


1 概述
Telegraf 是一个用 Golang 写的开源数据收集 Agent,基于插件驱动。本身提供的输入和输出插件非常丰富,当然有需求也可以自行编写(需要重新编译)。
Telegraf 是 influxdata 公司的时间序列平台 TICK 技术栈中的 “T”,主要用于收集时间序列型数据,比如服务器 CPU 指标、内存指标、各种 IoT 设备产生的数据等等。
它具备输入插件,可以直接从系统获取指标数据,从第三方 API 获取指标数据,甚至可以通过 statsd 和 Kafka 获取指标数据。它还具备输出插件,可以将采集的指标发送到各种数据存储,服务和消息队列。比如 InfluxDB,Graphite,OpenTSDB,Datadog,Librato,Kafka,MQTT,NSQ 等等。
2 核心概念
Telegraf 工作原理大概是这样:定时去执行输入插件收集数据,数据经过处理插件和聚合插件,批量输出到数据存储。
2.1 指标(Metrics)
2.1.1 概念
Telegraf 指标是用于在处理过程中对数据进行建模的内部表示。这些指标紧密基于 InfluxDB 的数据模型,包含四个主要组成部分:
- 度量名称(Measurement name):指标的描述和命名空间。
- 标签集合(Tags):Key-Value 键值对,可以类比为关系型数据库的键值,常用于快速索引和唯一标识。标签在设计的时候,尽量避免各种数值型,尽量使用有限集合。
- 字段集合(Fields):Key-Value 键值对,包含指标描述的数据类型和值。
- 时间戳(Timestamp):与字段集合关联的日期和时间。
此指标类型仅存在于内存中,必须转换为具体表示形式才能传输或查看。Telegraf 为这些转换提供输出数据格式(也称为序列化程序)。Telegraf 的默认序列化程序转换为 InfluxDB Line Protocol,它提供了高性能和 Telegraf 指标的一对一直接输出。
2.1.2 示例
cpu,cpu=cpu0,host=ecs-292756 usage_idle=99.39939939885349,usage_iowait=0,usage_softirq=0,usage_steal=0,usage_guest_nice=0,usage_user=0.40040040039107766,usage_system=0.20020020019553883,usage_nice=0,usage_irq=0,usage_guest=0 1663834400000000000
cpu,cpu=cpu1,host=ecs-292756 usage_nice=0,usage_softirq=0,usage_guest=0,usage_guest_nice=0,usage_steal=0,usage_user=0.10030090270831422,usage_system=0.20060180541662845,usage_idle=99.69909729159454,usage_iowait=0,usage_irq=0 1663834400000000000
cpu,cpu=cpu-total,host=ecs-292756 usage_iowait=0,usage_softirq=0,usage_steal=0,usage_nice=0,usage_system=0.20060180541194378,usage_idle=99.5987963888021,usage_irq=0,usage_guest=0,usage_guest_nice=0,usage_user=0.20060180541194378 1663834400000000000
每一条数据用空格分成了 3 部分。
- 第一部分是 measurement 和 tags ,上例中第一个逗号之前的部分即 cpu,就是 measurement,第一个逗号之后的部分 cpu=cpu-total,host=ecs-292756 就是 tags,host 这个标签标识了这个监控数据是从哪里采集的。cpu=cpu-total这个标签表示这是 cpu 的整机情况,其他的那些监控数据有 cpu=cpu0,cpu=cpu1 等标签,表示不同 CPU 核的监控数据。
- 第二部分是 fields,filed_key=field_value 这种格式,usage_guest=0 就是一个 field,因为 Telegraf 是 InfluxDB 生态的,InfluxDB 是列式存储,这种格式非常合适。但是在夜莺、OpenTSDB、Prometheus 这种生态里,一般不这么描述监控数据,所以后续是需要有个格式转换的,转换逻辑也很简单,就是 ${measurement}_${field_key} 组成 metric,上面这一条数据,会被拆成 10 个 metric。
- 第三部分是时间戳:1663834400000000000,这个时间戳应该是纳秒为单位的,上报给不同的后端的时候,要做转换,比如上报给 OpenTSDB 的时候,OpenTSDB 就把时间转换为秒了。
Telegraf 主要是为 InfluxDB 设计的,采集的很多监控指标,标签部分可能不固定,比如 net_response 这个采集 input 插件,在成功的时候,会附一个标签:result=success,超时的时候,又会变成:result=timeout,对于 InfluxDB 的存储模型和使用方式来说,这样做是没问题的,但是大部分时序库都不喜欢这个玩法,时序库更喜欢标签是稳态的,因为标签是监控数据的唯一标识,如果标签发生变化,就相当于是新的监控数据了。好在 Telegraf 提供了一些配置机制,可以把部分标签给干掉,只留那些稳定的标签,这样就舒服多了。
上面的采集的CPU和内存数据,标签部分只有:host=ecs-292756 和 cpu=cpu-total 这种数据,是稳定的,不需要对标签做额外处理。host 标签默认取的机器名。
2.2 插件(Plugins)
官方插件链接
2.2.1 概念
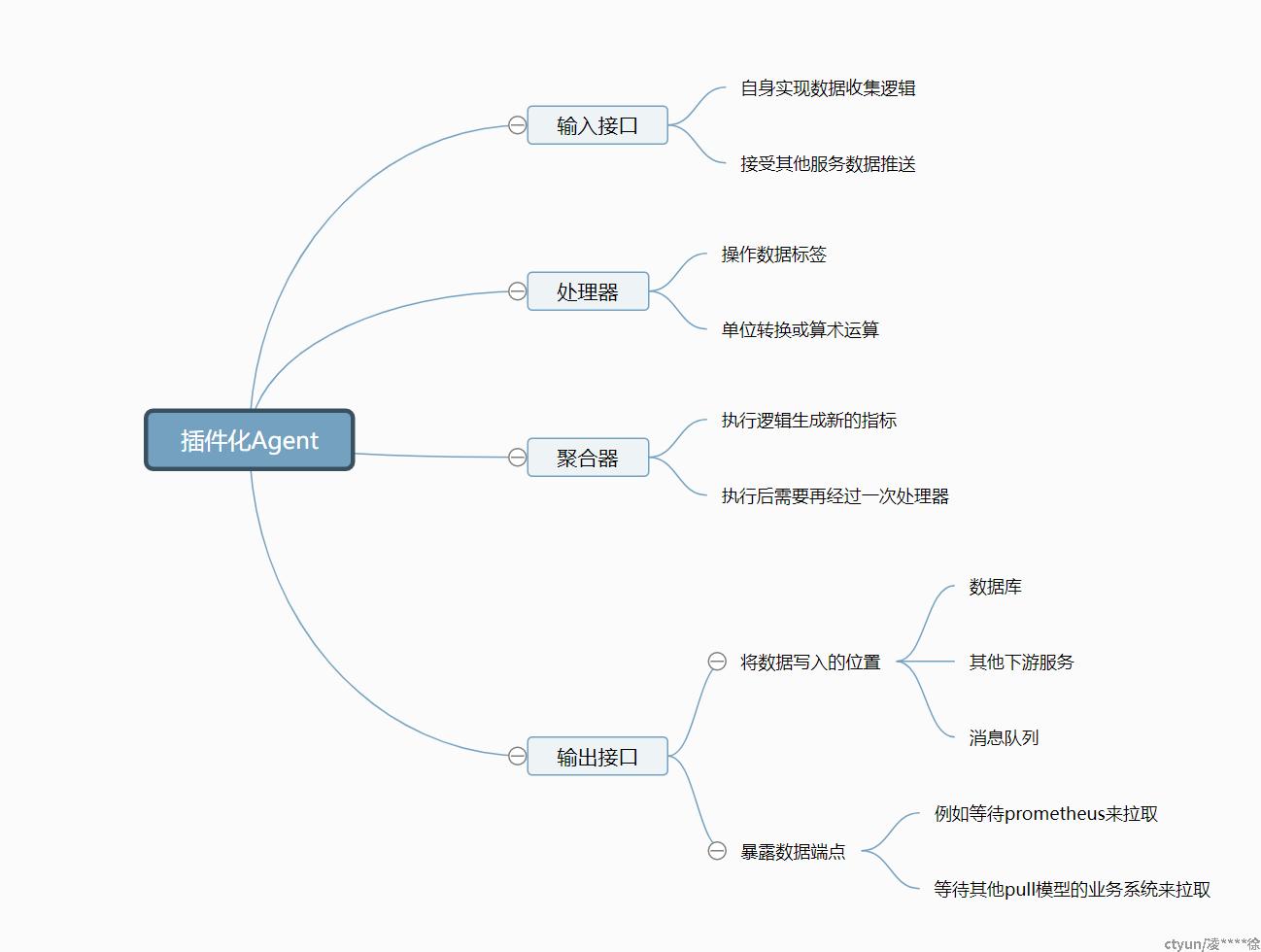
Telegraf 有四种类型的插件:
- 输入插件(Inputs):收集各种时间序列性指标,包含各种系统信息和应用信息的插件。
- 处理插件(Processor):当收集到的指标数据流要进行一些简单处理时,比如给所有指标添加、删除、修改一个Tag。只是针对当前的指标数据进行。
- 聚合插件(Aggregator):聚合插件有别于处理插件,就在于它要处理的对象是某段时间流经该插件的所有数据(所以,每个聚合插件都有一个 period 设置,只会处理 now() - period 时间段内的数据),比如取最大值、最小值、平均值等操作。
- 输出插件(Outputs):收集到的数据,经过处理和聚合后,输出到数据存储系统,可以是各种地方,如:文件、InfluxDB、各种消息队列服务等等。
2.2.2 常用输入插件
- cpu:系统CPU信息,如用户态和系统态利用率等等。
- mem:系统内存信息,如物理、虚拟、交换内存量等等。
- disk:磁盘占用信息。
- diskio:磁盘IO性能。
- net 和 netstat :网卡和网络信息。
- system :当前系统负载信息,类似uptime信息。
- file:每个时间周期读取文件所有信息。
- procstat:收集满足条件的进程信息,包含进程CPU占用、内存占用等信息。
- exec:定时执行某个可执行文件,可执行文件根据要求输出到标准输出即可。
- influxdb_listener 或 http_listener_v2:外部应用可以通过HTTP请求把数据发送给Telegraf。
2.2.3 常用输出插件
- influxdb:输出到 InfluxDB。
- file:输出到文件。
- http:输出到某个 HTTP 服务器。
2.3 架构
2.3.1 插件架构-1
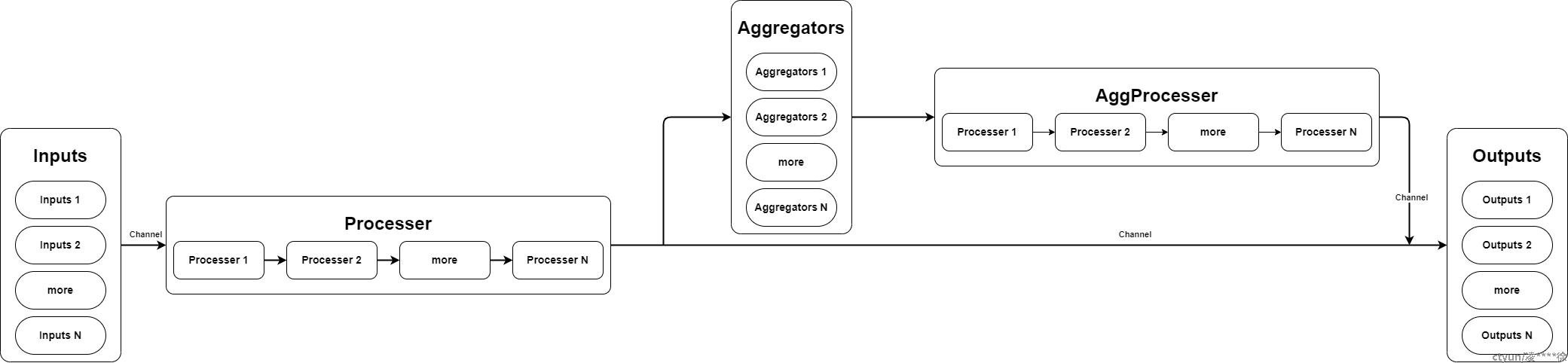
2.3.2 插件架构-2
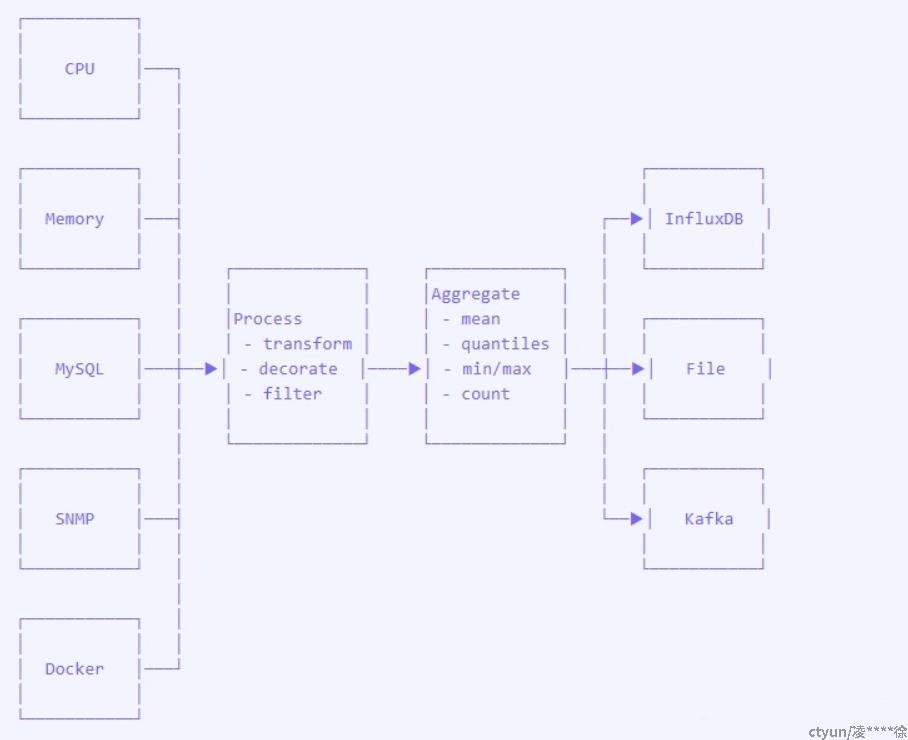
2.3.3 插件设计思路
3 简单用法
3.1 快速生成配置并启动
# 生成配置
telegraf config -input-filter cpu:mem -output-filter influxdb > telegraf.conf
# 运行Telegraf
telegraf --config telegraf.conf
3.2 查看输出
# 修改配置
[[outputs.influxdb]]
urls = ["udp://localhost:8089"]
# 使用`netcat`监听8089端口
nc -lu 8089
3.3 输入测试
# 修改配置
[[inputs.socket_listener]]
service_address = "tcp://:8094"
data_format = "influx"
# 输入测试
echo 'my_measurement,my_tag_key=my_tag_value my_field="my_field_ value"' | nc localhost 8094
4 Telegraf 术语
agent
代理是 Telegraf 的核心部分,它从声明的输入插件中收集指标,并根据给定配置启用的插件将指标发送到声明的输出插件。
相关条目:输入插件、输出插件
aggregator plugin
聚合器插件从输入插件接收原始指标,并从中创建聚合指标。然后将聚合指标传递给配置的输出插件。
相关条目:输入插件、输出插件、处理器插件
batch size
Telegraf 代理批量发送指标以输出插件,而不是单独发送。批大小控制 Telegraf 发送到输出插件的每个写入批的大小。
相关条目:输出插件
collection interval
从每个输入插件收集数据的默认全局间隔。收集间隔可以被每个单独的输入插件的配置覆盖。
相关条目:输入插件
collection jitter
收集抖动用于防止每个输入插件同时收集指标,这可能会对系统产生可测量的影响。在收集指标之前,每个收集间隔,每个输入插件都将在零和收集抖动之间休眠一个随机时间。
相关条目:收集间隔、输入插件
external plugin
在 Telegraf 之外构建的程序,通过 execd 插件运行。提供添加内部 Telegraf 插件中不存在的功能的灵活性。
flush interval
将数据从每个输出插件刷新到其目标的全局间隔。此值不应设置为低于收集间隔。
相关条目:收集间隔、刷新抖动、输出插件
flush jitter
刷新抖动用于防止每个输出插件同时发送写入,这可能会淹没某些数据接收器。每个刷新间隔,每个输出插件在发出指标之前将休眠一个介于零和刷新抖动之间的随机时间。这有助于在运行大量 Telegraf 实例时消除写入峰值。
相关条目:刷新间隔、输出插件
input plugin
输入插件主动收集指标并将其传送到核心代理,聚合器、处理器和输出插件可以对指标进行操作。为了激活输入插件,需要在 Telegraf 的配置文件中启用和配置它。
相关条目:聚合器插件、收集间隔、输出插件、处理器插件
metric buffer
当输出插件的写入失败时,指标缓冲区会缓存各个指标。Telegraf 将尝试在成功写入输出时刷新缓冲区。当此缓冲区填满时,最旧的指标将首先被删除。
相关条目:输出插件
output plugin
输出插件将指标传递到其配置的目标。为了激活输出插件,需要在 Telegraf 的配置文件中启用和配置它。
相关条目:聚合器插件、刷新间隔、输入插件、处理器插件
precision
精度配置设置确定从输入插件接收的点中保留多少时间戳精度。所有传入的时间戳都被截断为给定的精度。然后,Telegraf 用零填充截断的时间戳以创建纳秒时间戳;输出插件将以纳秒为单位发出时间戳。有效精度为 ns、us 或 µs、ms 和 s。
例如,如果精度设置为 ms,则纳秒 epoch 时间戳 1480000000123456789 将被截断为 1480000000123 以毫秒为单位的精度,然后用零填充以生成新的、不太精确的纳秒时间戳 1480000000123000000。输出插件不会进一步更改时间戳。对于服务输入插件,将忽略精度设置。
相关条目:聚合器插件、输入插件、输出插件、处理器插件、服务输入插件
processor plugin
处理器插件转换、修饰和/或过滤输入插件收集的指标,将转换后的指标传递给输出插件。
相关条目:聚合器插件、输入插件、输出插件
service input plugin
服务输入插件是在 Telegraf 代理运行时以被动收集模式运行的输入插件。它们在套接字上侦听已知的协议输入,或者在将引入的指标传送到 Telegraf 代理之前,将自己的逻辑应用于引入的指标。
相关条目:聚合器插件、输入插件、输出插件、处理器插件
参考资料
- telegraf官方文档
- telegraf官方github
