis_6381.log 124058:S 03 Feb 13:16:00.233 # Cluster state changed: fail124058:S 03 Feb 13:17:01.857 # Cluster state changed: ok
3.查看集群信息[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6381 cluster nodes
4.查看集群状态[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6381 cluster infocluster_state:okcluster_slots_assigned:16384cluster_slots_ok:16384cluster_slots_pfail:0cluster_slots_fail:0cluster_known_nodes:6cluster_size:3cluster_current_epoch:7cluster_my_epoch:2cluster_stats_messages_sent:18202cluster_stats_messages_received:17036
5.验证集群是否可用[root@redis-1 ~]# redis-cli -c -h 192.168.81.210 -p 6381 set k1111 v1111OK
当主库挂掉后,查看集群信息时会看到提示主库已经是fail状态,此时可用看到192.168.81.230机器的6381端口成为了master,192.168.81.230的6381端口是redis-1的从库,从库变为主库后,集群状态再次变为ok
5.3.2.redis-1节点的主库恢复目前的架构图
当主库重新加入集群后,架构图就变成了如下样子,主库的6380就成为了192.168.81.230的从库,而192.168.81.230的从库变成了192.168.81.210的主库
1.启动redis-1的6380主库[root@redis-1 ~]# redis-server /data/redis_cluster/redis_6380/conf/redis_6380.conf
2.查看集群信息[root@redis-1 ~]# redis-cli -c -h 192.168.81.210 -p 6380 cluster nodes1ec79d498ecf9f272373740e402398e4c69cacb2 192.168.81.210:6381 slave 87ea6206f3db1dbaa49522bed15aed6f3bf16e22 0 1612330250901 2 connectedb7748aedb5e51921db67c54e0c6263ed28043948 192.168.81.210:6380 myself,slave a2c95db5d6f9f288e6768c8d00e90fb7631f3021 0 0 3 connected759ad5659d449dc97066480e1b7efbc10b34461d 192.168.81.230:6380 master - 0 1612330255958 4 connected 10923-16383bedd9482b08a06b0678fba01bb1c24165e56636c 192.168.81.220:6381 slave 759ad5659d449dc97066480e1b7efbc10b34461d 0 1612330252920 4 connecteda2c95db5d6f9f288e6768c8d00e90fb7631f3021 192.168.81.230:6381 master - 0 1612330254941 7 connected 0-546187ea6206f3db1dbaa49522bed15aed6f3bf16e22 192.168.81.220:6380 master - 0 1612330256960 2 connected 5462-10922
5.3.3.将恢的主库重新变为主库
目前主库已经重新上线了,且现在是192.168.81.230的从库,而原来192.168.81.230的从库变成了现在192.168.81.210的主库,我们需要把关系切换回来,不能让一台机器上同时存在两台主库,每次故障处理后一定要把架构修改会原来的样子
从库切换成主库也特别简单,只需要执行一个cluster falover即可变为主库
cluster falover确实也类似于关系互换,简单理解就是原来的从变成了主,现在的主变成了从,这样一来就可以把故障恢复的主机重新变为主库
cluster falover原理:falover原理也就是先执行了slave no one,然后在对应的由主库变为从库的机器上执行了slave of
1.将故障上线的主库重新成为主库[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 192.168.81.210:6380> CLUSTER FAILOVEROK
2.查看集群信息,192.168.81.210的发现6380重新成为了master,192.168.81.230的从库变成了slave[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6381 cluster nodes759ad5659d449dc97066480e1b7efbc10b34461d 192.168.81.230:6380 master - 0 1612331847795 12 connected 10923-1638387ea6206f3db1dbaa49522bed15aed6f3bf16e22 192.168.81.220:6380 master - 0 1612331849307 11 connected 5462-10922b7748aedb5e51921db67c54e0c6263ed28043948 192.168.81.210:6380 master - 0 1612331848299 10 connected 0-5461bedd9482b08a06b0678fba01bb1c24165e56636c 192.168.81.220:6381 slave 759ad5659d449dc97066480e1b7efbc10b34461d 0 1612331850317 12 connecteda2c95db5d6f9f288e6768c8d00e90fb7631f3021 192.168.81.230:6381 slave b7748aedb5e51921db67c54e0c6263ed28043948 0 1612331851324 10 connected1ec79d498ecf9f272373740e402398e4c69cacb2 192.168.81.210:6381 myself,slave 87ea6206f3db1dbaa49522bed15aed6f3bf16e22 0 0 8 connected
查看集群信息,192.168.81.210的发现6380重新成为了master,192.168.81.230的从库变成了slave
到此cluster集群故障转移成功,集群状态一切正常
[root@redis-1 ~]# redis-cli -h 192.168.81.210 -p 6380 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:16
cluster_my_epoch:16
cluster_stats_messages_sent:18614
cluster_stats_messages_received:3497
6.redis cluster需要注意的几点
生产环境数据量可能非常大,当主库故障重新上线时,执行CLUSTER FAILOVER会很慢,因为这个就相当于是主从复制切换了,从库(刚上线的原来主库)关闭主从复制,主库(主库坏掉前的从库)同步从库(刚上线的原来主库)数据,然后从库(刚上线的原来主库)重新变为主库,这个时间一定要等,切记,千万不要因为慢在主库上(主库坏掉前的从库)同步手动进行了CLUSTER REPLICATE,这样确实会非常快的将主库(主库坏掉前的从库)重新变为从库,但也意味着这个节点数据全部丢失,因为clusert replicate相当于slaveof,slaveof会把自己的库清掉,这时候从库(刚上线的原来主库)在执行这CLUSTER FAILOVER同步着主库(主库坏掉前的从库)的数据,主库那边执行了replicate去同步从库(刚上线的原来主库),从而导致从库(刚上线的原来主库)还没有同步完主库(主库坏掉前的从库的数据),主库(主库坏掉前的从库)数据就丢失,整个集群还是可以用的,只是这个主库节点和从节点数据全部丢失,其他两个主库从库还能使用。
切记,当从库执行CLUSTER FAILOVER变为主库时,一定不要在主库上执行CLUSTER REPLICATE变为从库,虽然CLUSTER REPLICATE变为从库很快,但是会清空自己的数据去同步主库,这时主库还没有数据,因此就会导致数据全部丢失
CLUSTER FAILOVER:首先执行slave on one变为一个单独的节点,然后在要变成从库的节点上执行slaveof,只要从库执行完slave of,执行CLUSTER FAILOVER的节点就变成了主库
CLUSTER REPLICATE:只是执行了slaveof使自身成为从节点
当redis cluster主从正在同步时,不要执行cluster replicate,当主从复制完在执行,如何看主从是否复制完就要看节点的rdb文件是否是.tmp结尾的,如果是tmp结尾就说明他们正在同步数据,此时不要对集群做切换操作
小总结:
1.3.0版本以后推出集群功能
2.cluster集群有16384个槽位,误差在2%之间
3.槽位与序号顺序无关,重点是槽的数量
4.通过发现集群,与集群之间实现消息传递
5.配置文件无需手动修改,都是自动生成的
6.分配操作,必须将所有的槽位分配完毕
7.理清复制关系,画图,按照图形执行复制命令
8.当集群状态为ok时,集群才可以正常使用
9.反复测试,批量插入key,验证分配是否均匀
10.测试高可用,关闭任意主节点,集群是否自动转移
11.当主节点修复后,执行主从关系切换
12.做实验尽量贴合生成环境,尽量使用和生成环境一样数量的数据
13.评估和记录同步数据、故障转移完成的时间
14.向领导汇报时要有图、文档、实验环境,随时都可以演示
当应用需要连接redis cluster集群时要将所有节点都写在配置文件中
