


DataX 简介
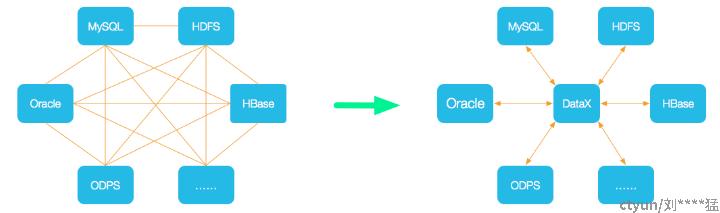
DataX 是 DataWorks 数据集成 的开源版本,主要就是用于实现数据间的离线同步。 DataX 致力于实现包括关系型数据库(MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等 各种异构数据源(即不同的数据库) 间稳定高效的数据同步功能。
-
为了 解决异构数据源同步问题,DataX 将复杂的网状同步链路变成了星型数据链路 ,DataX 作为中间传输载体负责连接各种数据源; -
当需要接入一个新的数据源时,只需要将此数据源对接到 DataX,便能跟已有的数据源作为无缝数据同步。
DataX3.0 框架设计
DataX 采用 Framework + Plugin 架构,将数据源读取和写入抽象称为 Reader/Writer 插件,纳入到整个同步框架中。
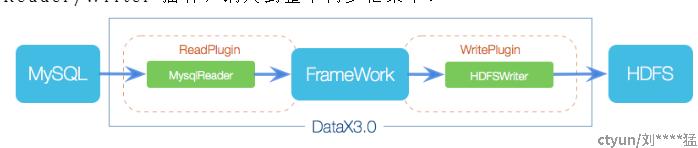
DataX 完成单个数据同步的作业,我们称为 Job,DataX 接收到一个 Job 后,将启动一个进程来完成整个作业同步过程。DataX Job 模块是单个作业的中枢管理节点,承担了数据清理、子任务切分、TaskGroup 管理等功能。

-
DataX Job 启动后,会根据不同源端的切分策略,将 Job 切分成多个小的 Task (子任务),以便于并发执行。 -
接着 DataX Job 会调用 Scheduler 模块,根据配置的并发数量,将拆分成的 Task 重新组合,组装成 TaskGroup(任务组) -
每一个 Task 都由 TaskGroup 负责启动,Task 启动后,会固定启动 Reader -->Channel-->Writer 线程来完成任务同步工作。 -
DataX 作业运行启动后,Job 会对 TaskGroup 进行监控操作,等待所有 TaskGroup 完成后,Job 便会成功退出(异常退出时 值非 0 )
DataX 调度过程:
-
首先 DataX Job 模块会根据分库分表切分成若干个 Task,然后根据用户配置并发数,来计算需要分配多少个 TaskGroup; -
计算过程: Task / Channel = TaskGroup,最后由 TaskGroup 根据分配好的并发数来运行 Task(任务)
使用 DataX 实现数据同步
DataX 基本使用
查看 streamreader \--> streamwriter 的模板:
python /usr/local/datax/bin/datax.py -r streamreader -w streamwriter
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}
根据模板编写 json 文件
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [ # 同步的列名 (* 表示所有)
{
"type":"string",
"value":"Hello."
},
{
"type":"string",
"value":"河北彭于晏"
},
],
"sliceRecordCount": "3" # 打印数量
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "utf-8", # 编码
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "2" # 并发 (即 sliceRecordCount * channel = 结果)
}
}
}
}通过 DataX 实 MySQL 数据同步
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader", # 读取端
"parameter": {
"column": [], # 需要同步的列 (* 表示所有的列)
"connection": [
{
"jdbcUrl": [], # 连接信息
"table": [] # 连接表
}
],
"password": "", # 连接用户
"username": "", # 连接密码
"where": "" # 描述筛选条件
}
},
"writer": {
"name": "mysqlwriter", # 写入端
"parameter": {
"column": [], # 需要同步的列
"connection": [
{
"jdbcUrl": "", # 连接信息
"table": [] # 连接表
}
],
"password": "", # 连接密码
"preSql": [], # 同步前. 要做的事
"session": [],
"username": "", # 连接用户
"writeMode": "" # 操作类型
}
}
}
],
"setting": {
"speed": {
"channel": "" # 指定并发数
}
}
}
}编写 json 文件:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123123",
"column": ["*"],
"splitPk": "ID",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"
],
"table": ["t_member"]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8",
"table": ["t_member"]
}
],
"password": "123123",
"preSql": [
"truncate t_member"
],
"session": [
"set session sql_mode='ANSI'"
],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}-
上面的方式相当于是完全同步,但是当数据量较大时,同步的时候被中断,是件很痛苦的事情; -
所以在有些情况下,增量同步还是蛮重要的
使用 DataX 进行增量同步
使用 DataX 进行全量同步和增量同步的唯一区别就是:增量同步需要使用 where 进行条件筛选。
编写 json 文件:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123123",
"column": ["*"],
"splitPk": "ID",
"where": "ID <= 1888",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"
],
"table": ["t_member"]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8",
"table": ["t_member"]
}
],
"password": "123123",
"preSql": [
"truncate t_member"
],
"session": [
"set session sql_mode='ANSI'"
],
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "5"
}
}
}
}-
需要注意的部分就是: where(条件筛选) 和preSql(同步前,要做的事) 参数。
验证:
python /usr/local/data/bin/data.py where.json输出
2022-12-16 17:34:38.534 [job-0] INFO JobContainer - PerfTrace not enable!
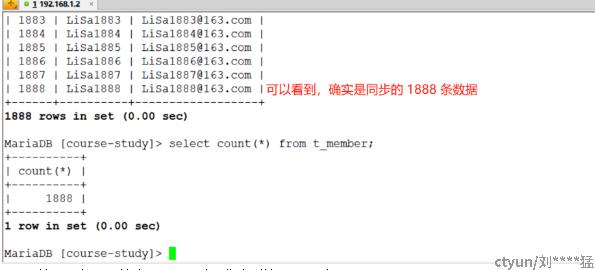
2022-12-16 17:34:38.534 [job-0] INFO StandAloneJobContainerCommunicator - Total 1888 records, 49543 bytes | Speed 1.61KB/s, 62 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.002s | All Task WaitReaderTime 100.570s | Percentage 100.00%
2022-12-16 17:34:38.537 [job-0] INFO JobContainer -
任务启动时刻 : 2021-12-16 17:34:06
任务结束时刻 : 2021-12-16 17:34:38
任务总计耗时 : 32s
任务平均流量 : 1.61KB/s
记录写入速度 : 62rec/s
读出记录总数 : 1888目标数据库上查看:
基于上面数据,再次进行增量同步:
主要是 where 配置:"where": "ID > 1888 AND ID <= 2888" # 通过条件筛选来进行增量同步
同时需要将我上面的 preSql 删除(因为我上面做的操作时 truncate 表)