


影响应用程序性能的一个重要因素是应用程序从处理器缓存和从内存子系统获取数据所消耗的时间。在激活了非统一内存访问架构(Non-Uniform Memory Access, NUMA)的多插槽系统(multi-socket system)中,本地内存延迟和交叉插槽内存延迟(cross-socket memory latencies)之间差别非常明显。除了延迟,带宽(bandwidth, b/w)也在决定性能时扮演重要角色。所以,检测这些延迟和带宽就是建立系统测试基线和性能分析非常重要的因素。Intel Memory Latency Checker(Intel MLC)是一个测试内存延迟和带宽的工具,并且可以测试延迟和带宽随着系统负载增加的变化。这个工具也提供了一些选项用于更好细粒度调查从特定处理器核心到缓存或内存的一系列选项的测试。
安装:
MLC支持在Linux和Windows系统上使用
1.Linux直接将工具包中二进制文件mlc放在对应系统中使用。
需要保证系统安装了glibc和lpthread库(GUI最大安装的centos系统默认支持);
运行mlc时需要使用root权限,因为工具在测试内存延迟和带宽时会修改通过修改MSR开启或关闭H/W Prefetch(硬件预取)功能。
需要加载msr模块 modprobe msr; 可使用 grep -i msr /boot/config-`uname-r`检查内核中是否加载此模块;
Q:如何读写MSR?
A:/dev/cpu/CPUNUM/msr提供了读写的接口,通过打开msr文件并寻找MSR编号位移,通过读或者写8字节块来实现寄存器访问。
2.Windows将工具包中mlc.exe和mlcdrv.sys拷贝到系统中使用。其中mlcdrv.sys驱动用于修改硬件预取的设置。
工具版本更新:
3.9a支持第三代至强处理器(IceLake)
旧版本工具包中包含两个二进制文件(mlc和mlc_avx512),mlc_avx512支持AVX512指令,mlc仅支持SSE2和AVX2指令。
3.7版本后仅提供一个支持SSE2 AVX2 AVX512指令的二进制文件mlc。默认运行mlc时都不会使用AVX512指令除非使用-Z参数指定。
新选项 --memory_bandwidth_scan,能够以1GB块的形式测量整个地址范围内的内存带宽。
硬件预取控制(HW Prefetcher Control):
在新型的Intel处理器上精确测试内存延迟是非常困难的,因为它有复杂的硬件预取器。Intel MLC在测试延迟时会自动禁用这些预取器,并且在测试完成后自动恢复预期器原状态。预期器控制是通过修改MSR实现,所以在Linux上需要root权限。在Windows平台,提供了签名的驱动用于访问MSR。
MLC测试内容:
当不输入任何参数直接运行时,工具会自动识别系统拓扑结构并测试以下4种类型:
1. A matrix of idle memory latencies for requests originating from each of the sockets and addressed to each of the available sockets

2.Peak memory b/w measured (assuming all accesses are to local memory) for requests with varying amounts of reads and writes
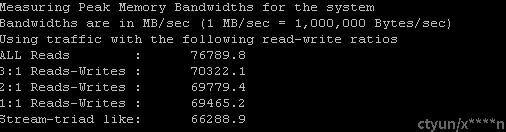
3.A matrix of memory b/w values for requests originating from each of the sockets and addressed to each of the available sockets

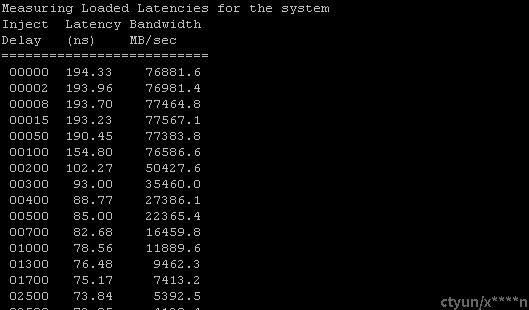
4.Latencies at different b/w points
测试时关闭透明大页功能(Transparent Huge Pages THP) 为何? 透明大页允许大页做动态的分配,而不是系统启动后就分配好。可能会影响性能
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
运行原理:
1.测试空闲内存延时:
通过创建一系列的dependent loads,工具开始计时并且运行负载,在运行百万次这些负载后停止计时,并且根据总时间 / 总负载数量得到一个负载执行的平均时间。这种方式可以用来测试多级缓存和内存的延时。
MLC工具本身不能知道一个负载击中了缓存还是内存,因为必须设置合适的buffer size。Buffer size大于L2 cache 小于L3 cache大小时,测试的延时就是L3缓存的延时。如果buffer size大于L3 cache大小,则负载会击中内存并因此测试内存延时。
2.测试内存带宽:
在多级缓存的系统中测试内存带宽,需要正确地设置buffer size。The total size of all the buffers used by the threads on a socket should exceed the total size of all the last level cache on that socket to be able to measure the memory bandwidth.
3.测试负载内存延时:
Intel MLC的一个主要功能是测量带宽需求增加时的延迟。为了加快实现,MLC创建了多个线程,线程数等于主机逻辑处理器数量减 1。这些线程用户生成负载(以下,这些线程被引用为负载生成线程或者带宽生成线程)。这个负载生成线程的主要功能是尽可能生成更多的内存引用。此时系统负载类似,剩下的一个CPU(也就是没有用于产生负载的CPU)运行了一个用于测量延迟的线程。这个线程通常运行在cpu#0,被称为延迟线程(latency thread)和分发依赖的读。基本上,这个线程穿过点阵,这个点阵的每个点指向下一个,这样创建读的依赖。每个读取所花费的平均时间提供了延迟度量。
基于通过负载生成线程产生的负载,这个延迟是变化的。一旦每个短暂的时间负载生成线程通过注入延迟来自动限流负载的产生,这样就可以在不同的负载下测试延迟。默认情况下,运行延迟线程的处理器核心会禁用硬件预取器,这样延迟线程就是顺序访问方式。
默认情况下,每个负载生成线程会pin在一个逻辑cpu上。例如,在激活了超线程的10核系统上,MLC创建18个负载生成线程并保留物理核0来运行延迟线程。每个负载生成线程可以配置成生成对缓存层级(cache hierarchy)生成不同程度的读和写。每个线程分配一个buffer用于读并且一个独立的buffer用于写(任何线程之间没有共享数据)。通过相应的不同大小缓存,可以确保引用满足任何缓存级别或者由内存提供服务。
有一些选项可以控制负载生成线程数量,每个线程使用的缓存大小,在哪里分配它们的内存,读写的比例以及顺序存取或随机存取。
4.测试缓存间延时:
MLC支持缓存到缓存传输延迟度量。这个测量方法的思路是在L1/L2/L3缓存填充数据(bring in lines into L1/L2/L3)然后将控制传给另外一个线程(这个线程运行在相同socket或不同socket的另外一个CPU核心上)。这个线程然后读取相同的数据以强制已经具有这些数据的缓存实现缓存到缓存的数据传输。这样通过操作初始化线程要么只读取数据到干净状态、要么修改数据使之进入M转台,就可以同时测量Hit(命中干净的行)和HitM(命中修改状态的行)的延迟。
