


一、NCCL介绍
1.1NCCL简介
自从今年Chat-GPT席卷了全球,在短时间内获得了大量的关注和使用。人们开始意识到AI深度学习已经被广泛地应用到各个领域, 如计算机视觉、语义理解、语音识别等。他们都有一个共同的特点就是模型的规模越来越大,比如GPT-3模型的参数量达到了1750亿,而GPT-4模型的参数量更是达到了恐怖的1.8万亿,相比GPT-3增长了10倍以上。仅仅是针对GPT-3的参数量,如果使用8张V100的显卡,需要36年;使用512张V100显卡,需要7个月;使用1024张80GB的A100也需要训练一个月。为了解决算力增速不足的问题,人们考虑使用分布式训练,通过多多机多GPU之间协作训练,来提升算力。神经网络的分布式训练不仅仅是简单的分配任务给多台设备进行计算,还涉及到设备之间的数据传输,只有协调设备间的计算与通信,才能实现高效的分布式训练。
NCCL(NVIDIA Collective multi-GPU Communication Library)是NVIDIA的集合通信库,可以实现多GPU之间快速的数据传输和协同计算,为高性能计算领域提供分布式训练和数据并行加速提供支持。
1.2分布式训练策略
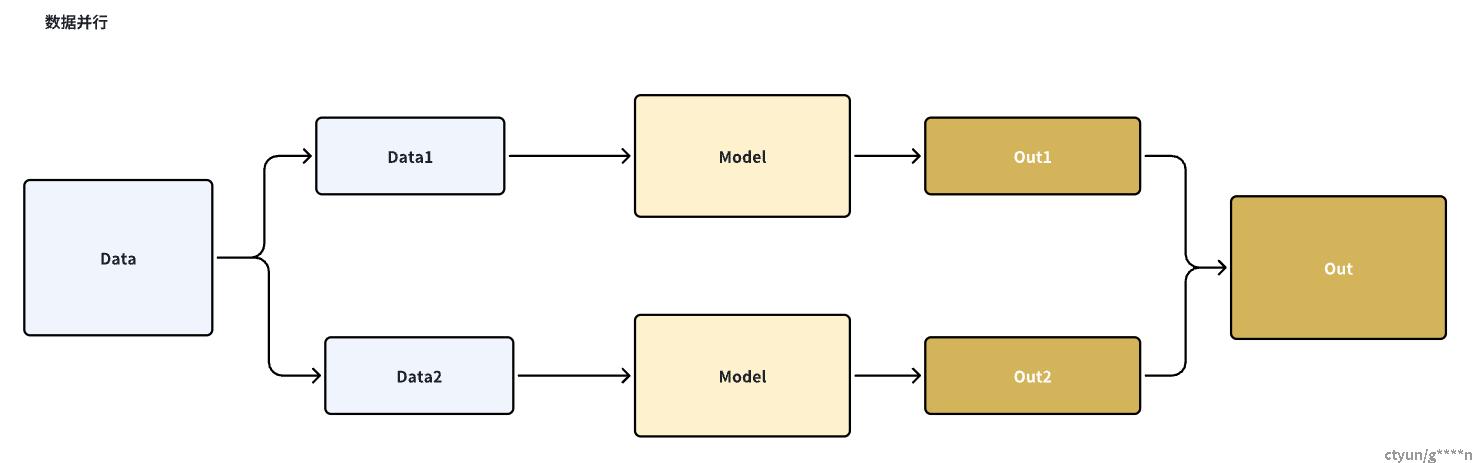
1.2.1数据并行
数据并行就是,将数据集进行切分,而每个设备上的模型是完整的。因为数据集被分发到了多个设备上,因此他们在反向传播的过程中得到的梯度是不同的,如果使用各自设备上的梯度进行更新各自的模型,会导致模型不一致,无法收敛到最终的模型。因此在数据并行的反向传播过程中,需要对各个设备上的梯度进行AllReduce,以确保各个设备上的模型始终一致。因此数据并行适合数据集较大,模型较小的场景,因为在该训练的反向传播过程中产生的梯度AllReduce代价较小(因为AllReduce的消耗很大,是分布式计算中的算力瓶颈)
暂时无法在飞书文档外展示此内容
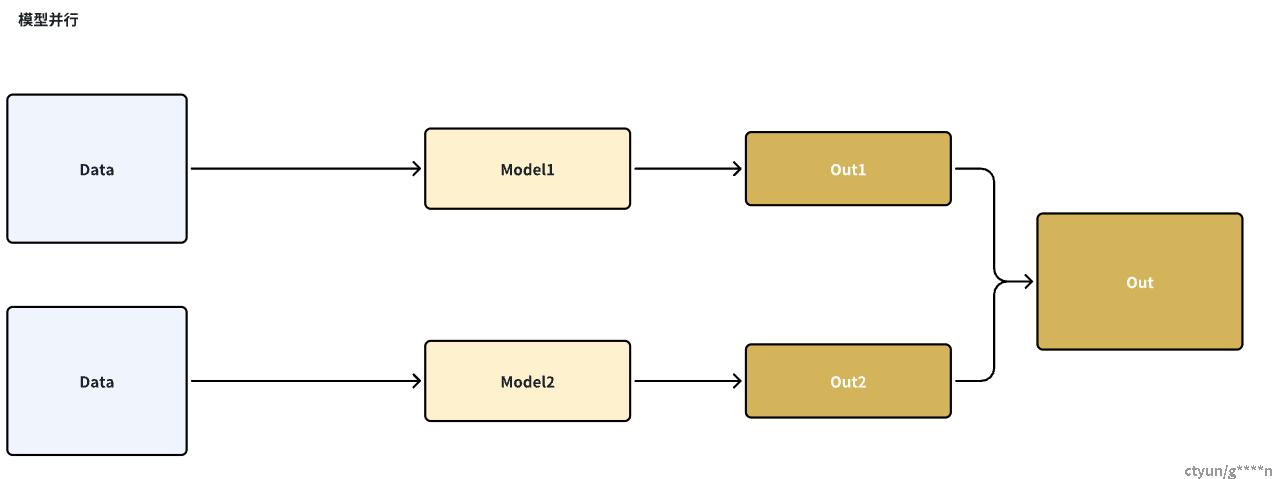
1.2.2模型并行
模型并行就是,每个设备上的数据集是完整且相同的,但是模型被切分到了各个设备上,该方法省去了多个设备之间的梯度AllReduce消耗,因为每个设备都拥有完整的数据集,但是会产生较大的通信代价,因为每次一层网络的训练结果数据需要广播给所有的设备上。
暂时无法在飞书文档外展示此内容
1.2.3流水并行
流水并行我理解就是模型拆分之后进行接力训练,比如一个模型共有8层网络,讲这8层网络切分到2个GPU设备上,其中GPU0进行前4层网络的计算,GPU1进行后4层网络的计算,前者计算后的输出结果作为后者的输入参数,并继续“接力”计算。
暂时无法在飞书文档外展示此内容

1.3通信原语
并行任务的通信一般可以分为点对点(Point-to-point communication)和集合通信(Collective communication),P2P通信这种模式只有一个sender和receiver,集合通信则包含多个sender和recevier。常见的通信原语包括:broadcast、gather、all-gather、scatter、reduce、all-reduce等。
1.3.1Reduce
从多个sender接收数据,最终combine到一个节点上
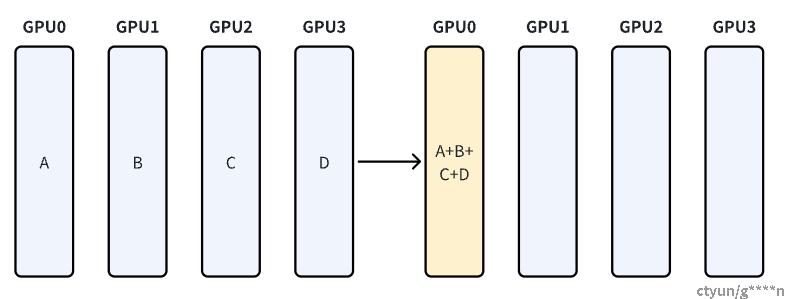
从多个sender接收数据,最终combine到每一个结点上,前面提到的数据并行中反向传播就是利用AllReduce将各个设备中训练后的梯度统一后广播到各个设备中
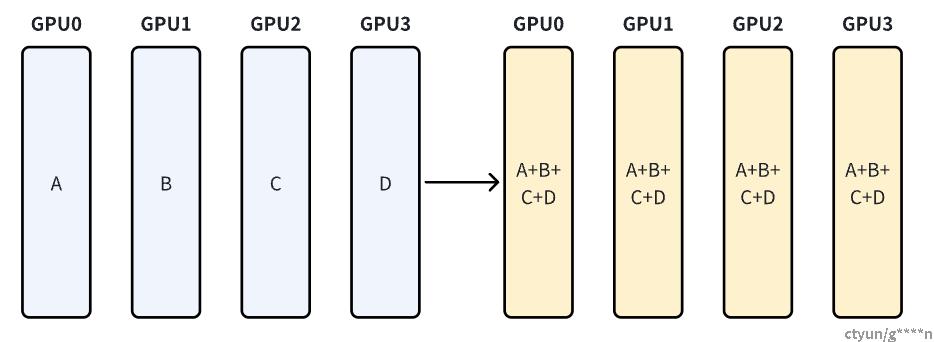
1.3.2Ring-base collective
Ring-base collective是将所有的通信节点通过首位相连形成一个单向环,数据在环上依次传输。在broadcast场景,假设有4个GPU,GPU0为sender将信息发送给剩下的GPU,采用一次传输全部和分成多次传输两种方式进行发送。前者的通信时间会随着通信节点数线性增长,在进行两个GPU节点之间的通信时,其余节点的带宽是浪费的,效率很低。后者会将需要传输的数据分成多份,每次只传输一部分数据,因此每个GPU节点都会同时参与数据的传输,且通信时间不会随着节点数的增加,只和数据总量和带宽有关,注意:数据分割数需要远大于GPU节点数。
-
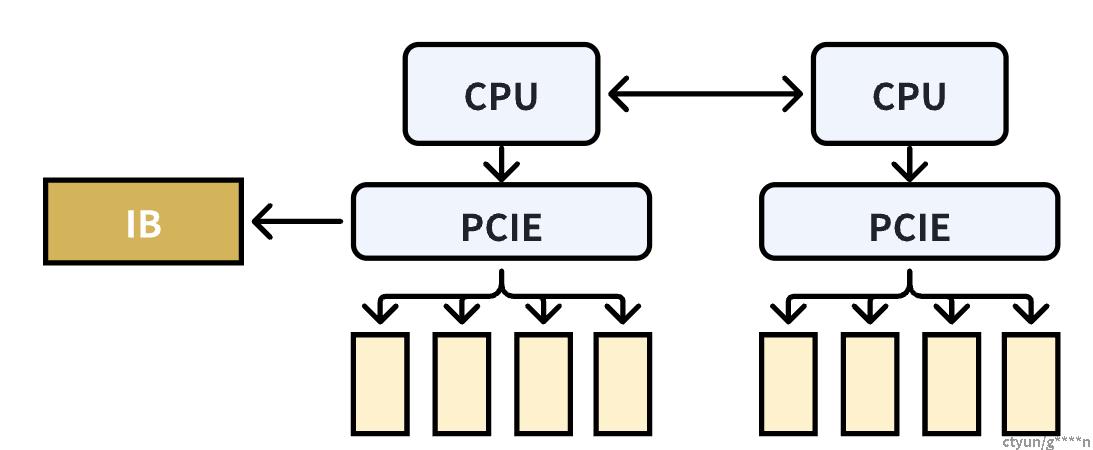
单机4卡通过同一个PCIe switch挂载在一颗CPU上,
-
单机8卡通过两个CPU下不同的PCIe switch挂载
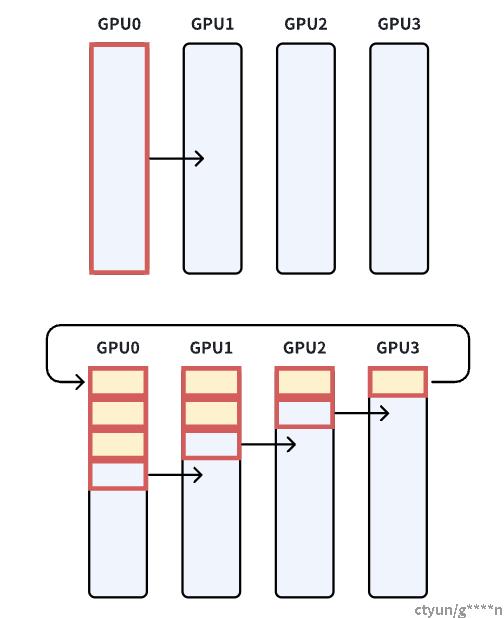
1.3.3NCCL中的通信原语实现
NCCL中包含三种原语操作:Copy、Reduce和ReduceAndCopy。单机多卡之间通过PCIe、NVlink、GPU Direct P2P进行通信;多机多卡之间通过socket、InfiniBand with GPU Direct RDMA进行通信,下图右侧部分为单机多卡间的通信环,左侧通过IB(InfiniBand无限带宽)实现多机之间的数据传输
1.4专有名词解释
1.4.1PCIe(高速串行总线)
PCIe是一种连接扩展设备的高速串行总线标准。它是一种内部接口,用于连接主板(类似于购物中心)和各种插槽(类似于商店)上的扩展设备,如显卡、网卡、硬盘控制器和其他周边设备。PCIe提供了快速而可靠的数据传输通道,允许扩展设备与计算机系统进行高速通信。可以实现几十GB/S的传输速度
1.4.2NVlink(NVIDIA的高速互连技术)
NVLink是一种由NVIDIA开发的高速互连技术,用于在计算机系统中连接多个图形处理单元(GPU),以实现更高的数据传输速度和更低的延迟。能够提供比PCIe更快的传输速度,可通过桥接器连接两块NVIDIA显卡,实现上百GB/S的传输速度
1.4.3Infiniband(无限带宽)
InfiniBand(无限带宽)是一种高性能、低延迟的计算和存储网络架构和通信协议。
InfiniBand被广泛应用于高性能计算(HPC)领域和大规模数据中心,它提供了高带宽和低延迟的数据传输能力,适用于处理大规模并行计算、高速数据存储和集群应用。带宽可以达到400GB/S
1.4.4MPI(并行计算Message Passing Interface)
MPI (Message Passing Interface) 是一种用于编写并行程序的通信协议和标准。它提供了一套函数接口,使得在多个计算节点(通常是集群或超级计算机)上的多个进程之间进行消息传递和通信成为可能,从而实现并行计算。MPI主要用于解决并行计算中的通信和同步问题。它允许开发人员将一个问题分解为多个并行的任务,每个任务都在不同的计算节点上执行,通过消息传递来共享数据和结果。
二、NCCL源码阅读-初始化部分
2.1官方文档中的example代码
-
上述代码中,显示进行了一些MPI相关的操作,主要是为了在NCCL连接建立之前,在设备之间传输一些额外的信息,比如ncclUniquedId。然后是CUDA相关的一些操作:分配内存、创建stream等,其中涉及到NCCL的代码包括:ncclGetUniqueId、ncclCommInitRank和ncclAllReduce。 本文先针对ncclGetUniqueId进行探究
int main(int argc, char* argv[])
{
int size = 32*1024*1024;
int myRank, nRanks, localRank = 0;
//initializing MPI
MPICHECK(MPI_Init(&argc, &argv));
MPICHECK(MPI_Comm_rank(MPI_COMM_WORLD, &myRank));
MPICHECK(MPI_Comm_size(MPI_COMM_WORLD, &nRanks));
//calculating localRank based on hostname which is used in selecting a GPU
uint64_t hostHashs[nRanks];
char hostname[1024];
getHostName(hostname, 1024);
hostHashs[myRank] = getHostHash(hostname);
MPICHECK(MPI_Allgather(MPI_IN_PLACE, 0, MPI_DATATYPE_NULL, hostHashs, sizeof(uint64_t), MPI_BYTE, MPI_COMM_WORLD));
for (int p=0; p<nRanks; p++) {
if (p == myRank) break;
if (hostHashs[p] == hostHashs[myRank]) localRank++;
}
ncclUniqueId id;
ncclComm_t comm;
float *sendbuff, *recvbuff;
cudaStream_t s;
//get NCCL unique ID at rank 0 and broadcast it to all others
if (myRank == 0) ncclGetUniqueId(&id);
MPICHECK(MPI_Bcast((void *)&id, sizeof(id), MPI_BYTE, 0, MPI_COMM_WORLD));
//picking a GPU based on localRank, allocate device buffers
CUDACHECK(cudaSetDevice(localRank));
CUDACHECK(cudaMalloc(&sendbuff, size * sizeof(float)));
CUDACHECK(cudaMalloc(&recvbuff, size * sizeof(float)));
CUDACHECK(cudaStreamCreate(&s));
//initializing NCCL
NCCLCHECK(ncclCommInitRank(&comm, nRanks, id, myRank));
//communicating using NCCL
NCCLCHECK(ncclAllReduce((const void*)sendbuff, (void*)recvbuff, size, ncclFloat, ncclSum,
comm, s));
//completing NCCL operation by synchronizing on the CUDA stream
CUDACHECK(cudaStreamSynchronize(s));
//free device buffers
CUDACHECK(cudaFree(sendbuff));
CUDACHECK(cudaFree(recvbuff));
//finalizing NCCL
ncclCommDestroy(comm);
//finalizing MPI
MPICHECK(MPI_Finalize());
printf("[MPI Rank %d] Success \n", myRank);
return 0;
}2.2ncclGetUniqueId[init.cc]
-
在doc的example代码中,如果是rank0,则会调用ncclGetUniqueId来获取id,并通过mpi来广播给其他rank
//get NCCL unique ID at rank 0 and broadcast it to all others
if (myRank == 0) ncclGetUniqueId(&id);
MPICHECK(MPI_Bcast((void *)&id, sizeof(id), MPI_BYTE, 0, MPI_COMM_WORLD));-
ncclGetUniqueId产生uniqueId
NCCL_API(ncclResult_t, ncclGetUniqueId, ncclUniqueId* out);
ncclResult_t ncclGetUniqueId(ncclUniqueId* out) {
NCCLCHECK(ncclInit());
NCCLCHECK(PtrCheck(out, "GetUniqueId", "out"));
ncclResult_t res = bootstrapGetUniqueId((struct ncclBootstrapHandle*)out);
TRACE_CALL("ncclGetUniqueId(0x%llx)", (unsigned long long)hashUniqueId(*out));
return res;
}2.3ncclInit
-
nccl初始化时会调用ncclInit,为了防止重复初始化,加互斥量锁。然后会调用initEnv进行环境的初始化
pthread_mutex_t initLock = PTHREAD_MUTEX_INITIALIZER;
static bool initialized = false;
static ncclResult_t ncclInit() {
if (__atomic_load_n(&initialized, __ATOMIC_ACQUIRE)) return ncclSuccess;
pthread_mutex_lock(&initLock);
if (!initialized) {
initEnv();
initGdrCopy();
// Always initialize bootstrap network
NCCLCHECK(bootstrapNetInit());
// 网络插件
NCCLCHECK(ncclNetPluginInit());
initNvtxRegisteredEnums();
__atomic_store_n(&initialized, true, __ATOMIC_RELEASE);
}
pthread_mutex_unlock(&initLock);
return ncclSuccess;
}
2.4initEnv
-
初始化环境变量,通过解析nccl.conf文件,并使用setenv系统调用设置环境变量
void initEnv() {
char confFilePath[1024];
const char * userDir = userHomeDir();
if (userDir) {
sprintf(confFilePath, "%s/.nccl.conf", userDir);
setEnvFile(confFilePath);
}
sprintf(confFilePath, "/etc/nccl.conf");
setEnvFile(confFilePath);
}
2.5initGdrCopy
-
GDR是指GPU Direct RDMA,两个显卡通过网卡直接访问内存。ncclGdrInit加载GDR动态库
// GDRCOPY support
gdr_t ncclGdrCopy = NULL;
ncclResult_t initGdrCopy() {
if (ncclParamGdrCopyEnable() == 1) {
ncclGdrCopy = ncclGdrInit();
}
return ncclSuccess;
}2.6bootstrapNetInit
-
nccl所需要两个网络,一个是bootstrap网络,一个是数据通信网络。
-
bootstrap网络主要用于初始化时交换一些简单的信息,如果每个机器的ip端口,由于数据量较小,而且只在初始化阶段执行一次,因此bootstrap使用的是tcp
-
而通信网络是用于实际数据的传输,因此优先使用RDMA(支持GDR的话会优先GDR)
-
-
通过C库函数getenv来获取环境变量的值“NCCL_COMM_ID”,作为NCCL库中用于通信的标识符,NCCL_COMM_ID的格式为“nccl_socket:ip:port”,其中ip指定要使用的IP地址,port指定要使用的端口号。后续这个ID会作为该实例的uniqueId。
/* Init functions */
static char bootstrapNetIfName[MAX_IF_NAME_SIZE+1];
static union ncclSocketAddress bootstrapNetIfAddr;
static int bootstrapNetInitDone = 0;
pthread_mutex_t bootstrapNetLock = PTHREAD_MUTEX_INITIALIZER;
ncclResult_t bootstrapNetInit() {
if (bootstrapNetInitDone == 0) {
pthread_mutex_lock(&bootstrapNetLock);
if (bootstrapNetInitDone == 0) {
char* env = getenv("NCCL_COMM_ID");
if (env) {
union ncclSocketAddress remoteAddr;
if (ncclSocketGetAddrFromString(&remoteAddr, env) != ncclSuccess) {
WARN("Invalid NCCL_COMM_ID, please use format: <ipv4>:<port> or [<ipv6>]:<port> or <hostname>:<port>");
return ncclInvalidArgument;
}
if (ncclFindInterfaceMatchSubnet(bootstrapNetIfName, &bootstrapNetIfAddr, &remoteAddr, MAX_IF_NAME_SIZE, 1) <= 0) {
WARN("NET/Socket : No usable listening interface found");
return ncclSystemError;
}
} else {
int nIfs = ncclFindInterfaces(bootstrapNetIfName, &bootstrapNetIfAddr, MAX_IF_NAME_SIZE, 1);
if (nIfs <= 0) {
WARN("Bootstrap : no socket interface found");
return ncclInternalError;
}
}
char line[SOCKET_NAME_MAXLEN+MAX_IF_NAME_SIZE+2];
sprintf(line, " %s:", bootstrapNetIfName);
ncclSocketToString(&bootstrapNetIfAddr, line+strlen(line));
INFO(NCCL_INIT, "Bootstrap : Using%s", line);
bootstrapNetInitDone = 1;
}
pthread_mutex_unlock(&bootstrapNetLock);
}
return ncclSuccess;
}2.7bootstrapGetUniqueId
-
在bootstrap网络建立初期获取uniqueId的函数,这个uniqueId包含一个magic number用于通信时校验,还包含一个ncclSocketAddress结构体,其中包含一个地址族和地址数据,这个ncclSocketAddress是属于root gpu的,作为一个单机实例的标识id,其实就是当前机器的ip和port.
ncclResult_t bootstrapGetUniqueId(struct ncclBootstrapHandle* handle) {
memset(handle, 0, sizeof(ncclBootstrapHandle));
// magic在通信中起到验证作用
NCCLCHECK(getRandomData(&handle->magic, sizeof(handle->magic)));
char* env = getenv("NCCL_COMM_ID");
if (env) {
INFO(NCCL_ENV, "NCCL_COMM_ID set by environment to %s", env);
if (ncclSocketGetAddrFromString(&handle->addr, env) != ncclSuccess) {
WARN("Invalid NCCL_COMM_ID, please use format: <ipv4>:<port> or [<ipv6>]:<port> or <hostname>:<port>");
return ncclInvalidArgument;
}
} else {
memcpy(&handle->addr, &bootstrapNetIfAddr, sizeof(union ncclSocketAddress));
NCCLCHECK(bootstrapCreateRoot(handle, false));
}
return ncclSuccess;
}