


什么是集合通信?
集合通信本质上是一群进程之间的通信(communication that involves a group of processes),既然是一群进程之间的通信,
那就存在以下几种情况,即一对一,一对多,多对一,多对多。
集合通信提供了各种不同的操作,用于进程和进程之间的消息互通:
Broadcast
Scatter
Gather
All gather
Reduce
All reduce …
集合通信原语介绍:
1 Broadcast
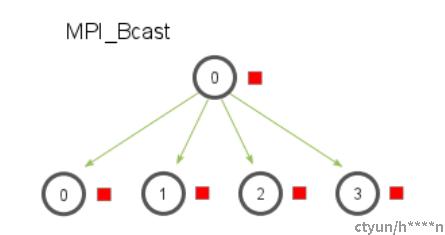
Broadcast广播操作,把一个进程的数据广播到其他进程上,发送广播操作的进程一般称之为根进程(root),
操作完毕后,其他所有进程都得到了root进程的数据。
2 Scatter
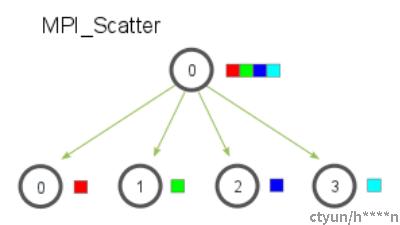
scatter操作中,root进程把数据均分,把各部分数据分发到不同进程上面去。注意,scatter操作中,其他进程得到的只是root进程中数据的一部分。
3 Gather
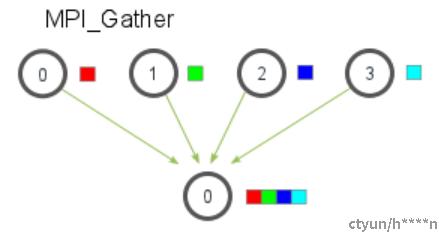
Gather操作中,不同进程的数据汇集到root进程上,最终root进程得到了其他所有进程的数据。
4 All Gather

All Gather操作中,不同进程的数据汇集到所有进程中 ,最终所有进程都拥有了其他所有进程的数据。
5 Reduce
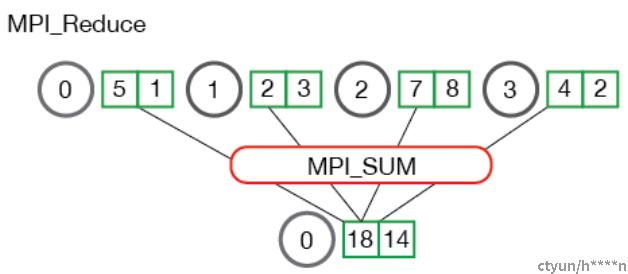
Reduce操作中,在每个进程上获取一组数据,获取所有进程上的数据后并作SUM,MAX,AVE等相应操作 。最终操作的结果汇聚到root进程上。
6 AllReduce
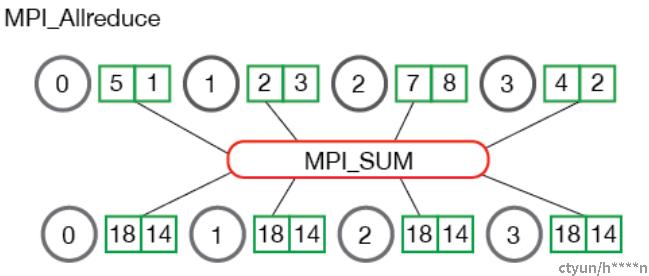
All Reduce操作,其实就是把最终的Reduce操作再分发到其他各个进程上去,其实就是Reduce+Broadcast。
集合通信在分布式AI场景中的应用:
All reduce操作是分布式AI场景中最常用到的操作。
AI分布式训练的核心是并行计算:数据并行,模型并行。 这两者都需要用到All reduce操作同步每一个节点上的数据 。
以数据并行为例:
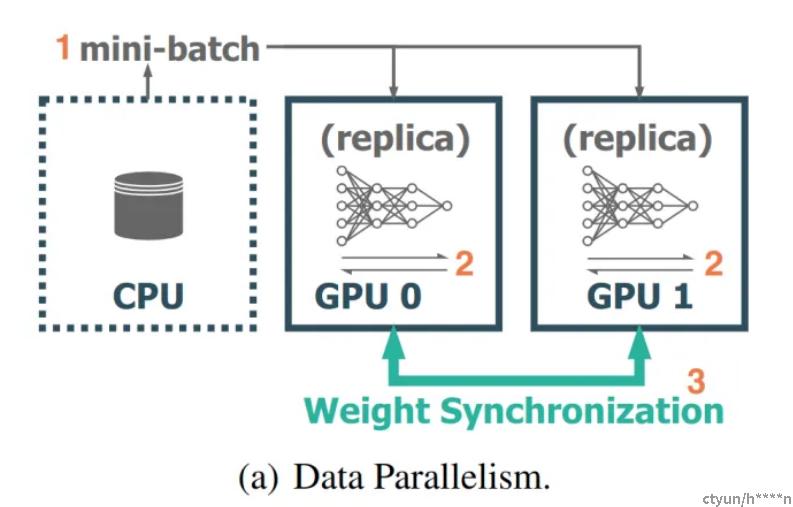
1 把数据进行切分,一部分数据由 GPU0训练,一部分数据由GPU1训练。
2 GPU0和GPU1的数据作并行计算,并行地做前线计算和反向传播。每个GPU上的AI模型是完全一致的。
3 每个GPU单独更新自己的权值参数。于是需要做一次all-reduce,汇总所有权值参数做平均。保证每个GPU上的模型权值参数是一致的。
不断地前向计算,反向传播,集群做All-reduce更新模型地权值参数,最终当模型达到收敛时,我们就得到了最终我们想要的AI模型。
All Reduce操作:
All reduce最终要保证每个节点上的数据是一致的。最简单的做法就是先reduce,再broadcast
参数服务器:
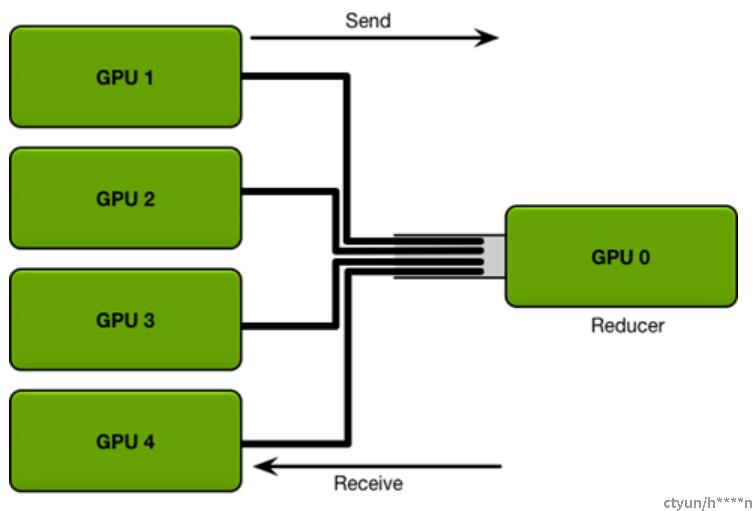
参数服务器(parameter server) 参数服务器将数据分成N份分到各个服务器上(Scatter),每个服务器负责自己的那一份mini-batch的训练,得到梯度参数grad后,返回给参数服务器上做Reduce,得到更新的权重参数后,再广播给各个卡(broadcast) 缺点:节点数一多,参数服务器带宽就受限,成为瓶颈。
论文:Li M, Andersen D G, Park J W, et al. Scaling distributed machine learning with the parameter server[C]//11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14). 2014: 583-598.
Ring Allreduce:
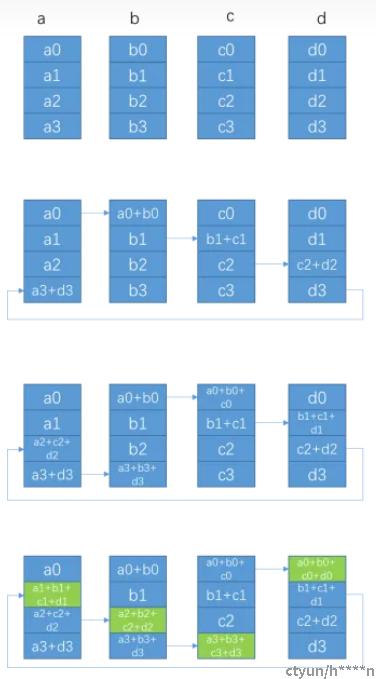 -------->
-------->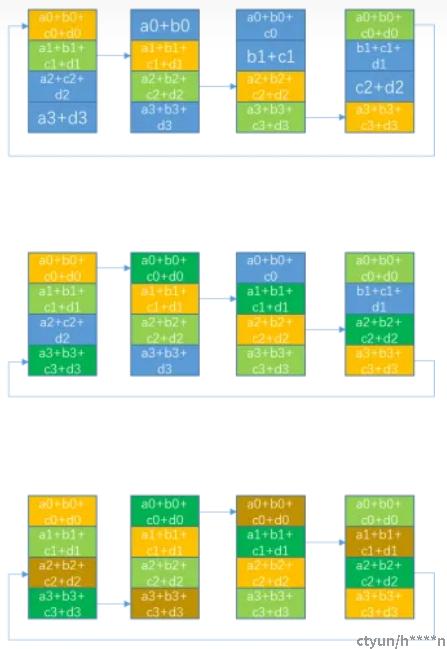
Ring all reduce算法中,所有的节点构成一个环
如上图所示:a,b,c,d可以认为是一台机器上四块不同的GPU,
1 Ring All Reduce中将所有的GPU构成一个Ring环,每个GPU上将数据进行切分,切分为多个Chunk, 切分的数量为Ring环中GPU的数量。
2 Ring All Reduce主要分为两个步骤,第一个步骤是scatter-reduce操作,第二个步骤是All-gather操作。
3 第一步scatter-reduce操作中一共有N-1步(N是Ring环中GPU的数量),每次每个GPU接收和发送的数据量都是K/N(K是每个GPU上的数据量的大小)。所以scatter-reduce环节中每个GPU发送和接收的数据总量是(N-1)* K/N。
4 第二步All-gather操作中共有N-1步,每次每个GPU接收和发送的数据量都是K/N(同scatter-reduce中一样)。所以All-gather环节中中每个GPU发送和接收的数据总量是(N-1)* K/N。
5 综上,Ring All reduce环节中,每个GPU接收和发送的数据总量是2(N−1)*K/N。可以看到,随着GPU数量N的增加,每个GPU发送和接收的数据总量约为2K ,和GPU数量无关,数据量几乎是恒定的。
优点:充分利用发送带宽和接受带宽。不会有某一台节点成为通信瓶颈 缺点:随着节点数增多,ring变得越来越大,延迟增加
论文:Gibiansky A. Bringing HPC techniques to deep learning[J]. Baidu Research, Tech. Rep., 2017.
