


一、背景
近些年大模型发展情况:
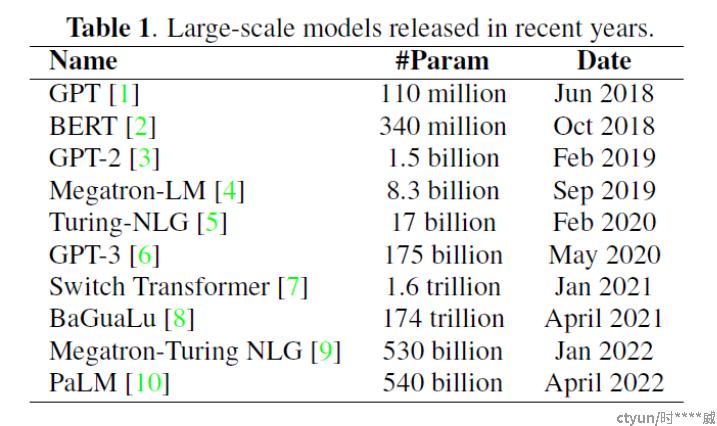
通常而言,深度学习模型的参数量越大,模型的非线性拟合能力越强。
- 模型越大,模型的表现越好
- 模型越大,模型的下游任务适应能力越强
但随着模型参数量的增大,模型的训练也成为重要的问题,具体表现如下:
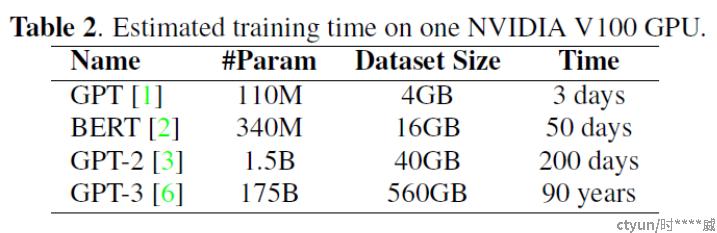
- 大模型在单卡上的理论训练时长过长
- 单台显卡的显存无法装入整个大模型
- 由于显卡架构问题,显卡通信成本并非随着显卡数量增高而线性增加
二、分布式训练框架
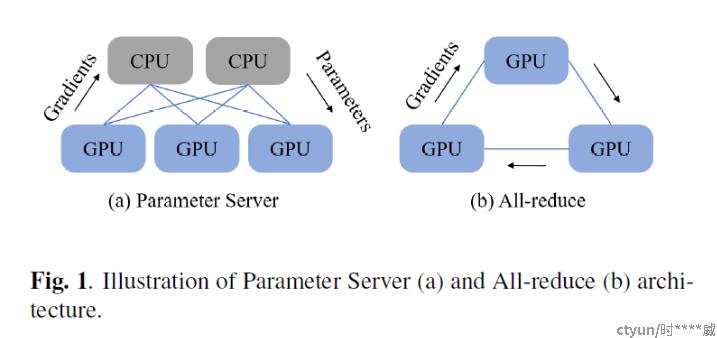
- Parameter Server (PS)[1]:worker和ps,worker在GPU上,负责模型的前向和反向传播,PS在CPU上运行,并接收GPU worker计算的梯度,更新模型参数,而后GPU worker从PS上拉取新的模型参数进行新一轮训练
- All-reduce[2]:仅使用GPU,各GPU间独立计算梯度,而后同步各显卡间的梯度计算结果。
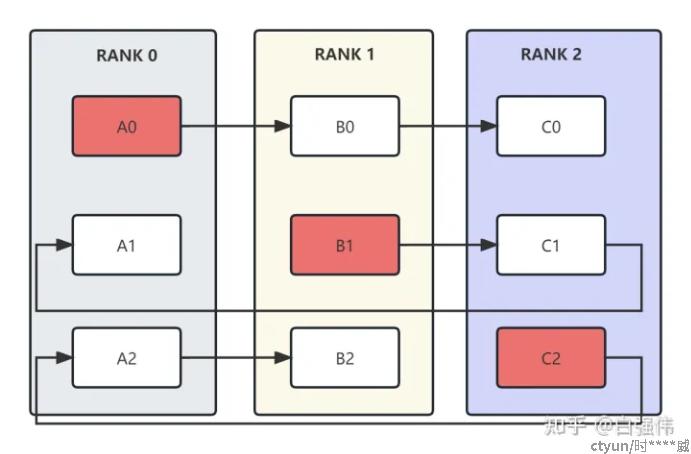
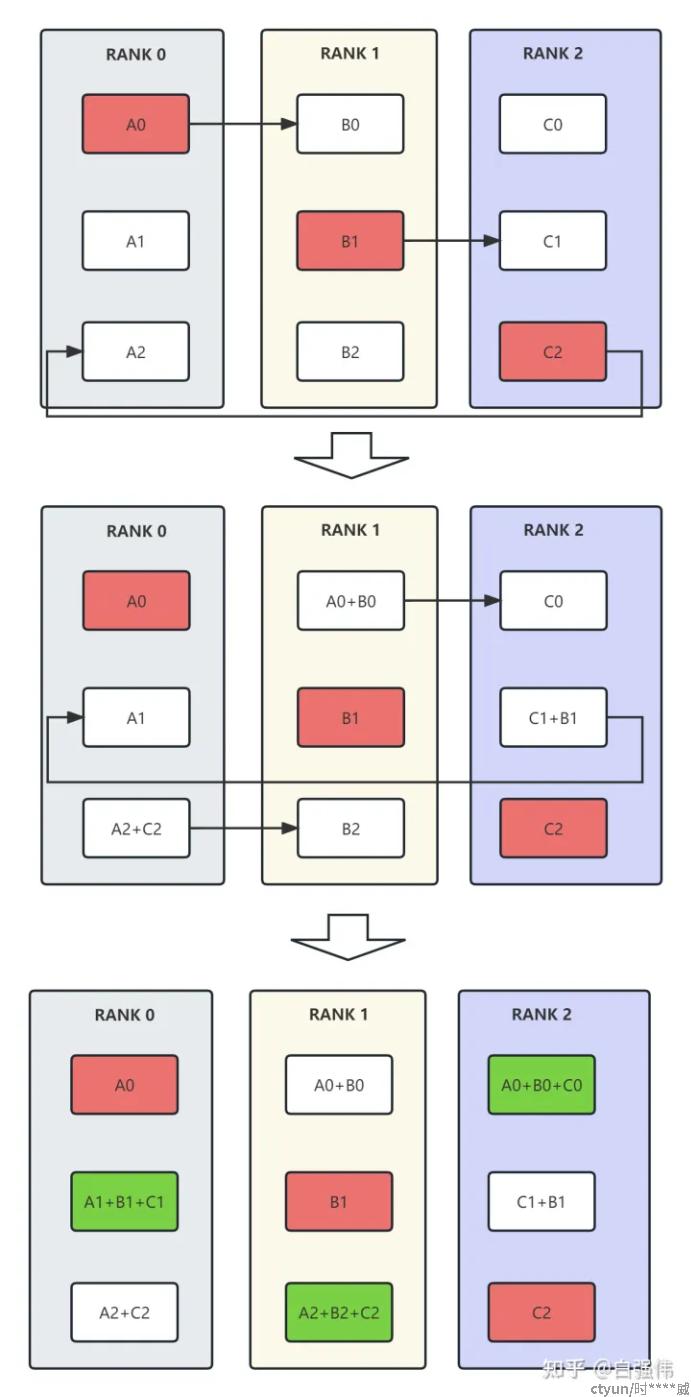
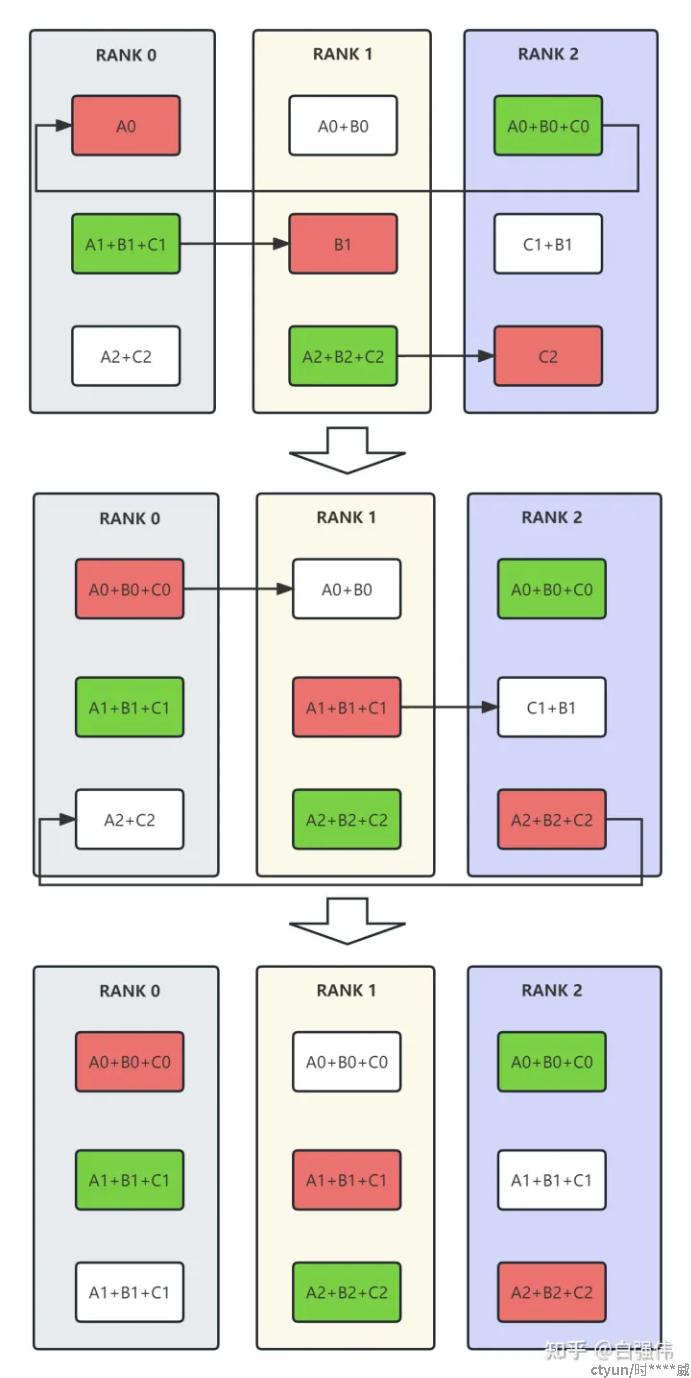
同步方法中最典型的方法为ring all-reduce,即环状all-reduce。ring all-reduce共分为reduce-scatter和all-gather两个步骤[3]。
三、训练并行方法
大模型并行训练过程主要分为训练数据读取,前向计算、反向传播、多卡通信和参数更新几步(slice data loading, forward pass, backward pass, set communication, and parameter update),从训练流程上分类,共分为如下几个方法:
- 数据并行(Data Parallelism, DP):不同显卡采用不同的数据并行计算
- 流水线并行(Pipeline Parallelism, PP):将前向和反向传播过程中的不同模型层装入不同显卡中并行计算
- 张量并行(Tensor Parallelism,TP):将模型同一层中的张量分解后装入不同的显卡中并行计算
数据并行中根据同步与异步区分,又分为以下三种:
- Bulk Synchronous Parallel (BSP)[4]:每轮训练后,各显卡同步梯度更新模型后继续下一轮训练,缺点:通信过程中各显卡需空闲等待。
- Asynchronous Parallel (ASP)[5]:各显卡单独训练,缺点:各显卡训练时使用的权重非最新权重,会降低训练效率,有研究表明其达到相同效果的训练时长相比BP并不会减少[6]。
- . Stale Synchronous Parallel (SSP):各显卡单独训练,并适时通信以获取近期新版本权重(不一定是最新),属于BSP和ASP的平衡[7]。
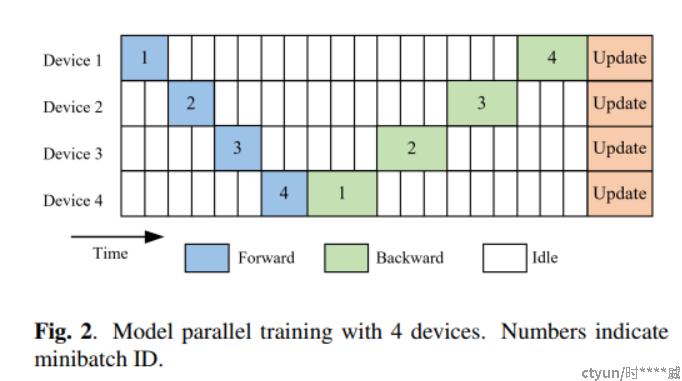
流水线并行则是将模型训练过程以流水线的形式在不同显卡间并行进行。
一般而言,不考虑流水线情况下,多卡并行训练模型的时间片分布如下:
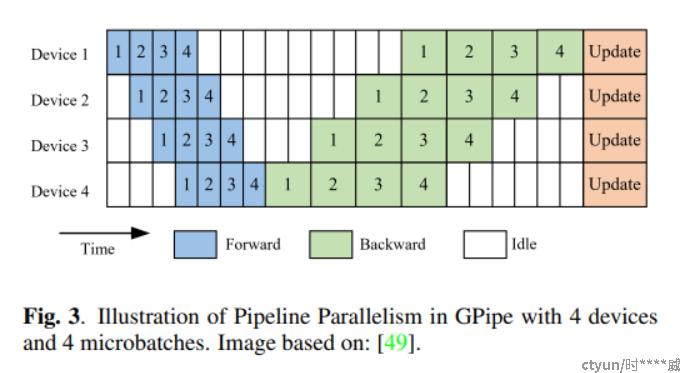
GPipe的流水线情况下,多卡并行训练模型的时间片分布如下:
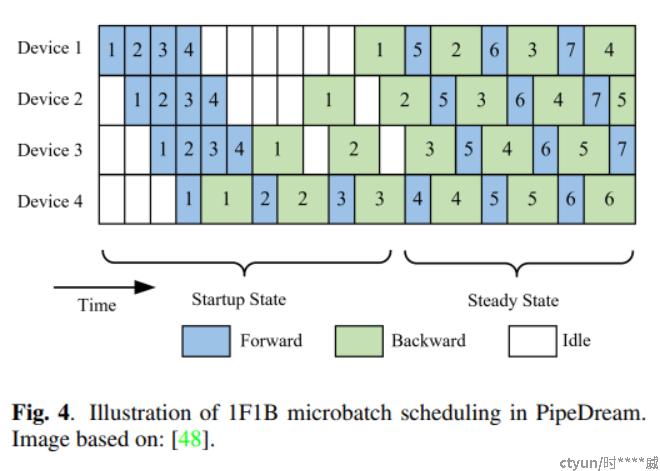
1F1B的流水线情况下,多卡并行训练模型的时间片分布如下:
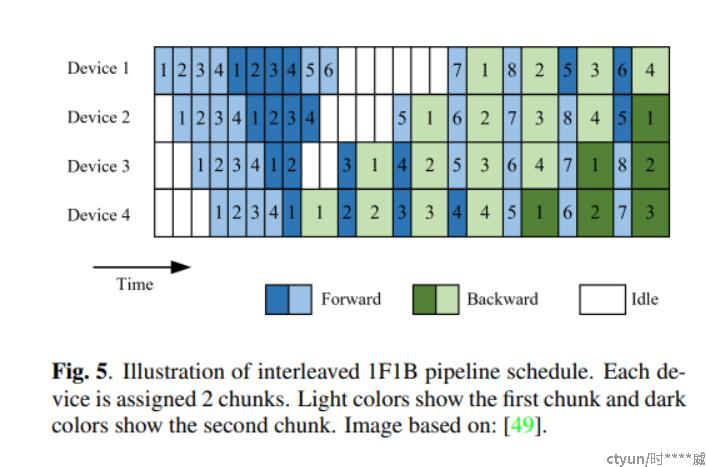
interleaved 1F1B的流水线情况下,多卡并行训练模型的时间片分布如下:
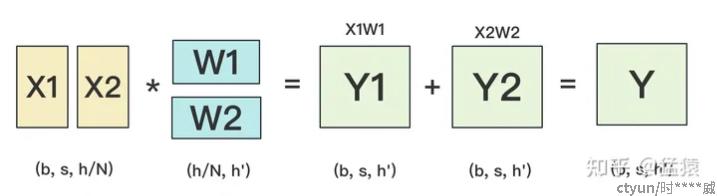
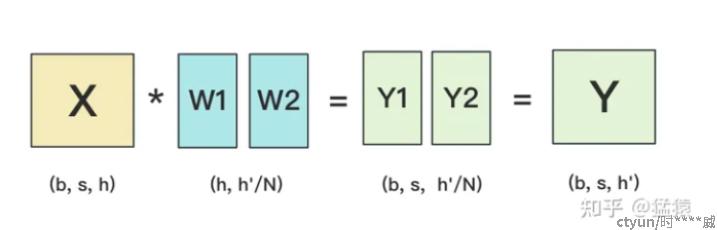
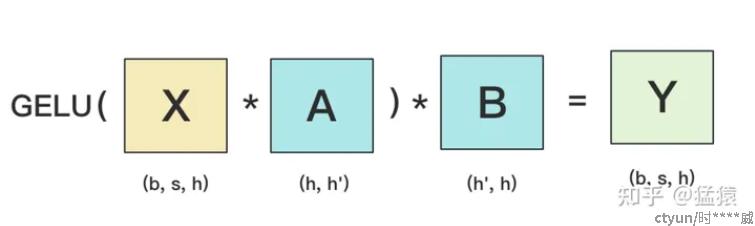
张量并行: 利用矩阵相乘的性质,将模型中的某个张量参数进行分解,装入不同的显卡中进行训练,主要分为按行切分张量和按列切分张量两种[8]。
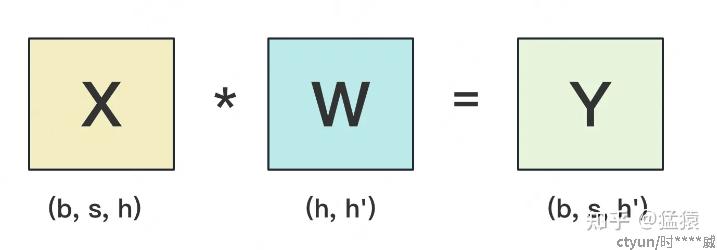
- b:batch_size,表示批量大小
- s:sequence_length,表示输入序列的长度
- h:hidden_size,表示每个token向量的维度。
- h':参数W的hidden_size。
按行切分张量:
前向传播
反向传播
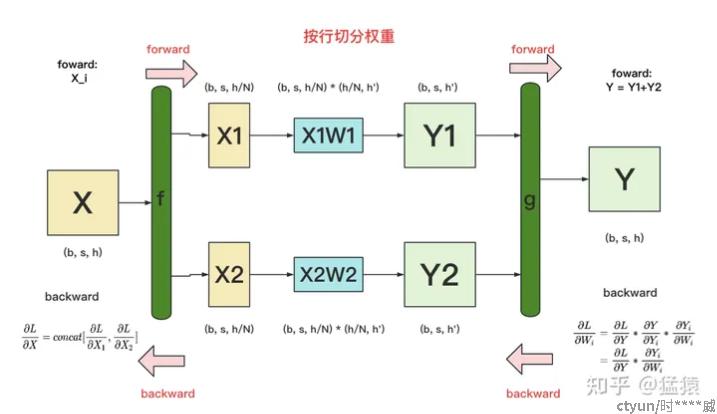
按列切分张量:
前向传播:
反向传播:
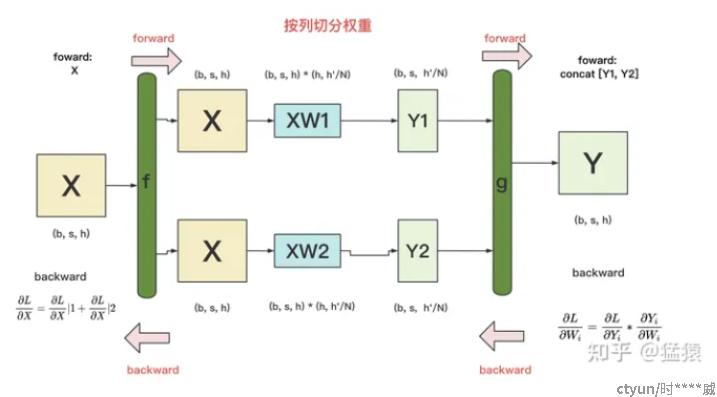
四、典型大模型并行训练方法
这里首先介绍混合精度训练方法及显存占用分析[9]:
假设有一个参数量为 Ψ 的模型,并使用Aadm作为优化器。首先,由于模型的参数和梯度使用float16,那么显存的消耗分别是 2Ψ 和 2Ψ 。Aadm会维护一个float32的模型副本,则会消耗 4Ψ 。此外,根据上面介绍的Aadm优化器,Adam需要为每个参数维护两个状态变量 v 和 r 。由于 v 和 r 均是float32,所以显存占用则为 4Ψ+4Ψ 。总的来说,模型会消耗 2Ψ+2Ψ=4Ψ 的显存,Aadm优化器则消耗 4Ψ+4Ψ+4Ψ=12Ψ 的显存。最终,总的显存消耗为 4Ψ+12Ψ=16Ψ
此外训练过程中的显存消耗还包括以下三种:
- 激活(Activations):前向传播过程中的中间状态,常用的解决方法是gradient/activation checkpointing,该方法在前向传播过程中,有选择性的丢弃一些产生的中间激活值,当反向传播需要使用这些激活值时,再依据上一个保存的激活值来计算出这些需要的激活值来帮助完成反向传播。
- 临时缓存区(Temporary buffers):显卡通信buffer等
- 显存碎片
DeepSpeed-ZeRO:
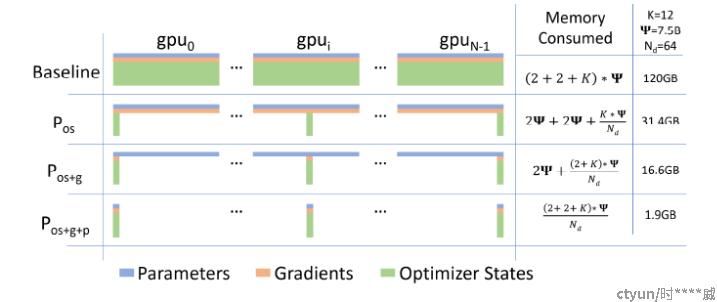
ZeRO是在数据并行的情况下对显卡显存进行的优化,具体包含三个阶段[10][11]:
- Pos:优化器状态划分
- Pg:梯度划分
- Pp:参数划分
显存占用和通信量分析:
- Pos:显存占用为模型参数和梯度,大量显卡训练,优化器状态分散不计的情况下占用为4Ψ;通信量为梯度的all-reduce,共计2Ψ
- Pos+Pg:显存占用为模型参数,大量显卡训练,优化器状态和梯度分散不计的情况下占用为2Ψ,通信量为梯度的逐层all-reduce,共计2Ψ
- Pos+Pg+Pp:大量显卡训练情况下,理论上模型参数、梯度和优化器状态均可忽略不计,ZeRO可适用于任意大模型
ZeRO-R[12]:
- 激活函数:在前向传播计算完成激活函数之后,对把激活值丢弃,由于计算图还在,等到反向传播的时候在此计算激活值,算力换内存。或者采取一个与cpu执行一个换入换出的操作。
- 临时缓冲区:模型训练过程中经常会创建一些大小不等的临时缓冲区,比如对梯度进行AllReduce啥的,解决办法就是预先创建一个固定的缓冲区,训练过程中不再动态创建,如果要传输的数据较小,则多组数据bucket后再一次性传输,提高效率。
- 内存碎片:显存出现碎片的一大原因是时候gradient checkpointing后,不断地创建和销毁那些不保存的激活值,解决方法是预先分配一块连续的显存,将常驻显存的模型状态和checkpointed activation存在里面,剩余显存用于动态创建和销毁discarded activation复用了操作系统对内存的优化,不断内存整理。
ZeRO-Offload/ZeRO-Infinity[13][14]:
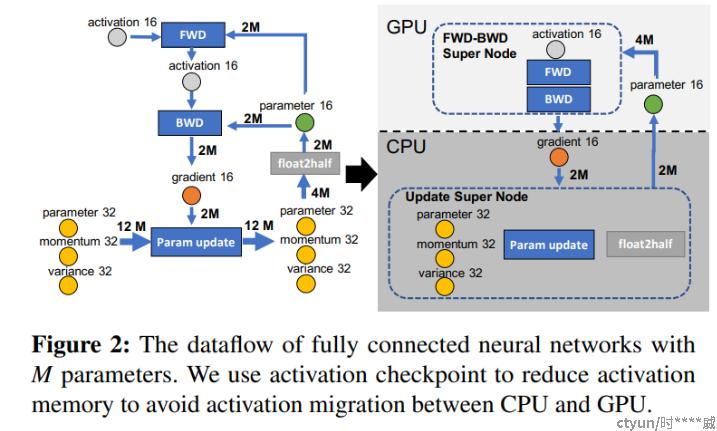
类似前文提到的PS并行训练框架,将参数更新部分放入CPU的内存中进行,以达到节省显存的目的。
Megatron-LM[15]:主要采用张量并行方法实现大模型并行训练,此处主要以transformer中的MLP层和Self-Attention层为例介绍。
MLP层:对A采用“列切割”,对B采用“行切割”
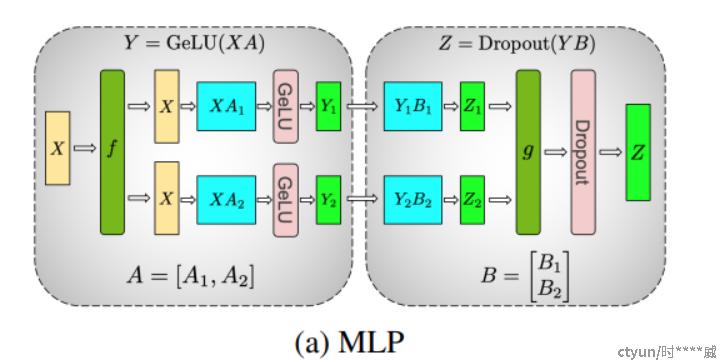
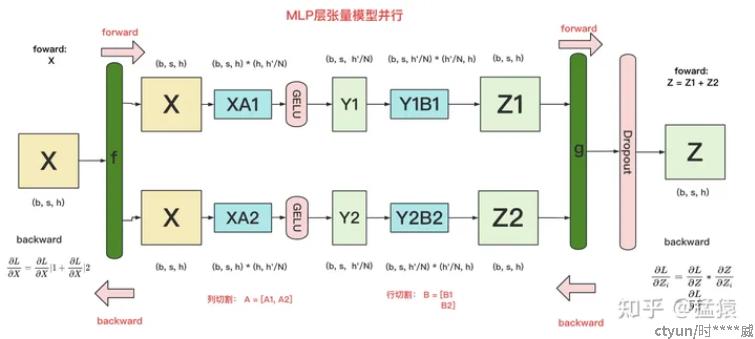
在前向传播过程中,需对结果Zi进行相加得到最终结果Z,需要进行一次AllReduce,在反向传播过程中,需将误差对Xi的偏导进行相加得到误差对X的偏导,需要进行一次AllReduce。
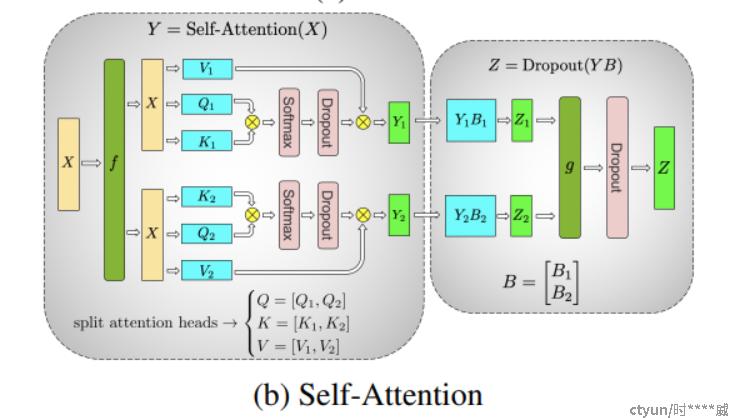
Self-Attention层:对V、Q、K进行列切分,对B进行行切分,通信流程同MLP层
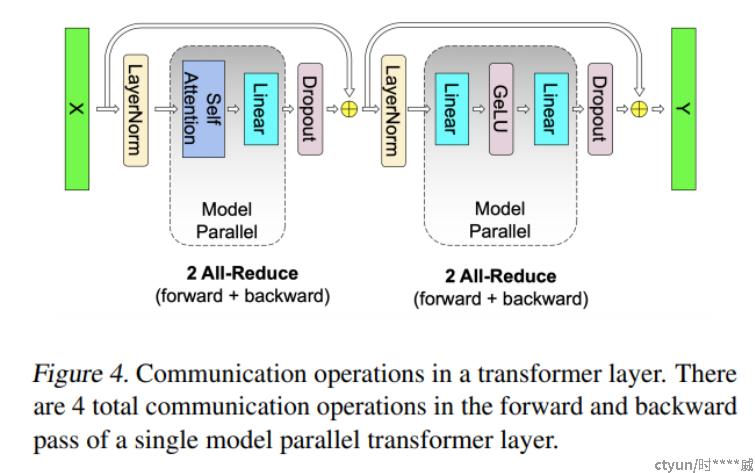
总结来说:一个transformer中的主要通讯如下图,共需4个All-Reduce过程
五、显存优化方法
- gradient/activation checkpointing:舍弃部分激活层数据,反向传播时重新计算
- CPUOffload:将部分GPU显存offload至CPU内存上
参考文献:
[1]M. Li, D. G. Andersen, A. J. Smola, and K. Yu, “Communication efficient distributed machine learning with the parameter server,” Advances in Neural Information Processing Systems, vol. 27, 2014.
[2]P. Patarasuk and X. Yuan, “Bandwidth optimal all-reduce algorithms for clusters of workstations,” Journal of Parallel and Distributed Computing, vol. 69, no. 2, pp. 117–124, 2009.
[3]知乎专栏:手把手推导Ring+All-reduce的数学性质
[4] L. G. Valiant, “A bridging model for parallel computation,” Communications of the ACM, vol. 33, no. 8, pp. 103–111, 1990.
[5]A. Ahmed, M. Aly, J. Gonzalez, S. Narayanamurthy, and A. J. Smola, “Scalable inference in latent variable models,” in Proceedings of the fifth ACM international conference on Web search and data mining, 2012, pp. 123–132.
[6]J. Chen, X. Pan, R. Monga, S. Bengio, and R. Jozefowicz, “Revisiting distributed synchronous sgd,” arXiv preprint arXiv:1604.00981, 2016.
[7]Q. Ho, J. Cipar, H. Cui, S. Lee, J. K. Kim, P. B. Gibbons, G. A. Gibson, G. Ganger, and E. P. Xing, “More effective distributed ml via a stale synchronous parallel parameter server,” Advances in neural information processing systems, vol. 26, 2013.
[8]知乎专栏:图解大模型训练之:张量模型并行(TP),Megatron-LM
[9]知乎专栏:【深度学习】混合精度训练与显存分析
[10]知乎专栏:【深度学习】【分布式训练】DeepSpeed:AllReduce与ZeRO-DP
[11]Rajbhandari S, Rasley J, Ruwase O, et al. Zero: Memory optimizations toward training trillion parameter models[C]//SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020: 1-16.
[12]CSDN专栏:Zero系列三部曲:Zero、Zero-Offload、Zero-Infinity
[13]Rajbhandari S, Ruwase O, Rasley J, et al. Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning[C]//Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 2021: 1-14.
[14]Ren J, Rajbhandari S, Aminabadi R Y, et al. {ZeRO-Offload}: Democratizing {Billion-Scale} model training[C]//2021 USENIX Annual Technical Conference (USENIX ATC 21). 2021: 551-564.
[15]Shoeybi M, Patwary M, Puri R, et al. Megatron-lm: Training multi-billion parameter language models using model parallelism[J]. arXiv preprint arXiv:1909.08053, 2019.
