


随着AI、大数据、云计算等技术的兴起,为了提供更良好的企业个性化服务和个人定制化需求,数据存储显得尤为重要,openapi的稳定性使用是更重要的一环。
云上数据库为了保证数据库openapi的高可用能力与自适应能力,往往是会存在openapi的隐患问题,保证数据库openapi系统的稳定性高可用性成了重中之重。当前的网关系统无法个性化的针对特定的openapi进行熔断监控,监控的数据指标多是处理器、内存、硬盘等数据,缺少一套完整的openapi熔断监控方法。所以当大规模调用openapi出现系统来不及响应,响应时间很慢或者出现服务器宕机等问题时,没有办法做到用户侧及时感知,同时数据库系统崩溃,极大影响到用户操作。
基于以上问题,如何提供一种简单部署、快速感知的openapi监控熔断方案就成了亟需解决的问题。
三、发明创造的目的
本发明是针对现有技术方案的不足,基于sentinel和应用网关进行结合,通过sentinel进行对openapi某一时间采样进行熔断检测,prometheus监控采集openapi调用数据Prometheus会根据进行监控数据计算,gafana然后可视化监控。
为实现基于应用网关和sentinel的熔断以及gafana可视化监控能力,需要实现openapi的自适应熔断监控,需要解决的技术难点主要为以下两点:
第一是自主研发的应用网关,实现对于Prometheus的对openapi调用监控数据采集和sentinel的自定义的时间采样熔断规则。通过编写熔断规则绑定对应openapi,规则通过某一时间窗口采样,对openapi超时响应比例和错误比例来控制。
第二是实现应用网关自动化加载openapi能力和基于gafana的可视化监控。
五、发明创造的技术方案
1. 本发明提供一种基于Prometheus,应用网关,sentinel的openapi的自适应的熔断监控方案,并使用gafana作为可视化监控,其整体技术框架如附图1:
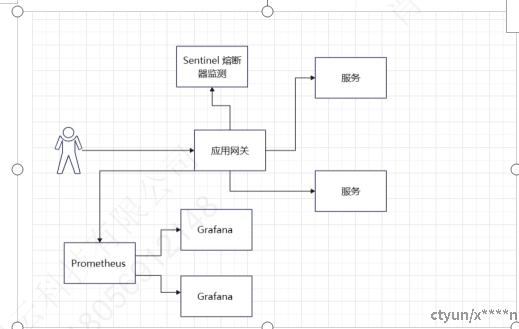
附图1.openapi熔断监控整体流程图
通过应用网关web页面断路器的熔断规则如下,示例如下:
errorCondition: "$StatusCode == 500" # 错误条件
errorThresholdByPercent: 20 # 用于控制错误阈值的百分比
timeoutThresholdByPercent: 20 # 用于控制后端超时请求的百分比
windowInSeconds: 30 # 窗口时间
openTimeoutSeconds: 15 # 断路器开的时间
downgradeBackend: # 降级后的后端配置
type: mock
statusCode: 403
3.通过ping-exporter组件的monitor模块进行配置yaml文件来创建监测任务,负责监控机器实例。
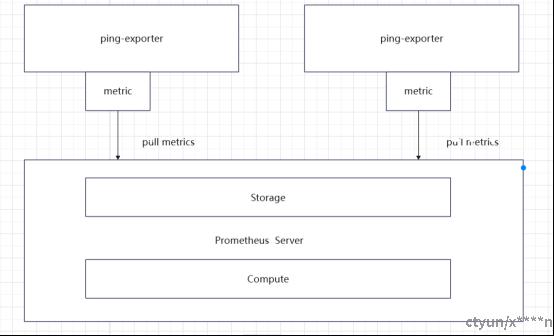
附图2.Prometheus拉取监控指标数据
2. 如附图2所示,部署完ping-exporter之后,当用户调用openapi时候,openapi监控指标数据会被拉取到Prometheus,Prometheus会根据数据计算,然后gafana进行可视化监控处理。可以展示对应openapi的熔断器的开关状态和对应openapi返回的状态码和响应时间。
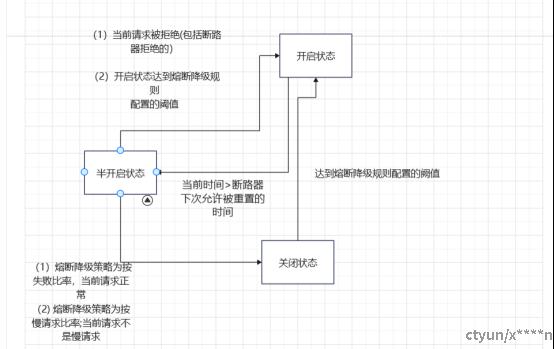
附图3.熔断器的状态转移
六、架构所具有的优点和效果。
利用本发明提供的一种基于时间采样应用网关openapi熔断监控的方法,具有以下优点:
本申请主要用于云计算数据库openapi使用领域,由于传统的网关监测并不能针对某个特定openapi进行熔断降级处理,不能满足用户自定义openapi后端处理;基于Prometheus和ping-exporter的监控以及gafana可视化监控,使用的组件成熟,部署方式简单,还可以及时让用户发现某个或者多个openapi熔断状态并及时做有效处理,有效的降低了经济损失和减少了人力资源成本。
七、实施例
1. 通过应用网关web页面可以自定义断路器规则。绑定经常报错或者超时的openapi。
2. 将ping-exporter二进制文件移至对应的源主机,并修改其为系统服务,设置开机自启动。
3. 根据监控任务参数对ping-exporter配置文件动态修改。配置进行更新。
4. Prometheus拉取实时的openapi调用数据。并在gafana进行可视化展示。
