


1.背景
本文主要是讲解一下linux系统的cpu是怎么工作,怎么调度的。但是在整理文章的过程中,想起了本科时的电子c51单片机,就想着从原来的这些知识整理入手来让大家更好理解。linux的cpu调度。
既然是调度,可能还是要讲清楚: what, when, how. 什么是调度, 什么时候发起调度, 怎么调度的问题。
2. 单片机C51的中断
2.1 C51是什么?
C51就是如下这么个简单的小芯片,上面没有操作系统,20管脚接地,40管脚接5伏电源,然后18和19管脚接上12M晶振就能工作了。 然后以前本科的时候,用一个简单的代码烧录器就能将写好的C语言代码写进去,去控制这个芯片进行工作。
能实现什么效果尼? 例如 能让这个管脚电压为高(5v),就能点亮管脚对应的二极管。
可以参考这个百科
baike.baidu.com/item/51%E5%8D%95%E7%89%87%E6%9C%BA/5344633
2.2 C51的中断
2.2.0 中断是什么
中断其实就是在执行主代码逻辑的过程中, 跳出当前的代码段,去执行一个中断服务代码段, 执行完了然后回到跳出的位置继续执行的过程。
中断上下文: 代码位置点信息, SP, CP等寄存器数据
中断处理程序: interrupt_handler函数
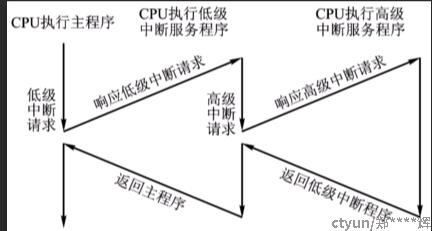
2.2.1 中断的种类
如下图,为C51这个单片机。
可能很多人看了这个图,会有晕不知道说的啥意思。我来总结一下,
a. 中断其实分为外部和内部中断,
* 外部中断就是INT0和INT1,它的发起源是来自芯片的12和13管脚。 怎么去触发这个外部中断尼? 可以往这个管脚接一个开关,另外一段接地。 按下开关,产生一个低电平,就能产生一个外部中断了。
* 内部中断(T0,T1,T2), 刚才说到C51单片机要外接一个12M的晶振, 也就是外部的这个晶振1秒能产生12M次电平波动,然后C51会将这个电平波动次数,存储在内部的寄存器里,然后代码去读取寄存器的值,当寄存器达到一定数值就会产生中断。
b.
2.2.2 中断优先级
中断优先级就是写死了这么几个。 也就是说,如果你正在执行T1中断的代码, 这个时候来了T0中断,是有可能触发二次中断嵌套的。
C51单片机最多允许2层的中断嵌套。
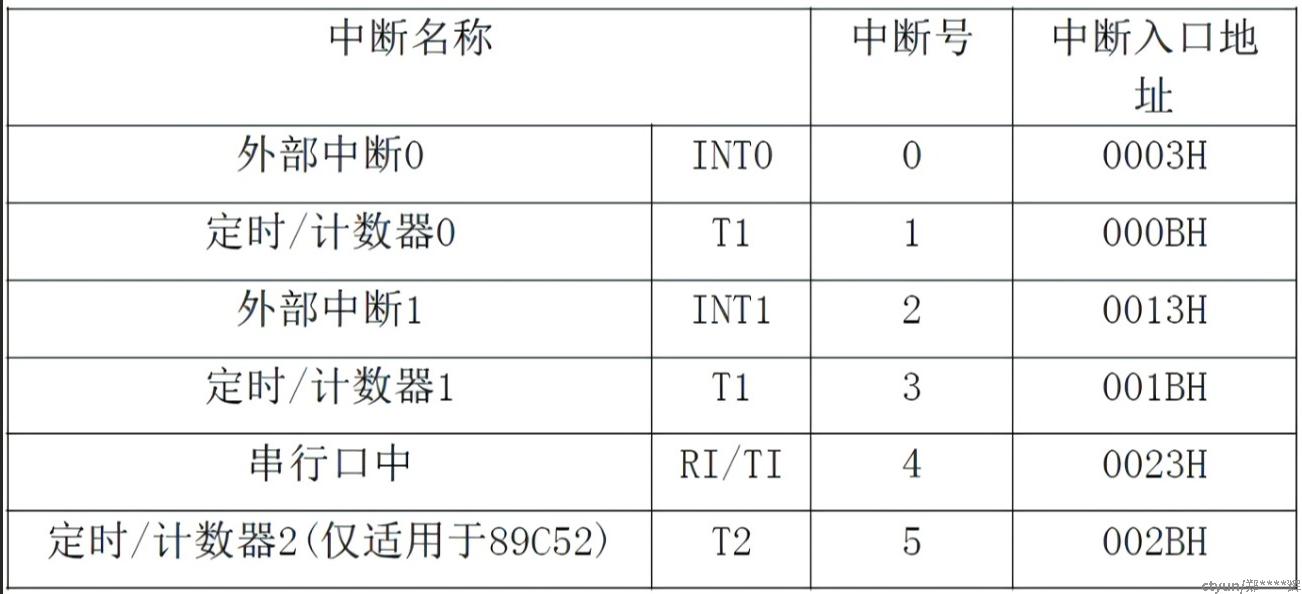
2.2.3 中断的用处
例如我希望去实现一个功能: 定时控制一个二进制管的开和关。
以12Mhz的晶振、定时10ms为例:
51单片机为12分频单片机,因此执行一条指令的时间是12×(1/12M) s,即计数器每1us加一。
若定时10ms,则共需要加10000次。
因此将TH0、TL0设置从(65536-10000)= 55536开始计数。55536 的16进制为0xD8F0。因此将TH0设置为0xD8,TL0 设置为0xF0。
#include <reg52.h>
#define uchar unsigned char
uchar num=0; //全局变量num
sbit led=P2^0;//p2.0口控制led灯
void main()
{
led=1;//led初始为亮
TMOD=0x01;
TH0=0xD8;//高四位
TL0=0xF0;//低四位,延时10ms
EA = 1;//打开总中断
ET0 = 1;//T1开,定时器溢出
TR0 =1;//开定时器
while(1)
{
if(num==10)//亮1秒
{
led=0;
}
if(num==20)//灭2秒
{
led=~led;
num=0;
}
}
}
void TR0_time() interrupt 1 //定时器中断函数
{
TH0=0xD8;//高四位
TL0=0xF0;//低四位,延时10ms
num++;
}
代码解读:
我们可以看到引入了一个reg52.h的c头文件,这个是封装了通过汇编去读取底层寄存器的接口,其实这些中断的计数器都是存储在寄存器里头, 寄存器有对应的地址的。 这里不详细展开,有兴趣的朋友可以去读一下汇编指令相关的文章。
2.3 小结
通过第二小节,我们知道了C51单片机中断的种类、中断优先级、中断的寄存器, 并且通过一个定时打开和关闭二极管的实例来讲解了中断的作用。
3. 从单片机中断到Linux操作系统
首先中断是针对单个处理核的,因为单片机是单核的,而linux的一般是多核的。
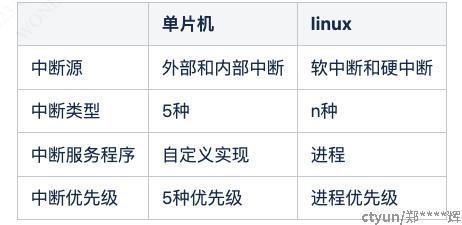
3.1 linux的中断

这里举一个例子:
内存缺页中断:
我们知道fork出来的进程,它是有独立的内存地址空间的, 但是它不是立刻产生和父进程一样大小的物理内存空间,而且Copy on write机制。
那么当子进程访问的内存空间,还没有copy完毕的时候,就会主动一个内存缺页错误中断: 来进行这个物理内存的拷贝完成,再回到子进程的流程就能进行对应的内存访问了。
3.2 中断和进程调度
中断描述表(interrupt descriptor table)(IDT)中记录了中断请求(IRQ)和中断服务程序(ISR)的对应关系。Linux 中定义了从 0 到 256 的 IRQ 向量。
和上面的C51单片机定时中断的基本逻辑一样, Linux也是有个Timer中断来驱动不断去执行不同的逻辑。 这个时间的中断注册到中断描述表, 是在Linux启动的时候去做的。
那么我们来看看Linux的时间中断处理流程:
跟随者Linux的代码脚印我们看看,时间中断是怎么去执行我们最后的hello world进程的。
void update_process_times(int user_tick)
{
scheduler_tick();
if (IS_ENABLED(CONFIG_POSIX_TIMERS))
run_posix_cpu_timers();
}
github.com/torvalds/linux/blob/631aa744423173bf921191ba695bbc7c1aabd9e0/kernel/time/timer.c#L2064
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
curr->sched_class->task_tick(rq, curr, 0); // 调度到哪个进程主要是看这里。
....
}
github.com/torvalds/linux/blob/93761c93e9da28d8a020777cee2a84133082b477/kernel/sched/core.c#L5498
这个sched_class是个什么东西尼?
- 它是定了一些接口的结构体
github.com/torvalds/linux/blob/bf57ae2165bad1cb273095a5c09708ab503cd874/kernel/sched/sched.h#L2164
- linux/kernel/sched目录下实现了若干个调度算法: stop,deadline, fair, rt, idel等调度算法, 这个是根据不同类型的进程选择不同的调度算法的
github.com/torvalds/linux/blob/bf57ae2165bad1cb273095a5c09708ab503cd874/kernel/sched/fair.c#L12375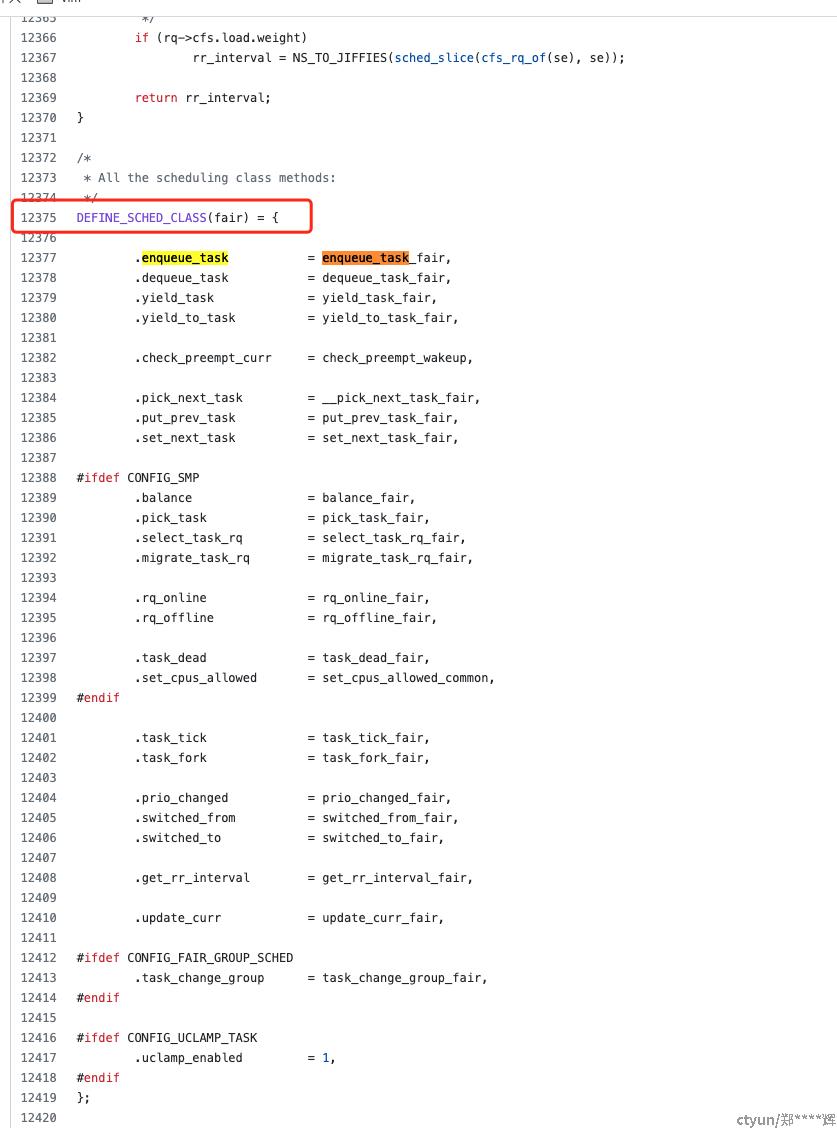
- 调度算法优先级
rt > dl > stop > fair > idle
3.1.3 如何查看linux的中断
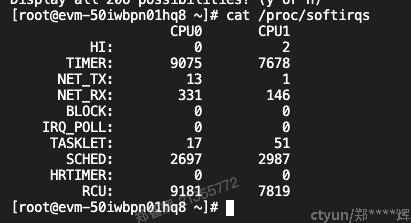
各个cpu发生中断类型和次数统计。
这里的TIMER就是时间中断。
3.1.4 /proc/irq
这个是系统里注册了多少个中断信号源。
可以给每个中断信号去设置指定处理的cpu。 每个信号下面的目录里smp_affinity。

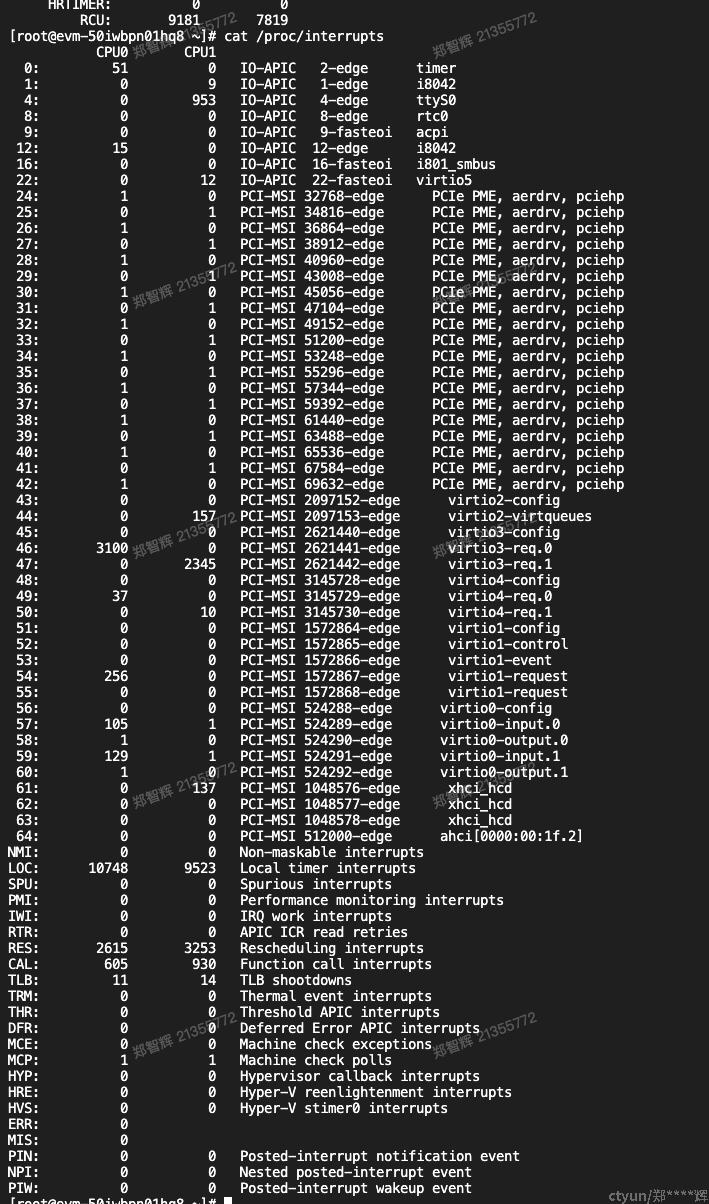
3.1.5 /proc/interrupts
irq编号,每个cpu对该irq的处理次数,中断控制器的名字,irq的名字,以及驱动程序注册该irq时使用的名字
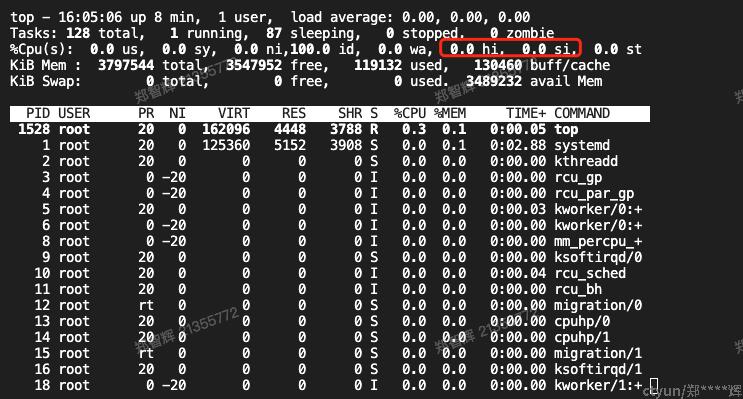
3.1.6 top命令
这里从top的输出可以看到:
- hi: 硬件中断
- si: 软件中断
- PR: 进程优先级, rt表示是实时进程。至于进程优先级=20,是个什么含义,暂时不在本文展开了。
- NI: 进程nice值
4. Linux的调度算法
好了,上面铺垫了半天,终于来到了调度算法。
在前面讲解了什么时候发起调度,调度的是什么实体之后,我们讲解一下怎么调度,也就是该执行哪个代码程序。 因为不像C51单片机,单核、中断数量那么小的处理。 Linux所处理的中断会复杂很多。
其实举个例子: 当你从键盘敲下Q, 然后文本编辑框显示一个Q,就是一个键盘的设备外部中断到对应的中断程序代码执行。
如果你按下Q,半天都没有执行这段显示Q的中断代码, 你在电脑前是不是会很崩溃, 啊, 我的天,怎么卡主了。 电脑你是不是坏了。
下面来看看这个调度算法的演进流程。
4.1 调度算法的基础
- 调度算法的原则
- 在1个cpu选择最优的task来运行。例如普遍认为io-bound task需要更好的优先级
- 没有饿死
- 调度速率
- 调度算法演进
- Linux 2.4: o(n)调度器
- Linux2.6较早版本: o(1)调度器
- Linux 2.6.23+: o(log n) CFS调度器
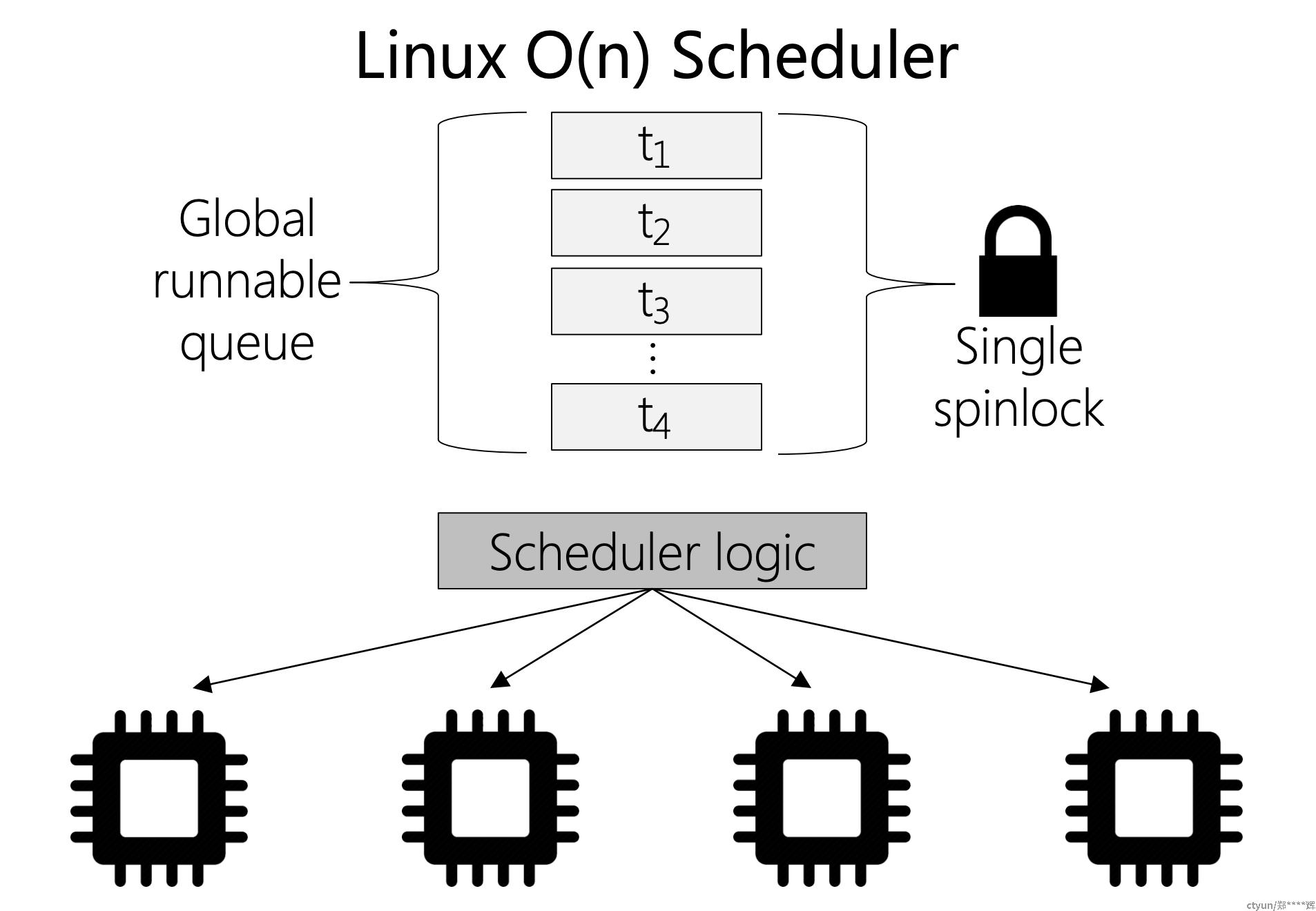
4.1 o(n) 调度算法
-
调度器基本架构
- 进程优先级:
- 2个静态优先级,进程的生命周期内都不会改变
- 实时优先级
- 实时任务: 1-99
- 普通任务: 0
- nice优先级
- 普通任务:0
- 人工调整: [-20,19], 可以通过nice命令进行调整
- 实时优先级
- 动态优先级
- time slice counter: 进程在调度过程中,
- 2个静态优先级,进程的生命周期内都不会改变
- 调度算法代码逻辑
-
schedule逻辑
void schedule(){ struct task_struct *next, *p; struct list_head *tmp; int this_cpu = ..., c; spin_lock_irq(&runqueue_lock); //Disable interrupts, //grab global lock. next = idle_task(this_cpu); c = -1000; //Best goodness seen so far. list_for_each(tmp, &runqueue_head){ // for 循环获取每个task p = list_entry(tmp, struct task_struct, run_list); if (can_schedule(p, this_cpu)) { // 判断这个task是否能在这个cpu运行,因为有些任务是绑核运行的 int weight = goodness(p); // 计算这个任务的权重 if(weight > c){ // 找权重最大的那个task c = weight; next = p; } } } spin_unlock_irq(&runqueue_lock); switch_to(next) // 跳转到对应任务 -
goodness逻辑
int goodness(struct task_struct *p){ if(p->policy == SCHED_NORMAL){ // 普通进程 //Normal (i.e., non-"real-time") task if(p->counter == 0){ // 如果这个进程已经用完了它对应的cpu时间就直接返回0 //Task has used all of its //time for this epoch! return 0; } return p->counter + 20 - p->nice; // 普通进程权重计算 }else{ // 实时进程 //"Real-time" task return 1000 + p->rt_priority; // 实时进程增加了1000,使得实时进程的权重肯定大于普通进程 //Will always be //greater than //priority of a //normal task } } - 总结
- 选择task需要o(n)时间复杂度
- 锁竞争: cpu从全局可运行队列取task的时候,有锁竞争
- 适合于单核的系统
-
4.2 o(1) 调度算法
-
架构图
-
每个cpu都有一个runqueue结构体
struct runqueue{ spinlock_t lock; struct task_struct *curr; prio_array_t *active; prio_array_t *expired;} struct prio_array{ unsigned int nr_active; struct list_head queue[MAX_PRIO]; unsigned long bitmap[BITMAP_SIZE]; }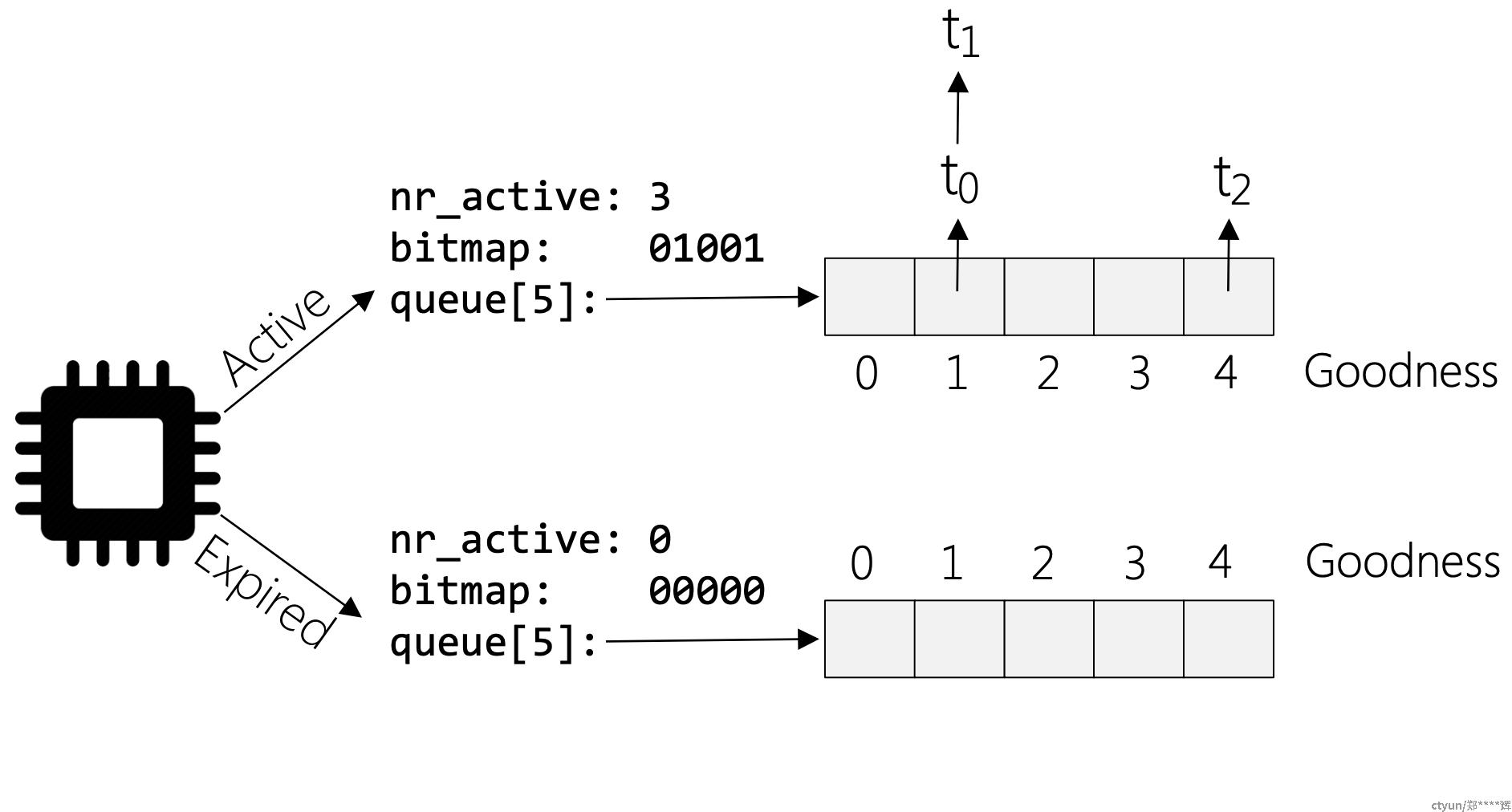
-
- 工作原理
-
schedule代码逻辑
void scheduler_tick(){ //Called by the timer interrupt handler. runqueue_t *rq = this_rq(); task_t *p = current; spin_lock(&rq->lock); if(!--p->time_slice){ 没有时间片了 dequeue_task(p, rq->active); p->prio = effective_prio(p); p->time_slice = task_timeslice(p); // 计算当前运行进程的剩余时间片 if(!TASK_INTERACTIVE(p) || // 不是交互式进程,就放到expired队列,就暂时不执行 EXPIRED_STARVING(rq)){ enqueue_task(p, rq->expired); }else{ //Add to end of queue. enqueue_task(p, rq->active); // 否则放到active队列尾部, } }else{ //p->time_slice > 0 // 如果是普通进程,就保持在对应的active队列进行执行 if(TASK_INTERACTIVE(p)){ //Probably won't need the CPU //for a while. dequeue_task(p, rq->active); enqueue_task(p, rq->active); //Adds to end. } } spin_unlock(&rq->lock); //Later, timer handler calls schedule(). } -
goodness
- 和o(n)调度器大同小异,就是给与实时进程一些bonus,让他获得更大的优先级
- cpu执行
- cpu从自己的active 队列里,根据bitmap来去queue的task来执行。
- 如果active队列为空,则将active和expired队列互换
- 继续第一步
-
- 总结
- 每个cpu都有自己的调度数据结构,避免的了全局锁
- 每一个调度优先级都有自己的数组,而且结合位图,可以实现o(1)的取task逻辑
- TASK_INTERACTIVE(p) 和EXPIRED_STARVING(rq)) 代码逻辑比较复杂
4.3 CFS 调度算法
- 目标
- 一个更加优雅的调度算法, o(1)算法有些地方实现台奇特了。
- 这个也是Linux作者的决策
-
调度算法主要逻辑
-
相比于o(1)的通过队列数组和bitmap来维护可运行task,cfs使用红黑树来存储
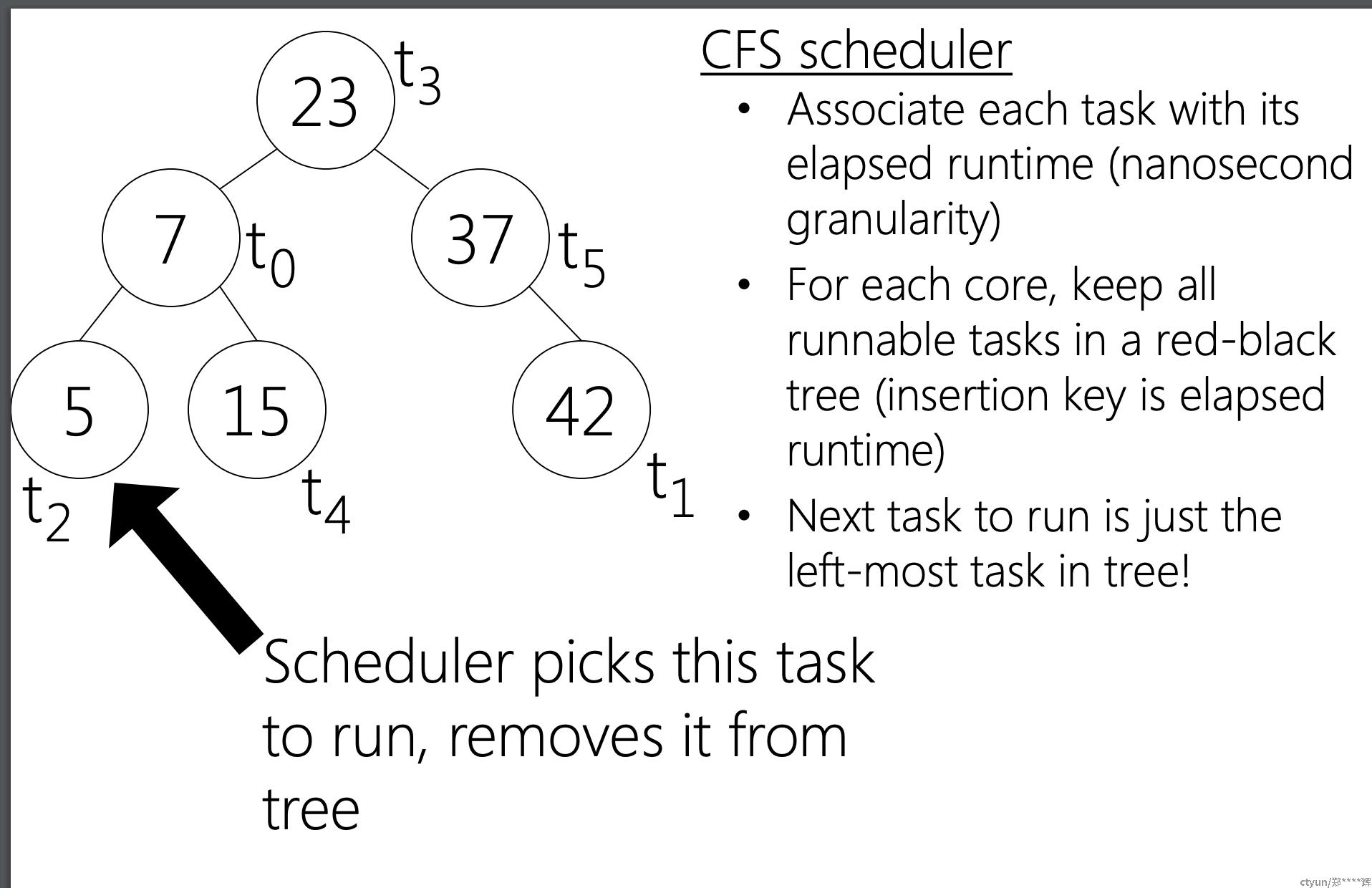
-
每次取最左边的task来进行运行。
-
-
红黑树优点
-
自均衡
-
在写入、删除、搜索都能保持 o(log N)
-
-
红黑树的key是virtual runtime
-
计算方法:
-
Nice值通过一个数组转换为weight
static const int prio_to_weight[40] = { /* -20 */ 88761, 71755, 56483, 46273, 36291, /* -15 */ 29154, 23254, 18705, 14949, 11916, /* -10 */ 9548, 7620, 6100, 4904, 3906, /* -5 */ 3121, 2501, 1991, 1586, 1277, /* 0 */ 1024, 820, 655, 526, 423, /* 5 */ 335, 272, 215, 172, 137, /* 10 */ 110, 87, 70, 56, 45, /* 15 */ 36, 29, 23, 18, 15, } -
计算vruntime公式
delta_exec = now - curr->exec_start; delta_exec_weighed = delta_exec * (NICE_0_LOAD / t->load.weight); curr->vruntime += delta_exec_weighted;
-
结果
-
nice=0, vruntime等于它的实际cpu执行时间
-
nice<0, vruntime会小于他实际cpu执行时间
-
nice>0, vruntime会大于它的实际cpu执行时间
-
这样子就能实现nice越小,就越优先调度了
-
-
-
-
- CFS总结
- 使用运行时间而不是时间片来衡量进程,粒度能去到纳秒
- 是否比o(1)更加好?
- 时间粒度更加细
- o(1) 看起来比o(log n)更加快
- vruntime会比time slice更加公平
- cfs也有很奇怪的地方,就是一直取最左task来运行,是否会让task失去 cache locality
5. 总结
本文首先通过C51单片机的中断和定时二极管功能代码实例,展示了C51的中断作用和运行机制; 然后讲解Linux的中断系统, 中断和进程调度的关系,讲解了当前Linux的几种调度算法实现。 最后深度讲解了Linxu的调度算法引进过程。
