


1、什么是布隆过滤器
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。主要用于判断一个元素是否在一个集合中。
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢。这个时候,布隆过滤器(Bloom Filter)就应运而生。
2、布隆过滤器原理
BloomFilter 是由一个固定大小的二进制向量或者位图(bitmap)和一系列映射函数组成的。
在初始状态时,对于长度为 m 的位数组,它的所有位都被置为0,如下图所示:

当有变量被加入集合时,通过n 个映射函数将这个变量映射成位图中的n 个点,把它们标记为 1。假定设置3个映射函数func1、f2、f3,有两个变量k1、k2加入集合,标记结果如下:
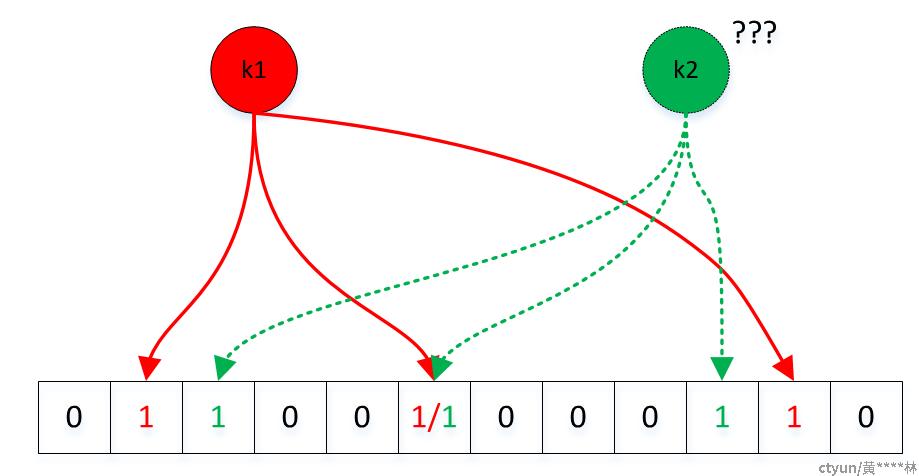
其中第6位是k1、k2共用的标记位。
如果一个变量对应的n个点中有任何一个 0,则被查询变量一定不在。
当一个变量对应的n个点中都为1时,则被查询变量是不是一定存在呢?请看下图:
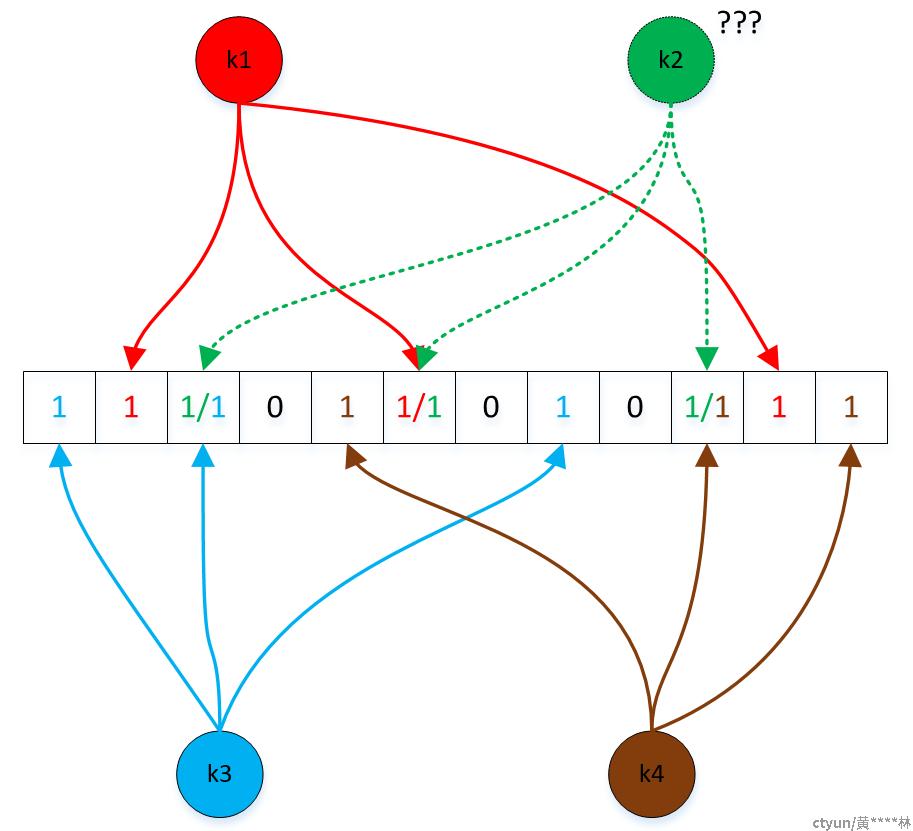
k2的3个标记位分别被k1、k3、k4共用,如果k1、k3、k4都加入了集合,k2被判断为存在,可能是一种误判。所以结论是:
- 如果一个变量对应的n个点中有任何一个 0,则被查询变量一定不存在。
- 如果一个变量对应的n个点都是1,则被查询变量可能存在。
减少误判率的方法是增大m和n。当然,考虑到性能,也不是越大越好,要根据实应用场景选择合适的大小。
3、布隆过滤器使用场景
布隆过滤器被广泛应用:
数据库防止穿库:避免对不存在的行或列进行磁盘查找。
文章推荐:判断用户是否读过某篇文章。
WEB拦截器:如果相同请求则拦截,防止重复被攻击。
排重:判断一个数据是否已经被处理过,如果被判断为已经处理过时才需要进一步求真,提高排重效率。
4、布隆过滤器变种
在降低误算率方面,人们进行了不少工作,使得出现了很多布隆过滤器的变种,比如:
- Counting Bloom Filter:原始的bloom filter不支持删除操作,CBF通过对位数组进行扩展,把原来1位扩展为t位用于计数。每次存储时将对应k个hash下标的位计数+1,删除时相应的对k个hash下标计数-1,从而支持集合删除操作。
- Partial Bloom Filter:原始bloom filter的hash函数值的范围是0~m-1,即整个位数组的下标范围,而在PBF中每个hash函数的取值范围较小,相互间没有交集,位数组被分成k个区域,每个hash函数值负责一个区域。好处是准确率比原始的高,且可以并行访问数组,优化程序性能。
- Compressed Bloom Filter:对原始的bloom filter进行压缩,用于网络传输应用。好处是经过压缩的bloom filter的错误率更低、所需位数更少、所需hash函数更少。
