



本文会介绍Kafka的底层数据存储形式、Kafka的高效索引设计及实际查询的过程。
1、segment
Kafka把Partition分成若干个segment,segment是Kafka的最小存储单元。在broker往分区里面写入数据时,如果达到segment上限,就关闭当前segment并打开一个新segment。没有关闭的segment叫做活跃片段,活跃片段永远不会被删除。(默认segment上限是1GB大小或者存活一周,所以如果配置了topic数据保存1天,但是5天了segment都没有1GB,则数据会存储5天。)
这样子设计相当于把整个partition这个『大文件』拆成了细碎小文件,避免了在一个大文件里面查找内容;而且要数据过期要删除的话可以直接删除整个文件,比删文件里面的内容更简单。
2、存储与查询
segment的真正存储会分成2份文件,一种是.index的索引文件,一种是.log的数据存储文件,成对出现。index保存offset的索引,log保存真正的数据内容。index文件的文件名是本文件的起始offset。
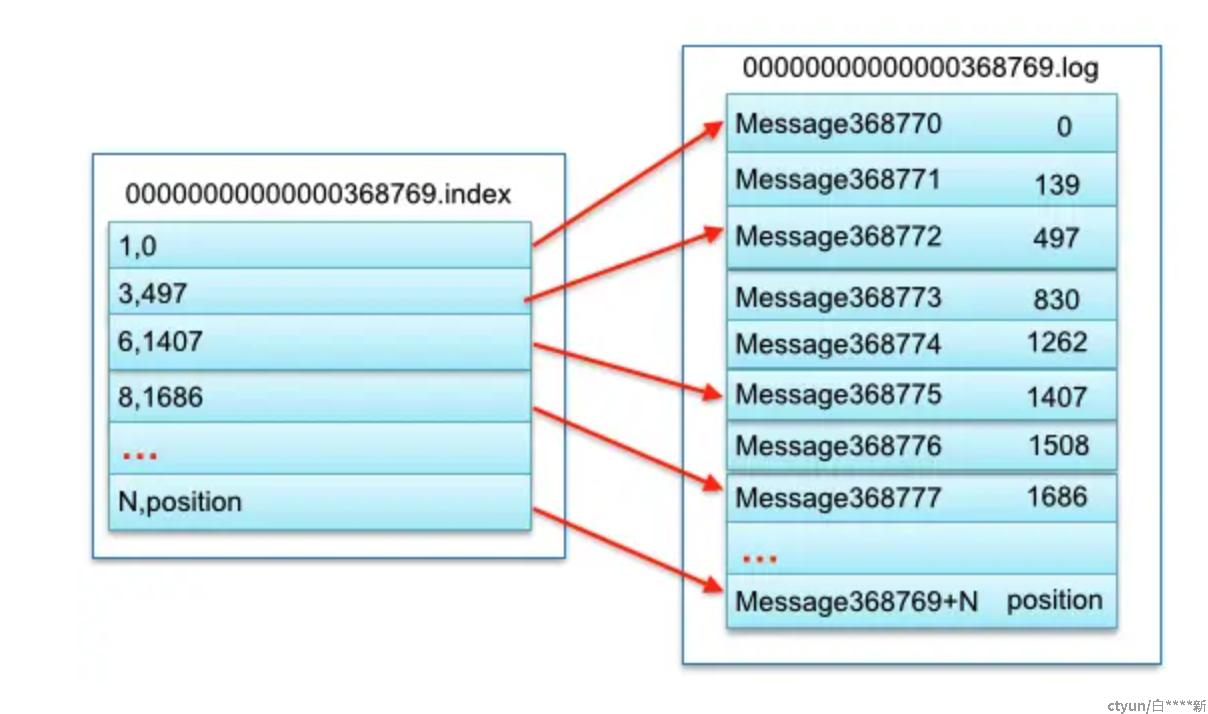
如上图,假设要查询offset=368775的数据,则命中了0000000000000368769这个index,查看到368775在这个index文件中位于第三位(368775 = 368769 + 6,刚好命中这个索引),对应到log文件的物理偏移量是1407。如果没有命中这个索引,则通过上个索引的文件偏移量再顺序查询。
3、索引设计
Kafka建立的这种索引也就是稀疏索引,即建立较少offset的索引用来较少内存使用。但是由于offset的索引建立得不完全,则查询命中可能消耗更多时间。
