原文: Transparent Page Placement for CXL-Enabled Tiered-Memory
链接: (这里贴链接无法通过审核, 所以需要自行搜索)
1 Background & Motivation
CXL内存池化技术的介绍可以参考相关专栏文章(这里贴链接无法通过审核, 所以需要自行搜索)
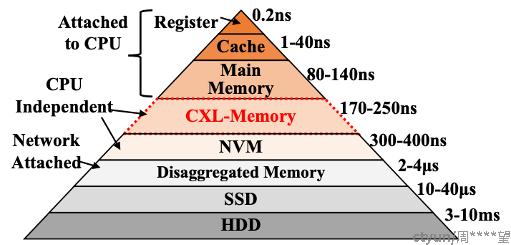
现有完整的存储分级金字塔如图所示. 越靠近塔尖的存储介质具有更高的延迟, 而越靠近塔底的存储介质具有更大的容量.
随着CXL内存的出现, 在主存(本地内存)之外多出来了一种延迟没有增加太多, 但容量巨大的新内存. 如何能够用好这部分内存成为了一个重要问题.
Meta公司在2022年给出了一个方案: TPP(Transparent Page Placement, 透明页放置). 核心是将应用程序的内存页分为冷页和热页, 将冷页沉降到延迟更高的CXL内存, 将热页提升到延迟更低的本地内存, 从而在几乎不影响应用程序内存读取速度的前提下, 大幅提升可用内存总量.
为什么这种内存页放置的方法可行? 是基于以下统计结论:
1.页温度: 大部分被应用访问过的页在几分钟内都是冷页, 可以被沉降到更慢的内存层级中;
2.不同类型的页温度: 大部分匿名页是热页, 而文件页在短期内相对要冷一些;
3.不同类型的页随时间使用情况: 根据应用情况不同, 但都有规律
1.Web应用: 刚启动时大量使用文件页, 随后匿名页增多, 文件页下降;
2.Cache应用: 主要使用文件页, 且比例稳定;
3.数据仓库任务: 主要使用匿名页, 且比例稳定.
4.页类型对性能的影响: 根据应用情况不同, 原理见3
5.页被重复访问的间隔: 根据应用情况不同, 但都有规律
1.Web/Cache应用: 10分钟内大部分冷页会被再次访问;
2.数据仓库任务: 大部分匿名页都是新建的, 只有少部分会再次访问.
因此, 通过不同层级的内存页放置, 可以提升资源利用效率
2 Design
TPP的框架设计本身很简单, 而且都是利用已有的技术. 围绕冷页沉降与热页提升主要有四大核心内容:
2.1 页温度检测
论文中列举了好多种方法, 最后TPP选择的是:
1.对CXL-Memory使用NUMA Balancing, 在下次访问的时候触发一次缺页异常;
2.对本地memory使用Linux已有的LRU方法.
据说这样可以做到几乎0消耗检测到大部分热页.
2.2 轻量级内存回收
在本地内存中通过LRU选择了待沉降的内存页后, 不是通过swap机制, 而是通过异步的迁移任务转移到CXL内存中, 比swap快多了.
2.3 分配与回收解耦
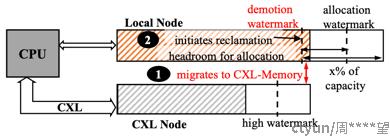
不同于目前主存发现存储不足后先回收然后分配的逻辑, TPP为了避免本地内存回收跟不上分配的速度, 导致更多页被分配进CXL内存, 在本地内存中额外维护了一部分空闲页.
简单地说也就是靠LRU多迁移一点内存页到CXL内存, 给本地内存多留点了buffer, 确保未来新的内存页都优先从主存上分配.
2.4 从CXL内存中提升内存页
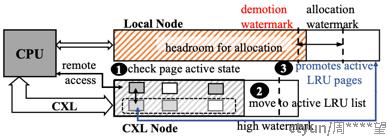
在CXL内存中使用NUMA Balancing方法.
但在设置page fault之前, 先借助LRU检查选择到的是不是不活跃的页, 如果是不活跃的则不设置. 因此避免冷页被提升.
3 Evaluation
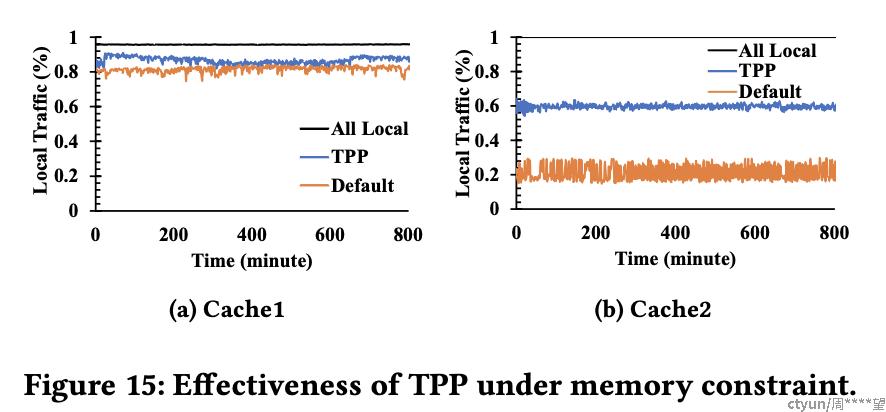
经过实验, TPP的内存页访问更加集中在本地内存上, 因此访问延时也更低.
本地内存 : CXL内存 = 2 : 1 时的情况如下

本地内存 : CXL内存 = 1 : 4 时的情况如下