


虚拟机迁移加速技术背景
虚拟机迁移技术能够将虚拟机从一台物理服务器迁移到另一台物理服务器。在云计算环境中,通过虚拟机迁移技术提高云数据中心服务器的资源利用率,达到节能和负载均衡的目的。
热迁移开始前,虚机在源主机运行,迁移开始后会在目的主机创建虚机并将其状态设置为暂停,源源不断地接受源端发送的内存数据,直到源端剩余内存量足够小,最后暂停源端,将剩余的内存一次性拷贝目的主机。
对于业务程序繁忙的虚机,迁移过程中业务程序会产生大量内存脏页,这类虚机迁移能否成功的关键点在于迁移拷贝脏页的速率大于产生脏页的速率。为满足这样的条件,业界提出了许多迁移加速算法,包括auto-converge,compression,multifd,xbzrle等等。
虚拟机迁移加速技术路线选择
- auto-converge:核心思想是减小脏页产生速率。通过减少虚拟机vCPU运行时间从而降低虚机脏页产生速率,使其小于迁移拷贝速率以满足迁移收敛条件。优点:任何虚拟化场景都适用且有效。缺点:限制虚机脏页产生地同时也限制了虚机的CPU运行时间,虚机的计算性能在迁移过程中也随之下降。
- compression:核心思想是压缩减少迁移传输数据量。通过在拷贝数据前压缩数据量而间接增大单位时间内迁移拷贝的数量以满足迁移收敛条件。缺点:在计算资源充足且内存带宽优先的情况下适用,应用场景有限。
- xbzrle:核心思想是压缩迁移时传输的增量数据。利用CPU cache缓存要压缩的增量数据从而间接增大迁移传输速率以满足收敛条件。缺点:在虚机增量数据多为稀疏类型的情况下适用,应用场景有限。
- multifd:核心思想是在迁移时建立多个传输通道。通过迁移时并发传输的数量从而间接增大迁移传输速率以满足迁移收敛条件。缺点:在没有最大化利用迁移带宽的场景下适用,应用场景有限。
auto-converge由于不受场景限制且可以有效降低虚机脏页速率,成为了主流的迁移加速配置,但auto-converge由于无法确定虚机中产生脏页的vCPU,在方案实现时采用较激进的方式将所有虚机vCPU都限制运行以达到降低脏页速率的目的,虚机中并不产生脏页的读vCPU也成为了“受害者”,导致性能下降。天翼云通过充分的技术论证,基于intel PML硬件机制,借助内核dirty ring特性,提出了软硬结合的vCPU速率检测和限制方法,作为DirtyLimit的核心技术,最终解决迁移过程中读vCPU性能下降的问题。
DirtyLimit技术介绍
DirtyLimit核心思想与auto-converge相同,都是通过减少虚拟机vCPU运行时间从而降低虚机脏页产生速率。但在具体实现上则采用了完全不同的底层技术以克服auto-converge使虚机vCPU性能下降的缺点。因此DirtyLimit除了具有传统auto-converge的优点外,还弥补了它的不足,使得DirtyLimit具备更广泛被使用的潜质和推广场景。
DirtyLimit与auto-converge技术对比如下:
- 限制脏页产生的方式:auto-converge与DirtyLimit相同,都通过减少虚拟机vCPU运行时间来实现。区别在于,auto-converge为“主动型”,hypervisor主动采样数据判断迁移收敛情况,如果不收敛会“主动”限制vCPU运行时间。DirtyLimit为“被动型”,利用硬件提供的脏页速率监测机制,速率限制会在脏页速率大于阈值时“被动”触发。对比两种策略,auto-converge因为要“主动”采样计算,因此计算资源开销更大,而且采样计算到速率限制有一定延迟,导致虚机脏页速率限制较为“迟钝”。DirtyLimit则没有上述缺点,“被动”地触发速率限制,没有计算资源开销,对限制也更“灵敏”,能够更快地开始速率限制,从而减少虚机迁移时间。
- 脏页限制的粒度:auto-converge对于脏页限制的粒度为整个虚机的所有vCPU,因此无论vCPU是否产生脏页,都会被hypervisor“盲目”地限制,从而使不产生脏页速率的读进程也成为“受害者”,计算性能随之下降。相比而言,DirtyLimit只针对脏页速率大于阈值的vCPU,不仅速率限制的粒度更小,限制策略更灵活,而且对不产生脏页的vCPU不做速率限制,从而使读进程不受hypervisor速率限制的影响,迁移过程中读进程所在vCPU的计算性能几乎接近正常运行的vCPU计算性能,相比auto-converge,DirtyLimit迁移在读vCPU计算性能方面有明显提升,有效降低对用户业务的影响。
对比测试结果
迁移时间对比测试结果
表1:迁移时间对比的3种测试环境
|
测试环境 |
主机配置 |
虚拟机配置 |
软件环境 |
|
1 |
CPU:8378A 32C 3.0GHz 内存:1024GB 网卡:千兆 |
CPU: 2 内存:8G |
OS:ctyunos2.0 libvirt: 8.2.0 qemu: 7.1 kernel: 5.10 |
|
2 |
CPU:2650 32C 2.00GHz 内存:192GB 网卡:万兆 |
CPU: 2 内存:8G |
|
|
3 |
CPU: 2650 32C 2.00GHz 内存:192GB 网卡:万兆 |
CPU:8 内存:32G |
图1 3种测试环境虚机迁移时间对比
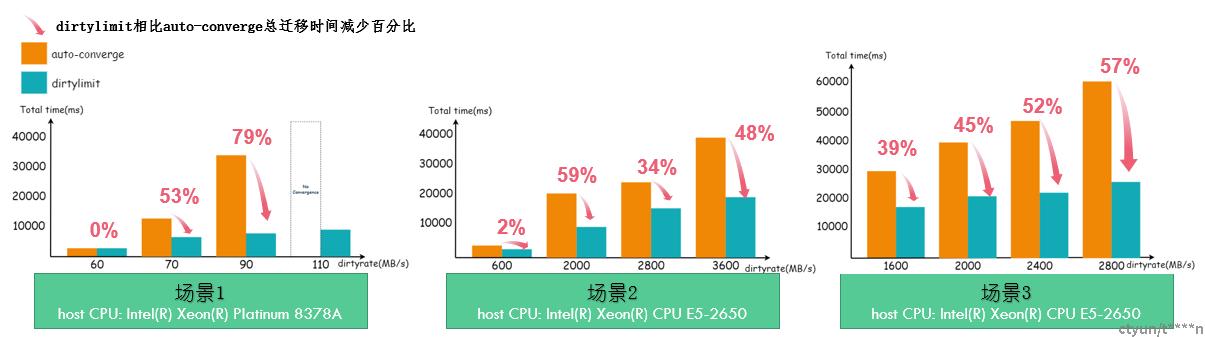
从实际测试数据中可以看到:
- 随着虚机脏页速率的增大,auto-converge相比DirtyLimit,迁移总时间差距会逐渐拉大。
- 对于带宽较小的场景如场景1,虚机脏页速率很大在极端情况下,auto-converge可能出现迁移失败情况。而DirtyLimit依然能保证虚机成功迁移。
vCPU计算性能对比测试
表2:vCPU测试环境
|
主机配置 |
虚机配置 |
软件环境 |
|
CPU: 8378A 32C 3.0GHz 内存:1024GB 网卡:千兆网卡 |
Cpu: 32 内存:8G |
OS: ctyunos2.0 libvirt: 8.2.0 qemu: 7.1 kernel: 5.10 |
测试方法:虚机内部分别绑核运行脏页产生程序和计算性能测试工具unixbench,脏页产生程序运行在0,1核,性能测试工具运行在8-15核(如图2所示),保证两个程序互不干扰。分别测试虚机在正常运行时间窗口、DirtyLimit迁移时间窗口、auto-converge迁移时间窗口三种场景下的unixbench跑分。
图2 测试模型

图3 迁移过程虚拟机性能对比
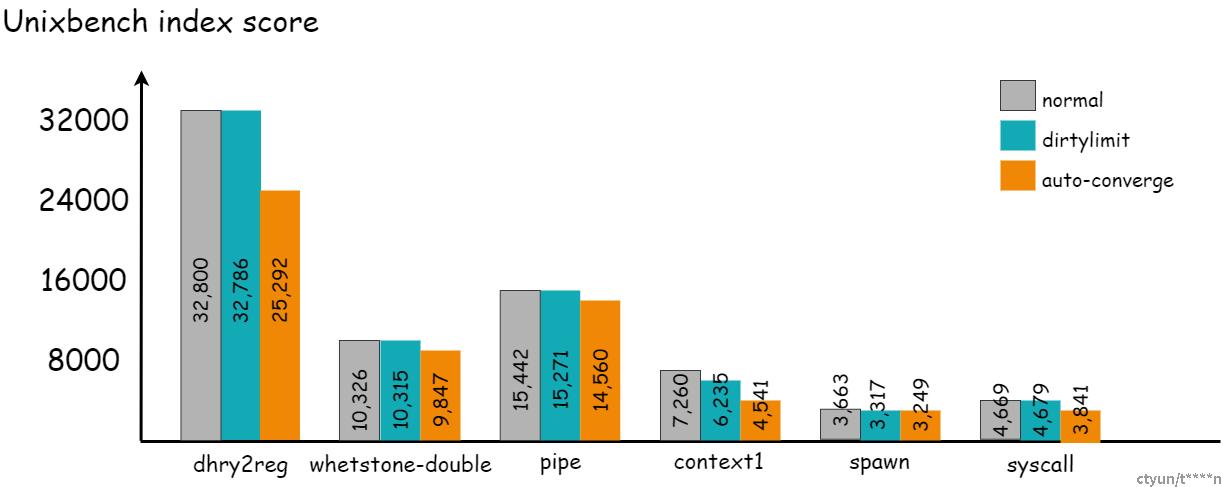
从测试结果可以看到,auto-converge迁移相比正常运行的虚机,计算性能下降相对明显,而DirtyLimit迁移的计算性能和正常运行虚机相比几乎没有下降。
后续工作
- 优化DirtyLimit脏页采集逻辑,提升迁移过程中虚机内存性能。
- DirtyLimit迁移特性实现代码同步至Libvirt,QEMU,以及欧拉社区。
主要参与者
- 天翼云研发一部基础架构团队
- 特别感谢 Qemu社区的maintainer,Peter,Markus,David在特性开发过程给予的方案建议,以及代码评审过程中给予的帮助。
