


核心流程如下:
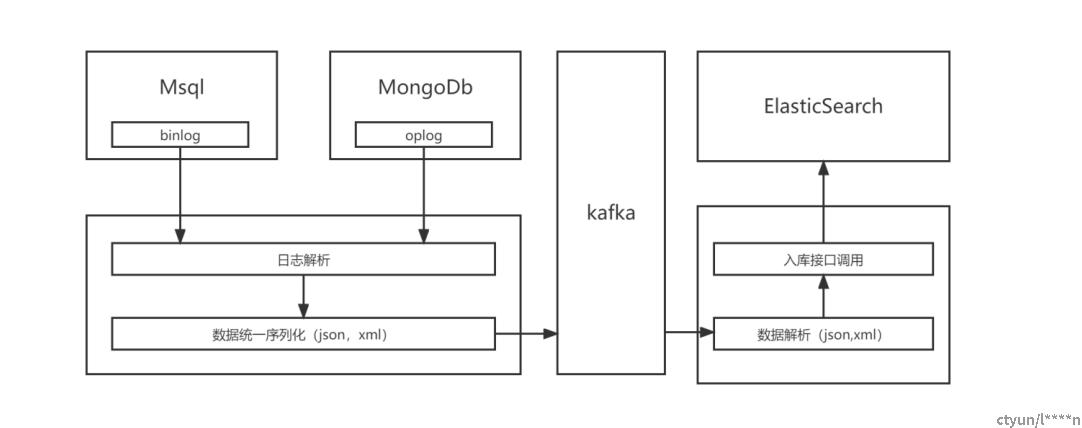
核心逻辑说明:
-
-
MySQL Binlog解析:
- 首先,从MySQL的二进制日志(Binlog)中解析出表名。这一步骤非常关键,因为我们只关注特定表的数据变更。
- 进一步,我们检查Binlog中的操作类型,如INSERT、UPDATE和DELETE,以确定是否是表数据的变动操作。这是因为我们只需要捕获数据的变更,而不关心查询操作。
- 如果操作是INSERT或DELETE,我们只需要关注受影响的数据行。对于UPDATE操作,我们需要记录新旧值的变化。
-
内存中数据组装:
- 从解析过的Binlog数据中,我们构建一个内存数据结构,通常是一个数据对象,其中包括表名、字段名、新旧值等信息。这允许我们在内存中轻松管理和处理数据。
-
数据序列化:
- 接下来,我们将内存中的数据对象序列化为特定的格式,通常为JSON或XML。这是为了将数据转化为一种可传输的结构,其中包含了表名、字段名和相应的新旧值。序列化的过程使数据适合通过网络传输。
-
数据传输到消息队列:
- 完成序列化后,数据通过TCP协议发送到消息队列,通常是Apache Kafka。消息队列用于持久性存储和传递数据,以确保数据不会丢失。
- 数据在消息队列中等待被消费者处理,这可以是其他系统、应用程序或服务,根据需要对数据进行进一步的分析或存储。
-
MongoDB Oplog解析:
- MongoDB的日志解析过程类似于MySQL,但我们使用的是MongoDB的操作日志(Oplog)来捕获数据变更。
- 同样,我们从Oplog中解析出表名,确定操作类型(INSERT、UPDATE、DELETE),并提取新旧值。
-
数据消费和存储:
- 消费者通过TCP协议从Kafka队列中拉取数据。消费者可以是各种类型的应用程序或服务,例如数据仓库、实时监控系统等。
- 数据可以通过HTTP协议将其写入Elasticsearch,以进行搜索、分析和可视化。Elasticsearch是一个强大的搜索引擎和分析工具,适用于处理大量数据。
以上流程描述了如何从MySQL和MongoDB中的日志解析数据,将其序列化为可传输的格式,并通过消息队列传递到其他系统或存储库中,以便进行后续处理、分析和查询。这种数据管道允许实时捕获和利用数据库中的变更,以满足各种用例和需求。
-
