



第三次信息化浪潮涌动,大数据时代全面开启。随着大数据行业的发展,大数据生态圈中的相关技术也一直在不断地迭代更进。希望通过本文的介绍可以让大家快速地了解大数据组件生态圈的相关知识体系。
我们可以把大数据组件比作生活中的各种工具,每个工具都有各自的用处,互相之间又有联系。一个完整的大数据平台往往包括数据采集、存储、计算、分析,集群监控等功能,这些主要通过发挥各个组件的功能来实现,而这些组件需要被部署在几台、几十台、甚至成百上千台的机器中。
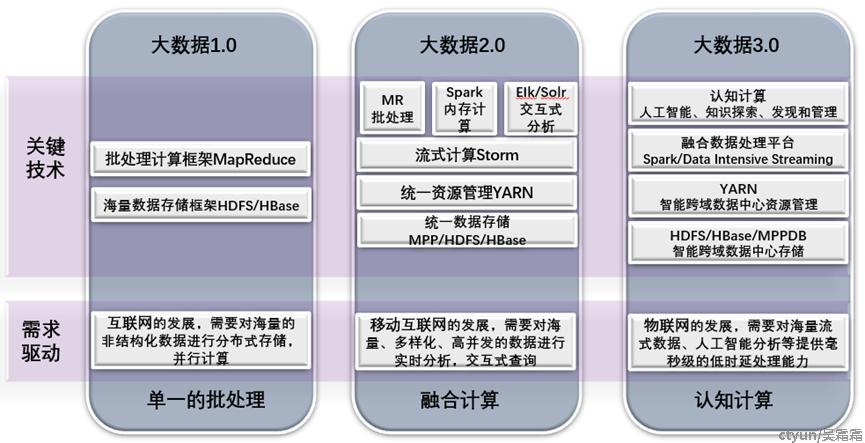
大数据技术的发展可以按照其特点分成三个不同阶段:大数据1.0、大数据2.0、大数据3.0,目前我们整处于大数据3.0阶段。
大数据1.0阶段:单一的批计算
大数据2.0阶段:融合计算
大数据3.0阶段:认知计算
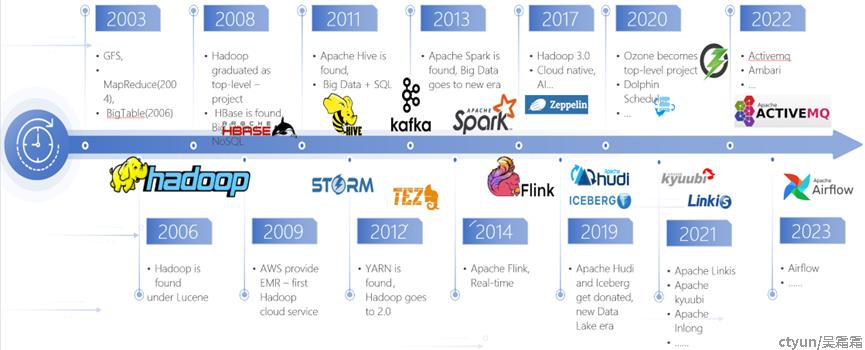
Hadoop的开源真正开启了大数据技术的发展。大数据开源技术非常丰富,通过下面一张图我们可以简单看下大数据开源技术的发展,主要围绕Hadoop的大数据开源生态,促进了大数据的持续繁荣。
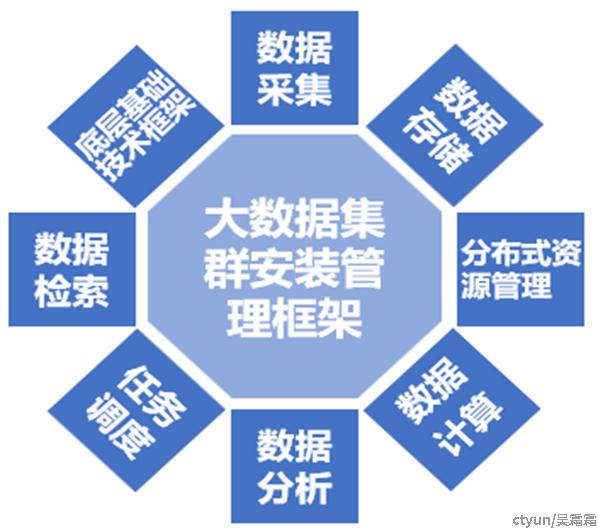
截至目前,经过一系列发展演进后,大数据组件生态圈的核心技术可以总结为以下9大类,下面以典型的几个组件技术作为代表进行介绍:
- 数据采集:指从各种数据源中获取数据并存储起来的过程,也可以称为数据同步。在当今信息化时代,数据采集成为了各行各业中不可或缺的一环。数据采集是大数据的基础部分,采集的数据源可以是各种各样的数据,包括结构化的数据、非结构化的数据和半结构化的数据。数据采集技术框架包括以下几部分:
- 日志数据实时监控采集:主要包括Flume、Logstash、FilBeat。
|
|
Flume |
Logstash |
FilBeat |
|
内存 |
大 |
大 |
小 |
|
插件 |
需要些API |
多 |
多 |
|
功能 |
从多种输入端采集数据并输出多种输出端 |
从多种输入端采集并实时解析和转换数据并输出到多种输出端 |
传输 |
|
轻重 |
相对较重 |
相对较重 |
轻量级二进制文件 |
|
进程 |
一台服务器可以有多个进程,挂掉后需要手动拉起 |
一台服务器只允许一个进程,挂掉后需要手动拉起 |
十分稳定 |
技术选型:如果采集场景多变,建议使用Flume;如果在ELK架构中则建议使用Logstash;如果采集场景单一,为了追求性能,建议使用FilBeat。
- 关系型数据库实时数据采集:主要包括Canal和Maxwell。
|
|
Cannal |
Maxwell |
|
公司 |
阿里 |
Zendesk |
|
开发语言 |
Java |
Java |
|
高可用 |
支持HA |
不支持,支持断点续传 |
|
数据格式 |
格式自由 |
JSON |
|
数据落地 |
支持客户端,支持定制/Kafka |
Kafka,Redis等 |
技术选型:如果要封装一套稳定可靠且长期使用的平台,建议使用Canal;如果是基于MySQL和Kafaka的技术栈,短时间内需要快速迭代,推荐使用Maxwell。
- 关系型数据库离线数据采集:主要包括Sqoop和Datax。
|
|
Sqoop |
Datax |
|
运行模式 |
MapReduce |
单进程多线程 |
|
分布式 |
支持 |
不支持 |
|
执行效率 |
高 |
中 |
|
数据源类型 |
仅支持关系型数据库和Hadoop相关存储系统 |
支持20多种 |
技术选型:如果只需要实现MySQL和HDFS之间的数据转移,建议使用Sqoop;如果需要实现多种数据源之间的数据转移,建议使用Datax。
- 数据存储:主要包括HDFS、HBase、Kafka、Kudu、Hudi、Alluxio等。
- HDFS:(Hadoop Distributed File System)是Hadoop生态系统的一个重要组成部分,是Hadoop中的的存储组件。它是一个分布式文件系统,提供对应用程序数据的高吞吐量访问。特点:HDFS适合离线分析,不支持单条纪录级别的update操作,随机读写性能差(一次写入,多次读取)。HDFS最大的缺点是不支持单条数据的修改操作。
- HBase:键值库提供业务键值数据的结构化存储与检索能力,主要包括键值数据存储、键值数据查询功能,提供键值数据管理和键值数据库监测功能。兼容社区HBase接口,提供Java API,Restful接口形式。是一个分布式、数据多版本、面向列的nosql数据库。提供可弹性扩展的多维表格键值存储和即席查询能力。支持上亿行、可扩展列,具备强一致性、高扩展、高可用的特性。特点:可以进行高效随机读写,却并不适用于基于SQL的数据分析方向,大批量数据获取时的性能较差。HBase可以利用HDFS的海量数据存储能力,并支持修改操作。
- Kafka:Apache Kafka是一个优秀的分布式事件流平台,被广泛用于高性能数据管道、流分析、数据集成和任务关键型应用程序中。特点:用作海量数据的临时缓冲存储,对外提供高吞吐量的读写能力。
- Kudu:是一个分布式列式存储引擎/系统,由Cloudera开源后捐献给Apache基金会很快成为顶级项目。用于对大规模数据快速读写的同时进行快速分析。介于HDFS和HBase之间的技术组件,较好地解决了HDFS与HBase的这些缺点。特点:它不及HDFS批处理快,也不及HBase 随机读写能力强,但是反过来它比HBase批处理快(适用于OLAP的分析场景),而且比HDFS随机读写能力强(适用于实时写入或者更新的场景)。
- Hudi:是一个开源数据管理框架,提供列数据格式的记录级插入、更新和删除功能。特点:更新范围小,是文件级别,不是表级别;使用Bloomfilter机制+二次查找,可快速确定记录是更新还是新增。
- Alluxio:是一个开源的基于内存的分布式存储系统,它为数据驱动型应用和存储系统构建了桥梁,将数据从存储层移动到距离数据驱动型应用更近的位置从而能够更容易被访问。 这还使得应用程序能够通过一个公共接口连接到许多存储系统。特点:Alluxio能够作为分布式共享缓存服务,提供内存级I/O吞吐率。
技术选型:HDFS作为数据的底层存储,以高可用的方式存储大文件;HBase适用于对具有高吞吐量和低输入/输出延迟的大型数据集进行快速读写操作;Kafka适用于吞吐量较低、端到端的延迟较低,并需要提供强大的耐用性保证的场景;Kudu适用于OLAP的分析场景和实时写入或者更新的场景。
- 分布式资源管理:为了更好地处理集群中服务器资源的变更,包括CPU、内存、磁盘、网络IO等,分布式资源管理系统应运而生:YARN。Apache YARN(Yet Another Resource Negotiator)是Hadoop集群资源管理器系统,YARN从x引入,最初是为了改善MapReduce的实现,但是它具有通用性,同样执行其他分布式计算模式。
- 数据计算:随着数据规模的不断增长和数据动态的快速产生,要求必须采用分布式计算框架才能实现与之匹配的实时性及吞吐。数据计算主要分为实时计算和离线计算。
- 实时计算:又称为流式计算,具备无界数据处理、无限数据、低延迟三个特征。主要包括Flink、Storm和Spark Streaming等。
|
|
Flink |
Storm |
Spark Streaming |
|
计算模型 |
Native |
Native |
Micro-Batch |
|
容错机制 |
Checkpoint |
Ack |
Checkpoint |
|
API类型 |
声明式 |
组合式 |
声明式 |
技术选型:小型且独立的实时项目选择Storm;能够满足“秒”级别的需求选择Spark Streaming;有高吞吐低时延需求的选择Flink。
- 离线计算:离线计算的数据是不再发生变化的,通常离线计算的任务都是定时的,使用场景一般对时效性要求比较低。主要包括MapReduce、Tez、Spark等。
-
- MapReduce:第一代离线数据计算引擎,将计算逻辑抽象成Map和Reduce两个阶段进行处理,非常适合数据密集型计算。
- Tez:作为一个框架工具,特定为hive和pig提供批量计算,可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能。
- Spark:最大的特点是内存计算,支持多种运行模式,可以跑在standalone,yarn上。
技术选型:MR在计算时,会对磁盘进行多次的读写操作,占用时间较多,耗费时间较长;Tez比MR快约5倍;Spark比MR快约10倍。
- 数据分析:数据分析框架常见的包括Hive、Clickhouse、Doris等。Hive是典型的离线OLAP数据分析引擎,Clickhouse、Doris是典型的实时OLAP数据分析引擎。
技术选型:Hive适合离线分析,稳定且可靠;Clickhouse适合实时写入和分析,支持高并发和非标准SQL;Doris适合实时写入和分析,并发能力有限,对SQL支持比较好。
- 任务调度:常见的任务调度包括Azkaban、DolphinScheduler、Ooize等,用于保证调度系统的性能和稳定性。
|
|
Azkaban |
DolphinScheduler |
Ooize |
|
任务类型 |
Shell脚本及大数据任务 |
Shell脚本及大数据任务 |
Shell脚本及大数据任务 |
|
多租户 |
不支持 |
支持 |
不支持 |
|
权限控制 |
粗粒度 |
细粒度 |
粗粒度 |
|
易用性 |
高 |
高 |
中 |
|
任务暂停 |
不支持 |
支持 |
支持 |
技术选型:Azkaban简单易用、可以快速上手;DolphinScheduler更符合中国人的使用习惯;Ooize功能完善、成熟度高。
- 大数据底层基础技术:主要指的是Zookeeper。Zookeeper是一个开源的分布式协调服务,主要用于数据订阅/发布,集群管理,配置管理,分布式锁。大数据技术组件中的HBase、Hadoop、Kafka等的运行都会用到Zookeeper。
- 数据检索:在选择全文检索引擎工具时候,一般包括Lucene、Solr和Elasticsearch。
- Lucene是apache下的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。
- Elasticsearch 是一个开源的、高扩展性的分布式全文检索引擎,能够近乎实时地存储、检索数据。它是 Elastic Stack 的核心,集中存储您的数据,提供快速搜索、精细调整的相关性和强大的分析能力。
- Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。
|
|
Elasticsearch |
Solr |
Lucene |
|
社区活跃度 |
高 |
中 |
中 |
|
扩展性 |
高 |
中 |
低 |
|
集群运维难度 |
低 |
高 |
不支持集群 |
|
易用性 |
高 |
高 |
低 |
|
稳定性 |
高 |
高 |
中 |
- 大数据集群安装管理框架:一个完整的大数据平台往往包括数据采集、数据存储、数据计算、数据分析、集群监控等功能,那就意味着会包含很多组件。如果由运维人员一个个单独安装每一个组件,那么工作量会非常巨大。所以国外一些厂商就对大数据组件进行了封装,这样就能快速部署大数据组件。目前行业中常见的是CDH、HDP、CDP等等。

- CDH:( Cloudera Distribution Hadoop )是 Cloudera 公司提供的包含 Apache Hadoop 及其相关项目的软件发行版本。还有一种说法是 CDH 是 Cloudera Distribution including Apache Hadoop 的缩写。CDH默认是30天的试用期,之后继续使用会收费。
- HDP:是Hortonworks公司的代表产品,是一个企业级的Hadoop发行版。HDP属于开源免费大数据平台。
- CDP:(Cloudera Data Platform)是 CDH 的继任者。CDP 是面向企业的云计算平台。它提供集成的多功能自助服务工具,以分析和集中数据。它是将CDH和HDP中比较优秀的组件融合在一起,同时增加一些新的功能,形成一个新的平台。
那随着CDH和HDP的合并以及商业发行版的闭源,越来越多的公司选择Apache Hadoop开源社区版,进行自研统一管理、统一调度以及统一安全认证。

开源社区版本其实有两个大分支,一个是Hadoop 2.X版本,一个是Hadoop 3.X版本。目前仍有大部分的公司,使用的是2.X版本,因为已经很稳定了,但是一些新技术却很难优化。而Hadoop在3.X版本之后,使用了相对比较新的架构,具备更好的水平扩展能力,以及滚动升级能力。
以上就是当前大数据组件生态圈的简单介绍。大数据技术由于在各行各业的应用场景和巨大的市场需求,得到了广泛的关注及重视。目前大数据技术已经取得了比较显著的成果,而且未来发展前景也很广阔。在不久的将来,希望大数据技术不断突破和创新,为社会发展提供核心力量。
